IBM Granite 4.1开源模型:21个量化版本SVG生成实测对比
IBM发布Apache 2.0开源Granite 4.1模型,量化实验揭示模型规模比量化精度更重要
IBM发布了采用Apache 2.0许可证的Granite 4.1系列开源大模型(3B/8B/30B)。Simon Willison用"鹈鹕骑自行车"SVG生成任务测试了Unsloth提供的21种3B模型量化版本,发现不同量化级别间质量差异不明显且普遍表现糟糕。实验表明,3B参数模型在该任务上存在能力天花板,选择合适的基础模型规模比纠结量化精度更为关键。
IBM Granite 4.1:Apache 2.0开源大模型家族
IBM近日发布了Granite 4.1系列大语言模型,包含3B、8B和30B三个规格,全部采用Apache 2.0开源许可证。开发者可以自由地将其用于商业项目,这在当前开源模型生态中具有相当的吸引力。
Apache 2.0是开源软件领域最为宽松的许可证之一,允许用户自由使用、修改、分发软件,包括用于商业目的,且不要求衍生作品也必须开源。相比之下,Meta的Llama系列虽然常被称为"开源",但实际上采用的是自定义许可证,对月活超过7亿的企业有额外限制;Mistral的部分模型也曾使用限制商业用途的许可证。在当前大模型领域,真正采用Apache 2.0的高质量模型并不多见,这使得Granite 4.1在企业级应用场景中具有独特的法律合规优势,开发者无需担心许可证陷阱。
Granite团队成员Yousaf Shah在Hugging Face博客上详细介绍了该系列模型的训练过程。作为IBM在AI基础模型领域的重要布局,Granite 4.1延续了此前版本的技术路线,同时在性能和可用性上做了进一步优化。
Unsloth提供21种GGUF量化版本
在Granite 4.1发布后不久,知名模型优化团队Unsloth迅速推出了3B模型的GGUF格式量化版本集合(unsloth/granite-4.1-3b-GGUF),一共提供了21个不同的量化模型文件,大小从1.2GB到6.34GB不等,总计约51.3GB。
GGUF(GPT-Generated Unified Format)是由llama.cpp项目创始人Georgi Gerganov设计的模型存储格式,专门为CPU和混合CPU/GPU推理优化,是目前本地运行大模型最流行的格式之一,广泛用于llama.cpp、Ollama等推理框架。量化(Quantization)是将模型权重从高精度浮点数(如FP16,每个参数占2字节)压缩为低精度表示(如4-bit,每个参数仅占0.5字节)的技术。常见的量化级别包括Q2_K、Q4_K_M、Q5_K_M、Q8_0等,数字越大精度越高。不同的量化级别在模型大小和推理质量之间做出不同的权衡:更大的量化文件保留更多的模型原始能力,而更小的文件则牺牲部分精度换取更低的硬件门槛。
Unsloth团队以其高效的模型微调和量化工具闻名,他们提供的21个版本覆盖了从极致压缩到近乎无损的完整量化光谱,让开发者可以根据自己的硬件条件灵活选择。
鹈鹕骑自行车:一个经典的SVG生成测试
知名开发者Simon Willison看到这21个量化版本后,决定做一个他一直想尝试的实验:用同一个提示词测试同一模型的不同量化版本,观察输出质量的差异。
Simon Willison是Django Web框架的联合创始人,也是数据探索工具Datasette的作者。近年来他转型为AI工具领域最活跃的独立开发者和评论者之一,他的博客(simonwillison.net)被广泛认为是追踪LLM技术进展的最佳信息源之一。他开发的LLM命令行工具可以方便地调用各种本地和云端模型,这也是他能够快速对21个量化版本进行批量测试的技术基础。
他选择的提示词是经典的"Generate an SVG of a pelican riding a bicycle"(生成一只骑自行车的鹈鹕的SVG图像)。SVG(Scalable Vector Graphics)是一种基于XML的矢量图形描述语言,用文本代码定义点、线、曲线和形状来构成图像。让LLM生成SVG之所以成为流行的测试方式,是因为它同时考验多种能力:模型需要具备空间推理能力来理解物体的几何形态和相对位置关系,需要代码生成能力来输出语法正确的SVG标记,还需要世界知识来了解鹈鹕和自行车各自的视觉特征。这个任务最早在Twitter/X上由AI研究者们自发传播,逐渐演变为一种社区共识的非正式基准。Claude、GPT-4等大参数模型通常能生成可辨识的图像,而小模型则往往力不从心。
测试结果:不同量化版本表现几乎一样差
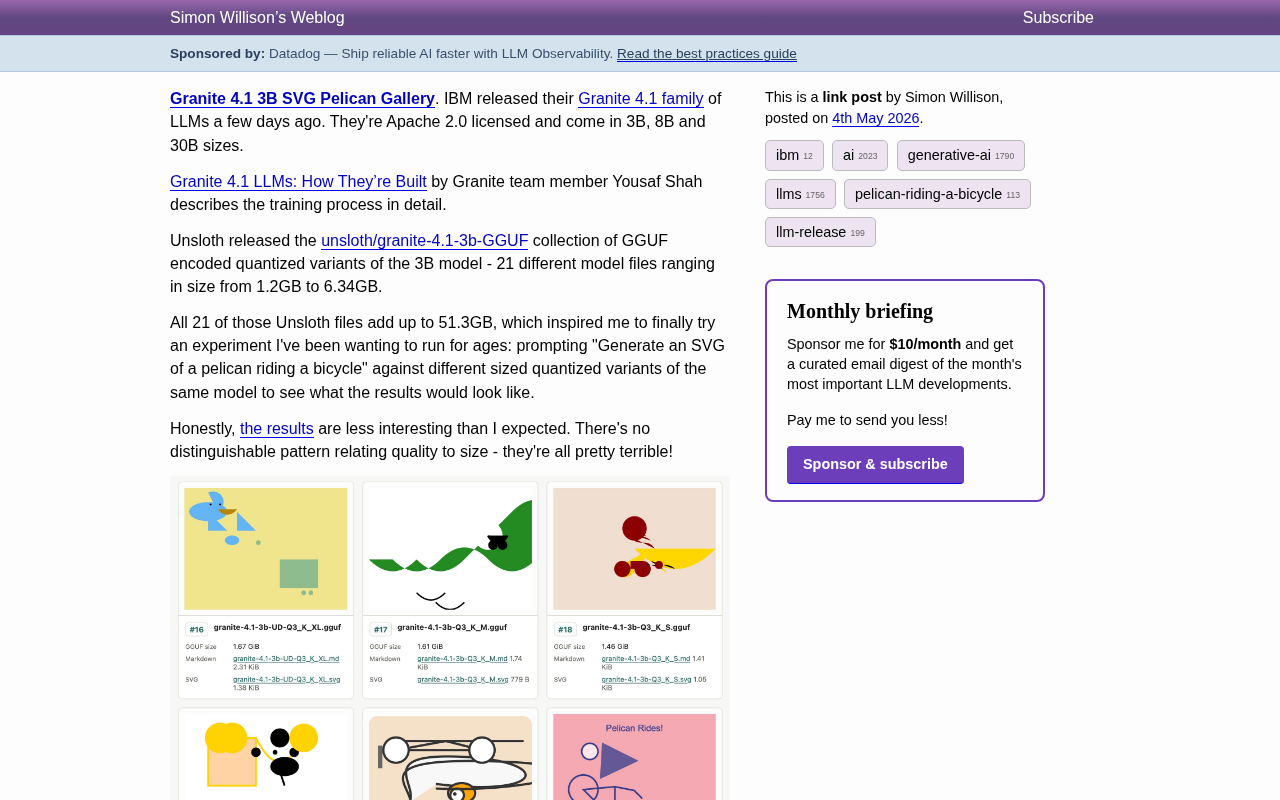
Simon坦言,结果比他预期的要无聊得多。不同量化版本之间并没有呈现出明显的质量梯度——它们的表现都相当糟糕。
从他发布的对比图来看,从1.67GB到1.2GB的六个不同大小的模型生成的SVG图像,几乎都是一堆抽象的几何形状拼凑。有趣的是,反而是最小的模型生成了最像自行车的图案,而最大的模型只产出了一个隐约像鹈鹕的形状。
这个结果本身就很有启发性:
- 3B参数模型在SVG生成任务上本身就力不从心,无论量化精度如何,基础能力的天花板就在那里
- 量化对不同任务的影响并不均匀——对于模型本来就不擅长的任务,量化级别的差异会被基础能力的不足所掩盖
- SVG生成需要的空间推理和代码生成能力,可能需要8B甚至30B参数规模的模型才能有效展现
大语言模型的参数量(如3B、8B、30B中的B代表十亿)直接决定了模型的"容量"——即它能编码和表达的知识与推理模式的复杂度。研究表明,许多能力存在所谓的"涌现"现象:当参数量低于某个阈值时,模型几乎完全无法完成特定任务;一旦超过阈值,能力会突然显现。SVG生成这类需要精确空间推理的任务,其涌现阈值可能恰好高于3B参数。这解释了为什么在这个实验中,量化级别的差异几乎不可见——因为所有版本都处于能力阈值之下,量化带来的微小精度损失相对于基础能力的根本不足而言微不足道。
对开发者的实际启示
这个小实验虽然看似只是一个趣味测试,但它揭示了几个在模型选型中值得关注的要点:
基础模型规模比量化级别更重要
在实际应用中,选择合适的基础模型规模比纠结量化级别更关键。如果任务本身超出了模型的能力范围,再高的量化精度也无济于事。先确认模型能力能覆盖你的需求,再考虑用量化来降低部署成本。
开源生态的协作效率令人印象深刻
从IBM发布模型到Unsloth提供量化版本,再到社区成员进行各种测试,整个流程在几天内就完成了。Apache 2.0许可证降低了参与门槛,加速了这个生态循环。对于想要本地部署LLM的开发者来说,这意味着新模型发布后很快就能拿到可用的量化版本。
评估基准的选择同样重要
Simon表示,他计划未来用更擅长绘制鹈鹕的模型重新进行这个实验。这也提醒我们,评估模型能力需要选择难度匹配的基准任务——太简单的任务无法区分差异,太难的任务则让所有版本都表现糟糕,同样无法得出有意义的结论。这在统计学中被称为"天花板效应"和"地板效应":当测试难度与被测对象的能力严重不匹配时,测试结果会聚集在量表的某一端,失去区分度。理想的基准任务应该让被测模型的表现分布在一个有意义的区间内,这样才能有效地揭示不同版本之间的真实差异。
小结
Granite 4.1的发布为开源LLM市场增添了一个有竞争力的选项,尤其是Apache 2.0许可证让它在商业应用场景中具备明显优势。而这个鹈鹕SVG实验则以一种轻松的方式提醒我们:在AI模型的评估和选型中,理解任务与模型能力的匹配关系,往往比追求量化参数的细微差别更为重要。
核心要点
- IBM发布Granite 4.1系列开源大模型(3B/8B/30B),采用Apache 2.0许可证
- Unsloth为3B模型提供了21种GGUF量化版本,大小从1.2GB到6.34GB不等
- Simon Willison用"鹈鹕骑自行车"SVG提示词测试所有21个量化版本,发现质量差异不明显且普遍表现不佳
- 实验表明3B参数模型在SVG生成任务上存在能力天花板,量化级别的影响被基础能力不足所掩盖
- 选择合适的基础模型规模比纠结量化精度更重要,评估需匹配合适的基准任务
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。