Jeremy Howard炮轰Anthropic:AI安全叙事背后的权力垄断悖论
一个关于AI递归自我改进的思想实验
知名AI研究者、fast.ai创始人Jeremy Howard近日在Twitter上发表了一段引发广泛讨论的观点,矛头直指Anthropic——当前被认为拥有顶级大模型的AI实验室。他提出了一个看似简单却极具穿透力的逻辑:如果你声称要减缓AI的递归自我改进,那你就不应该自己用最强模型来做前沿AI研究。
Jeremy Howard是AI领域最具影响力的实践者和教育者之一。他创立的fast.ai不仅开发了广受欢迎的深度学习开源库,还通过免费在线课程让数十万人学会了深度学习。Howard长期倡导AI技术的民主化和去中心化,反对将先进AI能力集中在少数大型实验室手中。他曾在Kaggle担任总裁,是ULMFiT(一种开创性的NLP迁移学习方法)的共同发明人,该方法为后来BERT、GPT等预训练模型的兴起奠定了重要基础。他的观点在AI社区中具有相当的权威性和号召力。
Howard的论述可以归结为一个精巧的政策提案:
- 拥有排名第一模型的实验室,必须承诺不将该模型用于前沿AI研究
- 但其他所有人都应该有权访问该模型
这里需要理解一个关键概念:AI递归自我改进(Recursive Self-Improvement)是人工智能领域中一个核心且具争议性的概念,最早可追溯到数学家I.J. Good在1965年提出的"智能爆炸"假说。其核心思想是:一个足够先进的AI系统能够理解并改进自身的设计,而改进后的系统又具备更强的自我改进能力,从而形成正反馈循环。在当前大模型时代,这一概念已从理论走向实践——AI实验室正在使用现有模型辅助训练数据筛选、代码编写、架构搜索甚至对齐研究本身,这意味着每一代模型都在为下一代模型的诞生提供加速度。
从定义上讲,Howard的提案意味着AI前沿不会继续推进——因为最强的工具被禁止用于最前沿的探索。同时,这也避免了危险的权力失衡,因为最强模型被广泛共享而非被单一机构垄断。
Anthropic的"反向操作"
Howard尖锐地指出,Anthropic选择了与这条"安全路径"完全相反的方向。作为当前公认的顶级实验室,Anthropic不仅允许自己使用最强模型进行前沿AI研究,还表示会"破坏"(sabotage)其他试图这样做的人。
Anthropic由前OpenAI副总裁Dario Amodei和Daniela Amodei兄妹于2021年创立,其核心叙事是成为一家"AI安全公司"。公司提出了"负责任的扩展政策"(Responsible Scaling Policy,RSP),根据模型能力的危险等级设定不同的安全阈值和部署标准。Anthropic还开创了"宪法AI"(Constitutional AI)等对齐技术,试图让模型在训练过程中内化安全准则。然而,Anthropic同时也是一家融资超过百亿美元、估值数百亿美元的商业公司,其旗舰产品Claude系列模型在多项基准测试中位居前列。这种"安全使命"与"商业竞争"的双重身份,正是Howard批评的核心靶点。
这里的"破坏"指的是Anthropic在模型安全策略中采取的一系列限制措施——对外部用户施加使用限制,同时内部团队却可以充分利用模型能力推进研究。具体而言,这些安全限制措施包括多个层面:在模型层面,通过RLHF(基于人类反馈的强化学习)和Constitutional AI等技术让模型拒绝危险请求;在API层面,设置使用策略限制特定类型的输出;在部署层面,对高风险能力进行专门的红队测试和能力评估。此外,Anthropic还会对模型进行"能力评估"(capability evaluations),当模型在特定危险领域达到预设阈值时触发更严格的安全措施。Howard所说的"破坏",正是指这些对外部用户施加的层层限制——它们客观上降低了外部研究者利用这些模型进行前沿AI研究的能力。
这种做法带来了两个直接后果:
- AI前沿持续推进:最强模型被用于开发更强的模型,递归改进的飞轮加速转动
- 权力失衡加剧:掌握最强模型的机构与其他所有人之间的能力鸿沟不断扩大
这构成了一个深刻的悖论:一家以"AI安全"为核心使命的公司,其实际行为却可能在制造最不安全的局面。
真正的立场:开放与民主化
你可能没注意到,Howard本人并不主张减缓AI递归自我改进。他在帖子末尾明确表态:
"我个人并不认为我们应该试图减缓AI的递归自我改进——我认为我们应该尽可能地开放和民主化它。"
他的论点本质上是一个逻辑一致性测试:如果你(指Anthropic等实验室)声称递归自我改进是危险的、需要被减缓,那么你的行为应该与你的言论一致。你应该确保自己的组织不能使用最强模型来推进前沿研究,而不是在限制别人的同时给自己开绿灯。
这种批评触及了AI行业一个核心张力——安全叙事与商业利益之间的冲突。当"安全"成为一种竞争壁垒而非真正的公共承诺时,它实际上服务的是市场垄断而非人类福祉。这种现象在科技行业并非首次出现——从电信行业到社交媒体,"以监管之名行垄断之实"的策略屡见不鲜。大型企业往往在自身地位稳固后才开始呼吁严格监管,因为合规成本对小型竞争者构成的负担远大于对自身的影响。
更深层的行业启示
安全与开放的伪二元对立
长期以来,AI行业存在一种流行叙事:开放模型是危险的,封闭开发才是负责任的做法。但Howard的逻辑揭示了这种叙事的另一面——封闭开发在减少外部风险的同时,可能创造了更大的系统性风险,即单一机构拥有不对称的技术优势。
事实上,开源AI生态的蓬勃发展正在挑战这一叙事。Meta的LLaMA系列开源模型打破了大模型只能由少数实验室掌控的格局;Stability AI开源了Stable Diffusion,让图像生成技术走入千家万户。学术界的大量研究也表明,开源模型通过社区的广泛审查和红队测试,其安全漏洞往往能被更快地发现和修补,而封闭模型的安全性则完全依赖于开发机构自身的评估能力和诚意。
谁来监督监督者?
如果最强AI实验室既是前沿技术的开发者,又是安全标准的制定者,还是自身行为的裁判,那么这种"自我监管"的可信度从何而来?Howard的提案虽然看似简单,却指向了一个根本性的治理问题:在AI领域,权力的制衡机制在哪里?
目前全球AI治理主要依赖三种机制:企业自律(如Anthropic的RSP、OpenAI的安全委员会)、政府监管(如欧盟AI法案、美国的行政命令)、以及行业共识(如前沿模型论坛Frontier Model Forum)。然而,这三种机制都存在明显缺陷:企业自律面临利益冲突,政府监管面临技术理解不足和立法滞后,行业共识则容易被头部企业主导。更根本的问题在于,AI能力评估本身就需要顶级技术能力,这意味着只有少数实验室有能力判断自己的模型是否安全——这构成了一个经典的"裁判员兼运动员"困境。
对中国AI生态的启示
这场讨论对国内AI行业同样具有参考价值。随着国内大模型竞争日趋激烈,如何在技术进步与安全治理之间找到平衡,如何避免"以安全之名行垄断之实",都是值得深思的问题。开源生态(如DeepSeek、Qwen等)的蓬勃发展,某种程度上正在实践Howard所倡导的AI民主化路径。
在中国,这一趋势尤为强劲:DeepSeek以其高性价比的开源模型在国际社区获得广泛认可,其V3和R1系列模型在多项基准测试中展现出与闭源顶级模型相当的能力;阿里巴巴的Qwen(通义千问)系列持续开源多个规模的模型,覆盖从轻量级到重量级的完整谱系;智谱AI的GLM系列也采取了开放策略。这些实践表明,开源路径不仅不会削弱竞争力,反而通过社区协作和生态建设创造了更大的价值。当最强模型的能力被广泛共享时,创新的门槛降低,安全审查的眼睛增多,技术进步的果实也能被更多人分享。
结语
Jeremy Howard的这段言论之所以引发共鸣,不在于他提出了一个可行的政策方案,而在于他用简洁的逻辑暴露了一个行业级的矛盾:那些最大声呼吁AI安全的人,往往是从不安全中获益最多的人。无论你站在开放还是封闭的哪一边,逻辑一致性都应该是最基本的要求。
这场讨论的深层意义或许在于提醒我们:在AI这个可能重塑人类文明的领域,我们不能仅仅依赖任何单一机构的善意承诺。真正的安全,来自于透明、开放和有效的制衡——而非将最强大的技术锁在少数人的保险箱里,然后告诉世界这是为了大家好。
核心要点
相关推荐
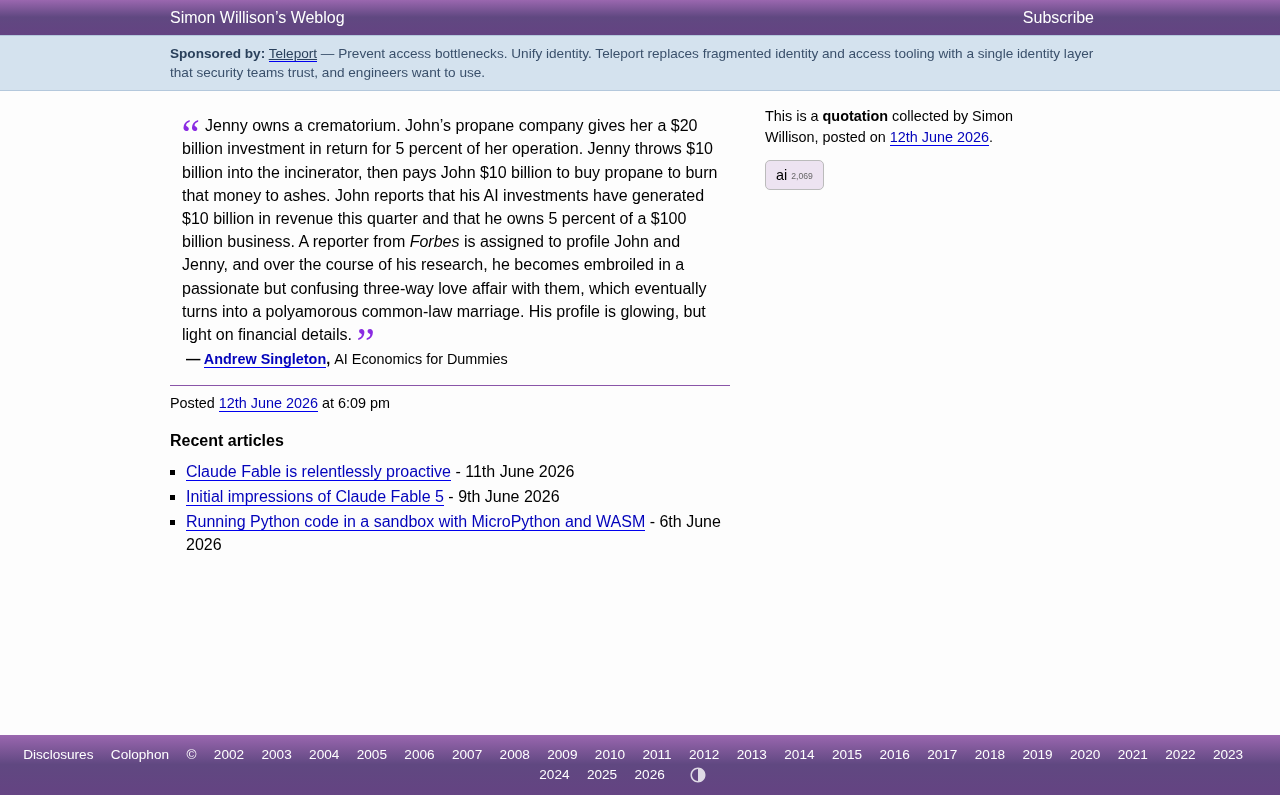
AI经济学的荒诞寓言:资本泡沫是如何被吹大的
一则精妙的AI经济讽刺寓言,揭示AI投资狂潮中的荒诞资本循环逻辑:投资变收入、估值靠魔术、媒体成共谋。拆解AI行业泡沫背后的真实隐忧。
Trae SOLO氛围编程12个实用技巧:从入门到高效协作
详解Trae SOLO氛围编程的12个实战技巧,涵盖智能体选择、Plan模式、上下文管理、自定义规则等核心用法,帮你建立高效的AI编程协作流程。
Trae+WPS实现JSA零代码登录授权系统实战教程
详解如何用Trae AI编程工具配合WPS多维表,零手写代码构建JSA登录授权系统。涵盖在线表创建、Web API鉴权脚本、本地窗体设计及远程用户权限管理全流程。