Python机器学习实战:算法推导到代码复现全流程教程
三段式框架系统学习机器学习:原理推导、代码复现、实验分析
本文介绍了一门Python机器学习实训课程的三大核心模块:算法原理推导通过通俗语言建立数学直觉,涵盖梯度、损失函数等基础概念及经典算法推导;代码复现将数学公式逐行转化为Python代码,以逻辑回归为例展示从编码到决策边界可视化的完整流程,并引入正则化等进阶优化;实验分析通过对比实验验证不同策略的效果差异,贴近实际应用场景。
课程概览:三大核心模块构建完整机器学习学习路径
对于想要系统学习机器学习的开发者来说,最大的困惑往往不是"学什么",而是"怎么学"。市面上的教程要么偏重理论推导让人望而却步,要么只讲API调用却知其然不知其所以然。这门Python机器学习实训课程提出了一个清晰的三段式学习框架:算法原理推导 → 代码复现 → 实验分析,在理论深度与实践能力之间找到了平衡点。
这种"原理-实现-验证"的学习路径,也是工业界和学术界研究机器学习算法的标准流程。下面逐一拆解这三个模块的核心内容和学习要点。
算法原理推导:从数学直觉到公式推演
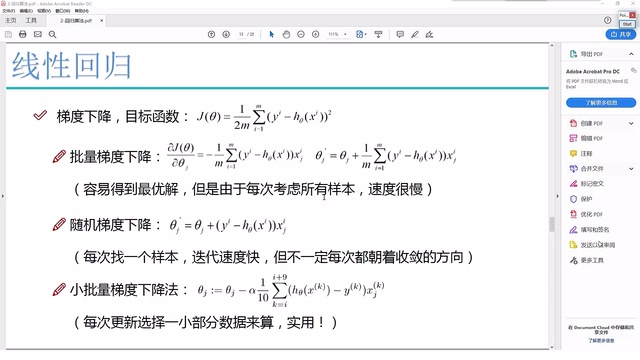
课程的第一个模块聚焦于算法的数学原理。讲师会从零开始,一步一步讲解一个算法从无到有是怎么在数学上推导出来的。
很多初学者对数学有天然的恐惧感,但机器学习的核心确实建立在数学基础之上。线性代数、概率论、微积分和最优化理论是绑定在一起的四大支柱——线性代数提供了数据表示(矩阵、向量)和变换的工具;概率论支撑了贝叶斯推断、最大似然估计等统计学习方法;微积分中的梯度概念是反向传播和参数更新的核心;最优化理论则研究如何高效地找到损失函数的最小值。这四个领域相互交织,例如梯度下降本质上是微积分与最优化的结合,而逻辑回归的参数估计则同时依赖概率论(似然函数)和微积分(求导)。课程采用了一种务实的策略:不追求数学上的严格性,而是通过通俗的语言和具体的小例子来帮助学习者建立直觉。
这种教学方式有明显的优势——降低了入门门槛,让更多编程背景的学习者能够理解算法背后的"为什么"。不过需要注意的是,如果未来要深入研究或改进算法,仅靠直觉理解是不够的,还需要补充严格的数学训练。
原理推导涵盖的关键内容
这个模块涵盖的内容包括:
- 基础数学知识点:梯度、损失函数、概率分布等核心概念
- 经典算法的推导过程:如逻辑回归、决策树、集成学习等
- 常见的优化策略:梯度下降、正则化等解决方案
理解算法原理的价值在于,当你在实际项目中遇到模型效果不佳的情况时,能够从原理层面分析问题所在,而不是盲目调参。
代码复现:逐行实现机器学习算法的完整逻辑
第二个模块是将数学公式转化为可运行的Python代码。课程的方式是一个模块一个模块、一行一行地讲解每一行代码做了什么事。
讲师使用Eclipse作为IDE(学习者可以自由选择PyCharm、VS Code或Jupyter等任何Python开发环境),从零开始带领学习者完成整个算法的代码实现。
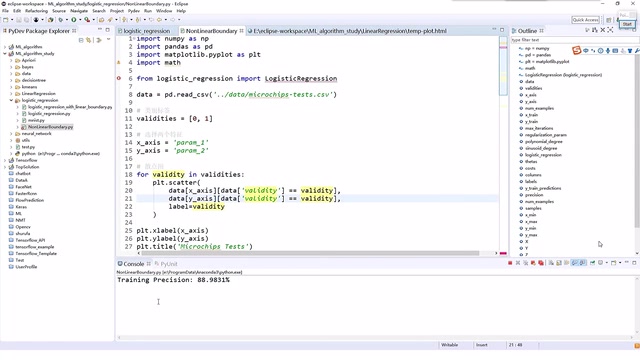
代码复现的核心流程
从课程展示的逻辑回归案例来看,代码复现遵循以下步骤:
- 明确算法的核心流程和步骤:先梳理清楚要实现哪些功能模块
- 逐模块编码实现:将每个数学步骤翻译成对应的Python代码
- 模块组装:将各个功能模块组合成完整的算法
- 数据集测试与验证:在实际数据上运行,观察模型效果
以逻辑回归为例,这是机器学习中最经典的二分类算法之一。尽管名字中带有"回归",但它实际上是一个分类模型——其核心思想是通过Sigmoid函数将线性组合的输出压缩到(0,1)区间,从而表示样本属于某一类别的概率。逻辑回归的参数通过最大化对数似然函数(等价于最小化交叉熵损失)来估计,通常使用梯度下降或其变体进行优化。由于其可解释性强、计算效率高,逻辑回归至今仍是工业界广泛使用的基线模型,尤其在广告点击率预测、信用评分等场景中表现出色。课程中展示了一个很有说服力的例子:完成逻辑回归算法后,通过可视化展示了数据集的分布、迭代过程中模型效果的变化,以及最终得到的决策边界。
决策边界(Decision Boundary)是分类模型在特征空间中划分不同类别区域的分界线(二维)或超平面(高维)。通过可视化决策边界,学习者可以直观判断模型的拟合状态:过于复杂、锯齿状的边界往往意味着过拟合(模型过度记忆训练数据的噪声),而过于简单的线性边界则可能欠拟合。这种"写完就测"的方式能够给学习者即时反馈,增强学习的成就感。
从基础实现到进阶优化
课程不仅停留在基础实现层面,还会引导学习者思考如何优化算法:
- 加入非线性变换来处理线性不可分的数据
- 引入特征工程和正则化等方法来提升模型效果
- 通过对比不同策略的效果,理解每种优化手段的适用场景
其中,正则化是防止模型过拟合的核心技术,其本质是在损失函数中加入对模型复杂度的惩罚项。L1正则化(Lasso)会产生稀疏解,具有自动特征选择的效果,适合高维稀疏数据;L2正则化(Ridge)则倾向于让所有参数均匀缩小,对共线性特征更鲁棒。从贝叶斯视角理解,L1对应参数的拉普拉斯先验,L2对应高斯先验。在实践中,正则化强度需要通过交叉验证来选择最优值——过大会导致欠拟合,过小则正则化效果不明显。
这种渐进式的代码构建方式,比直接调用sklearn等库的API更能帮助学习者理解算法的内部机制。
实验分析:对比验证与策略选择
第三个模块是实验分析,也是最贴近实际应用的部分。课程会对经典机器学习算法的核心知识点进行详细介绍,并通过大量的对比实验来展示不同策略的效果差异。
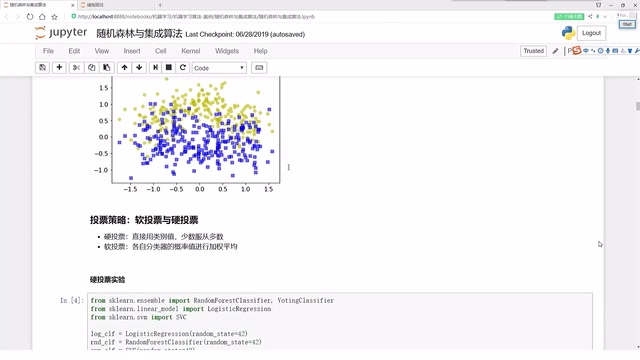
以集成学习算法为例
集成学习(Ensemble Learning)通过组合多个基学习器来提升整体预测性能,其核心思想是
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。