基于Dify+Neo4j搭建本地知识图谱RAG系统实战
为什么传统RAG不够用?
传统的RAG(检索增强生成)系统在处理简单的事实性问答时表现尚可,但面对复杂的关系推理时往往力不从心。例如,当你问"小明和张红是什么关系"时,如果知识库中只记录了"小明的妈妈是李华"和"李华的妈妈是张红",传统RAG很难通过两跳推理得出"张红是小明的外婆"这一结论。
这正是GraphRAG(知识图谱增强的RAG)的价值所在。通过将实体和关系构建成图结构,AI不仅能找到答案,还能理解实体之间的深层关联,实现多跳推理,真正激活知识的深层价值。
本文基于B站UP主"阿水"的保姆级教程,梳理从零搭建本地化知识图谱RAG系统的完整流程,涵盖数据准备、Neo4j图谱构建、Dify工作流集成三大核心环节。
整体架构与工具选型
整个系统的技术栈由三层组成:
- Docker:容器化平台,负责统一管理Neo4j和Dify的运行环境,免去繁琐的依赖安装
- Neo4j:高效的图数据库,用于存储和查询实体之间的关系
- Dify:低代码/无代码AI应用平台,通过可视化的Chatflow构建RAG工作流
这种架构的优势在于:所有组件都运行在本地Docker容器中,数据完全自主可控,无需依赖云服务器,特别适合对数据安全有要求的场景。
第一步:数据准备与处理
数据获取
知识图谱的质量取决于底层数据的质量。教程中使用了一份食谱相关的数据集(包含6条精简数据),原始数据量较大,在普通电脑上运行较慢,因此做了裁剪。实际应用中,你需要根据自己的业务场景准备相应的内部数据。
数据格式化
Neo4j导入数据时推荐使用JSON格式。如果你的原始数据是非结构化文本(如PDF、Word文档),需要先进行结构化处理,从中提取实体和关系信息。这一步可以借助大模型辅助完成,但仍需人工核查确保准确性。
实战提示:在实际项目落地中,实体识别和关系抽取是最大的痛点。数据量大时需要专业人员参与,大模型可以辅助但不能完全替代人工审核。
第二步:Neo4j知识图谱构建
环境安装
首先需要在Docker中拉取Neo4j镜像。启动时有几个关键配置需要注意:
- 启用APOC插件:这是Neo4j的一个扩展插件,支持导入本地JSON文件。没有它就无法将准备好的数据导入图数据库
- 内存设置:建议设置最大内存为4GB(根据机器性能调整)
- 用户认证:默认用户名为
neo4j,密码设置为password
安装APOC插件后,可以通过查询语句验证是否成功。如果返回了大量工具列表,说明插件已正确加载。
构建图谱
知识图谱由实体和关系两部分组成。以食谱场景为例:
- 实体:米饭、鸡蛋、蔬菜、食用油、蛋白炒饭、主食等
- 关系:食材→可制作→菜品,菜品→属于→分类
将JSON数据文件放入Neo4j的import目录后,通过Neo4j的Cypher查询语言执行导入命令。导入完成后,可以在Neo4j的可视化界面中看到各实体之间的关系网络,支持拖拽交互查看。
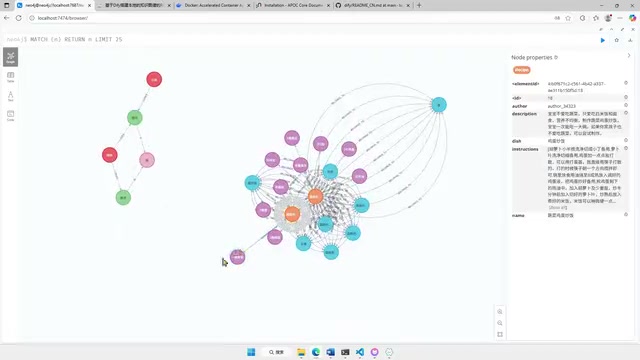
通过查询语句还可以检查每个标签对应的节点数量,确保数据导入完整无误。
第三步:Dify集成与RAG工作流搭建
Dify安装与模型配置
Dify同样通过Docker部署。从GitHub下载源码后,在Docker目录下执行启动命令即可。首次拉取镜像大约需要15-20分钟。
启动后访问127.0.0.1进入Dify界面,在设置中配置模型供应商。教程推荐使用硅基流动(SiliconFlow),原因是其免费额度较高——新用户注册即送14元额度,邀请新用户还可额外获得14元,对于学习和测试完全够用。配置时只需填入API Key即可。
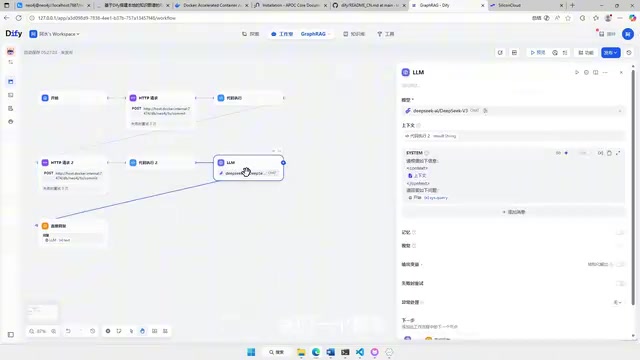
工作流构建
Dify通过HTTP请求访问Neo4j数据库。由于Neo4j有用户认证,需要将用户名密码转换为Base64编码格式,在Dify的HTTP请求节点中使用。
具体步骤:
- 在PowerShell中将
neo4j:password转换为Base64编码 - 保存编码结果,后续在Dify中替代明文密码
- 通过curl命令验证HTTP请求能否正确访问Neo4j
- 在Dify中导入预制的Chatflow工作流文件
- 关键修改:将工作流中的Base64认证信息替换为你自己的编码值
- 选择合适的大模型(教程使用DeepSeek V3)
整个Chatflow的逻辑非常清晰:用户提问 → HTTP请求查询Neo4j → 获取图谱中的关联实体和关系 → 大模型基于图谱信息生成回答。
效果验证
搭建完成后,可以在Dify的预览界面进行测试。例如提问"我有一碗米饭,可以做什么吃的?",系统会基于知识图谱中的食材关系,返回蔬菜鸡蛋炒饭等多种推荐方案,并且回答有理有据。
进阶:嵌入网页部署
Dify支持将构建好的AI应用嵌入到自有网页中。操作方式非常简单:
- 在Dify中点击"嵌入网站"
- 选择第二种嵌入方式(右下角悬浮按钮样式)
- 复制生成的嵌入代码
- 粘贴到HTML文件的
<body>标签中
保存后打开网页,右下角会出现一个对话按钮,点击即可与知识图谱RAG系统进行交互。需要注意的是,每次对话都会消耗模型Token,如果将应用公开给他人使用,要注意额度管理。
总结与思考
本文介绍的GraphRAG方案相比传统RAG有三个显著优势:
- 关系推理能力:通过图结构实现多跳推理,理解实体间的深层关联
- 本地化部署:全部组件运行在Docker容器中,数据安全可控
- 低门槛集成:借助Dify的可视化工作流,无需编写大量代码
当然,这套方案也有其局限性。实体识别和关系抽取仍然是最大的工程挑战,数据规模较大时对机器性能有一定要求,且知识图谱的维护和更新需要持续投入。但作为入门级的GraphRAG实践,这套方案已经能够很好地展示知识图谱在RAG系统中的价值。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。