接口自动化测试框架封装思路:从原理到实战详解
构建接口自动化测试框架的核心思路与关键模块解析
文章从手工接口测试的局限性出发,阐述了构建自动化测试框架的必要性。介绍了接口测试的基本原理(HTTP请求-响应模型)、AI辅助测试的新趋势,重点讲解了基于Pytest进行二次封装的框架设计思路,包括参数统一管理(数据驱动)、接口关联与Token传递、灵活断言机制三大核心模块。
从手工测试到自动化:为什么需要框架
接口测试是软件质量保障的重要环节。从最基础的手工测试开始,我们通常使用Postman、Apifox等工具,输入URL地址、填写参数、设置前置/后置操作,就能完成单个接口的验证。但当项目中接口数量达到数百甚至上千个时,手工方式就显得力不从心了。
这正是接口自动化测试框架存在的意义——通过代码化、模块化的方式,将重复性的测试工作系统化管理。
现代接口测试工具的AI化趋势
传统工具的痛点
目前主流的接口测试工具如Postman,在国内使用时经常遇到登录困难的问题。这促使很多测试工程师转向Apifox等国产替代方案。无论选择哪个工具,核心操作流程是一致的:
- 输入接口地址和请求方式
- 填写请求参数
- 配置前置操作(如加解密处理)
- 配置后置操作(如数据提取、断言验证)
AI辅助接口测试的新玩法
新一代接口测试工具已经集成了AI能力。例如,你可以直接用自然语言告诉工具"帮我写一个参数解密脚本",或者在后置处理中说"提取响应中的token字段",AI就会自动生成对应的脚本代码。甚至可以将接口文档直接复制粘贴,工具会自动创建对应的接口请求配置,大幅提升了测试效率。
接口自动化测试的基本原理
接口自动化的本质其实很简单:通过编写代码来访问接口,并对返回结果进行验证。要真正理解这一过程,需要先掌握HTTP请求-响应模型的底层机制。
HTTP请求-响应模型是接口测试的基础通信协议。每次接口调用本质上是客户端向服务器发送一个结构化的请求报文,服务器处理后返回响应报文。请求报文由三部分组成:请求行(方法+URL+协议版本)、请求头(Headers)和请求体(Body)。GET请求通常将参数附加在URL的查询字符串中,而POST请求则将数据放在请求体中,常见格式包括application/json、application/x-www-form-urlencoded和multipart/form-data。响应报文则包含状态码(如200表示成功、401表示未授权、500表示服务器错误)、响应头和响应体。理解这一模型,是从"会点按钮"到"真正懂测试"的关键跨越。
以Python为例,核心流程如下:
- 使用
requests库发送HTTP请求 - 指定URL地址、请求方式(GET/POST等)、请求参数
- 获取响应数据
- 编写断言验证结果是否符合预期
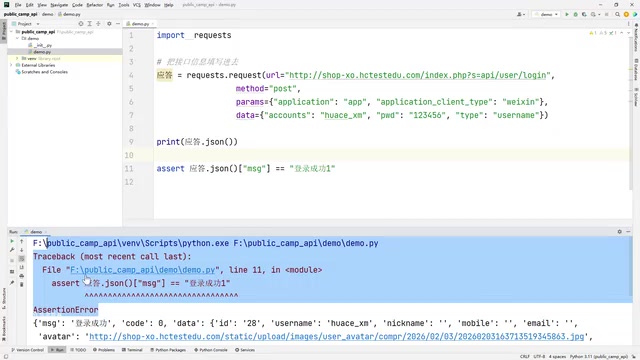
例如,对登录接口进行测试时,我们发送请求后检查返回的message字段是否为"登录成功"。如果断言不通过,程序会直接报错提示断言失败。这就是最基础的接口自动化测试。
为什么简单脚本无法满足实际工作需求
虽然单个接口的自动化测试写起来很简单,但在实际工作中,这种"一个接口一段代码"的方式存在严重问题:
- 无法通用:每个接口都要重复编写类似的请求代码
- 维护困难:接口变更时需要逐个修改
- 缺乏系统性:没有统一的数据管理、日志记录和报告生成
这就是为什么很多人觉得"接口自动化看起来简单,但工作中用起来很难"的根本原因。要真正在项目中落地,必须构建一套完整的自动化测试框架。
自定义接口自动化框架的封装思路
Pytest的定位与局限
Pytest是Python生态中最主流的测试框架,其核心优势体现在三个机制上:fixture(夹具)机制允许以依赖注入的方式为测试用例提供前置数据或环境,支持session、module、class、function四种作用域,非常适合管理数据库连接、登录态等共享资源;参数化(parametrize)装饰器可以用一套测试逻辑驱动多组数据,避免重复代码;插件生态方面,pytest-html生成HTML报告、pytest-xdist支持并行执行、allure-pytest对接Allure报告平台。正是这些能力,使Pytest成为接口自动化框架的理想底座。但Pytest本身并不内置HTTP请求能力,需要配合requests等库才能完成接口测试的完整闭环——这也是为什么大多数公司的做法是:借助Pytest的基础能力,在其之上进行二次封装。
框架封装的三大核心模块
一个完整的接口自动化测试框架,至少需要解决以下三个问题:
1. 参数统一管理
不同接口有不同的参数需求,框架需要提供统一的参数管理机制。这里涉及到**数据驱动测试(Data-Driven Testing,DDT)**的核心设计模式——将测试逻辑与测试数据彻底分离。在实践中,YAML因其语法简洁、支持注释、天然支持嵌套结构,成为存储接口测试数据的首选格式;Excel则因为业务人员更熟悉,常用于测试用例的协作维护。一个典型的YAML测试数据文件会包含接口路径、请求方法、请求参数、预期断言等字段,框架读取后通过Pytest的parametrize机制动态生成测试用例。这种方式的最大价值在于:当接口的请求参数或预期结果发生变化时,测试工程师只需修改数据文件,完全不需要触碰测试代码,大幅降低了维护成本。
2. 接口关联与数据提取
实际业务中,接口之间往往存在依赖关系。最典型的场景是Token传递——绝大多数接口都需要携带身份认证信息,最常见的是JWT(JSON Web Token)。JWT由Header、Payload和Signature三部分Base64编码后拼接而成,服务端通过验证Signature来确认请求合法性,无需在服务端存储会话状态,因此非常适合分布式系统。
在接口自动化框架中,处理Token关联通常有两种方案:一是使用Pytest的session级别fixture,在整个测试会话开始时执行一次登录并缓存Token,后续所有用例通过依赖注入获取;二是使用全局变量池(如一个单例的字典对象),在登录用例执行后将Token写入,后续接口从中读取并注入到请求头。前者更符合Pytest的设计哲学,后者在跨文件、跨模块的复杂场景下更灵活。
3. 灵活的断言机制
断言不仅仅是"两个值是否相等"这么简单。实际场景中需要支持多种断言方式:
- 等于 / 不等于
- 大于 / 小于
- 包含 / 不包含
- 正则匹配
- JSON Schema验证
其中JSON Schema验证值得重点关注。JSON Schema是一种用于描述和验证JSON数据结构的规范,它允许你定义一个"契约":规定响应中哪些字段是必须存在的、每个字段的数据类型是什么、数值的取值范围是多少。相比简单的字段值断言,JSON Schema验证更适合做"结构性断言
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。