J语言模块系统入门:import与load区别及多文件项目实战

J语言模块系统设计解析:import与load双关键字的职责划分
本文通过"Hello Sailor"程序拆解J语言的核心语法与模块系统。J语言用双冒号::统一常量和函数定义,print函数采用类型安全的统一%占位符,模块系统以import导入标准库模块、load加载文件的双关键字设计实现了模块发现与文件组装的清晰分层,并支持通过编译参数自定义搜索路径,编译速度仅需0.08秒。
前言
一门编程语言的模块系统设计,往往决定了它在实际工程中能走多远。J语言作为一门新兴的系统编程语言,在模块化组织方面走出了自己的路子。
本文通过一个"Hello Sailor"程序,逐步拆解J语言的基础语法、函数定义、打印机制以及模块导入系统。内容基于一期B站技术视频整理,适合对编程语言设计感兴趣、想快速上手J语言的开发者阅读。
J语言基础语法:从main函数到常量定义
程序入口与常量绑定
J语言的程序入口同样是 main 函数,但定义方式颇具特色。J语言使用双冒号 :: 来定义常量,而函数本身也被视为一个常量:
main :: () {
// 函数体
}
:: 表示左边的 main 是一个常量绑定。定义普通常量的写法完全一致:
count :: 13
这种统一的绑定语法让变量和函数的定义方式保持了高度一致性,学习时只需要记住一套规则。
这一设计源自函数式编程中"函数是一等公民"的核心理念。在Haskell、ML等语言中,函数定义本质上就是将一个lambda表达式绑定到一个名称上。这种统一性意味着编译器内部不需要区分"变量声明"和"函数声明"两套语法树节点,简化了语言的形式语义。Rust中的 const fn、Zig中的 comptime 函数也体现了类似的思路——模糊编译期常量与函数之间的界限。对于开发者而言,你不需要记住"定义变量用什么语法、定义函数用什么语法",一切都是名称到值的绑定。
函数参数与返回值
函数的参数放在小括号中,main 函数不接受形参,所以括号为空。如果函数需要返回值,通过箭头 -> 尾随指定返回类型:
main :: () -> u16 {
// ...
}
这种设计风格与Rust、Zig等现代系统编程语言类似,语法简洁且类型信息一目了然。
箭头 -> 指定返回类型的语法被称为"trailing return type"(尾随返回类型),这一设计在现代语言中已成为主流趋势。传统C/Java将返回类型前置(如 int main()),当类型表达式变得复杂时(如函数指针、泛型),前置类型会严重影响可读性。Rust、Swift、Kotlin、Go(使用空格而非箭头)都采用了后置返回类型。这种设计的另一个优势是便于类型推断——编译器在解析函数签名时,可以先确定参数类型,再根据上下文推断或验证返回类型,这对于支持泛型和类型推导的语言尤为重要。
J语言print函数:类型安全的格式化输出
当我们在 main 中直接调用 print 函数时,编译器会报错:"undeclared"——它不知道 print 从哪里来。这就引出了J语言的模块导入机制。
通过 import basic 导入标准库后,print 函数才能正常使用。不过J语言的 print 有严格的类型约束:第一个参数必须是字符串类型。
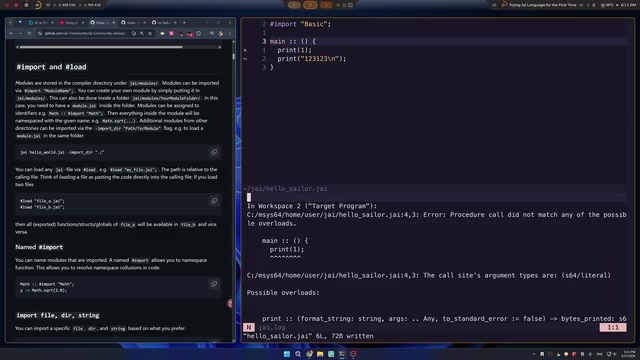
直接传入数字 1,编译器会立刻报错:"procedural call doesn't match any of the possible overloads"。正确的做法是使用百分号 % 作为占位符:
print("%", 1)
与C语言printf的关键区别
C语言的 printf 需要用 %s、%d 等格式化标识符区分类型,而J语言统一使用单个 % 作为占位符,不论传入的是什么类型。多个占位符的用法也很直观:
print("% % %", 1, 2, 3) // 输出: 1 2 3
这种设计大幅简化了格式化输出的心智负担——你不再需要记住各种格式化标识符,编译器会自动处理类型匹配。同时也从根本上避免了C语言中因格式化字符串与参数类型不匹配而导致的安全漏洞。
从技术实现角度看,J语言统一使用 % 作为占位符而无需指定类型,背后依赖的是编译期多态分发(compile-time polymorphic dispatch)机制。编译器在编译阶段就知道每个参数的具体类型,因此可以自动选择正确的序列化方法将值转换为字符串。这与C语言 printf 的运行时解析格式字符串有本质区别——printf 在运行时才根据 %d、%s 等标识符决定如何解释栈上的字节,如果格式字符串与实际参数不匹配,就会导致未定义行为甚至安全漏洞(如格式化字符串攻击,攻击者通过控制格式字符串读取或写入任意内存)。Rust的 println! 宏、Python的f-string、C++20的 std::format 都采用了类似的编译期类型安全策略,但实现路径各不相同:Rust通过宏展开在编译期生成类型特化代码,C++通过模板元编程实现,而J语言则通过其编译器内建的重载解析机制完成。
J语言模块系统详解:import与load的分工
J语言的模块系统围绕两个核心关键字展开:import 和 load,两者职责明确、互不混淆。搞清楚import与load的区别,是掌握J语言项目组织的关键一步。
编程语言的模块系统大致分为两个流派:基于文件的隐式模块(如Go、Python,文件即模块)和基于声明的显式模块(如Rust的 mod、C++20的 module)。J语言的 import + load 双关键字设计实际上融合了两种思路:import 提供了声明式的模块发现机制,而 load 则保留了文件级别的直接包含能力。这种分层设计解决了一个经典难题——如何在保持模块封装性的同时,允许库作者灵活组织内部文件结构。C/C++的 #include 因为缺乏模块语义,导致了头文件地狱和编译时间膨胀;而纯模块系统(如Java的 package)有时又显得过于僵化。J语言的方案在两者之间找到了平衡点。
import:导入标准库和已注册模块
import 用于导入模块(module),通常是标准库或已放置在特定搜索路径下的模块。写下 import basic 时,编译器会按照预设的搜索路径查找名为 basic 的模块:
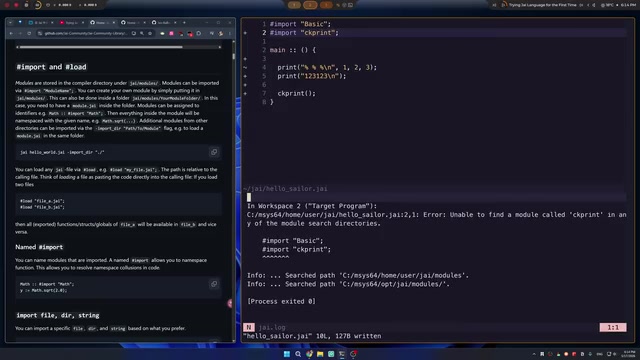
搜索路径主要包括两个位置:
- 全局标准库路径:位于系统的
/opt/j/modules/目录下,包含basic、mgui、input等官方模块 - 当前用户的modules目录:位于用户主目录下的
j/modules/路径
标准库的目录结构很清晰:每个模块文件夹下包含一个 module.j 作为入口文件,内部通过 load 引入各个子文件。
load:直接加载文件内容
load 的作用更加底层——它将指定文件的代码原封不动地"粘贴"到当前位置,类似于C/C++中的 #include。
假设我们创建了一个自定义函数 ckprint,保存在 ckprinter.j 文件中:
ckprint :: () {
import basic;
print("this is check out");
}
要在主程序中使用它,有两种方式:
方式一:放入modules目录,通过import导入
将文件放入搜索路径中的 modules 目录,即可直接 import ckprinter。
方式二:使用load直接加载文件路径
load "./path/to/ckprinter.j";
注意 load 需要指定完整的文件后缀 .j,这一点和 import 只写模块名不同。
构建多文件J语言模块库
当一个库包含多个文件时,需要创建子目录并提供 module.j 入口文件:
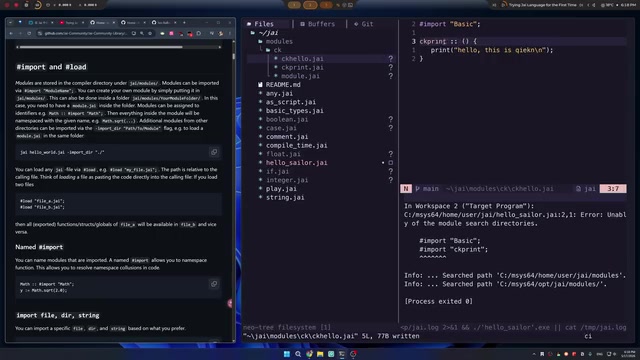
例如,创建一个名为 ck 的模块库,包含 ckprinter.j 和 ckhello.j 两个文件,目录结构如下:
modules/
ck/
module.j // 入口文件
ckprinter.j
ckhello.j
module.j 中通过 load 引入所有子文件:
load "ckprinter.j";
load "ckhello.j";
主程序中只需一行 import ck 即可使用库中的所有函数。这种 import 负责模块发现、load 负责文件组装的分层设计,让模块的对外接口和内部实现之间有了清晰的边界。
自定义导入路径与多项目构建
实际项目开发中,我们往往不希望把所有库文件都拷贝到固定的 modules 目录。J语言提供了编译时指定额外导入路径的能力,让项目组织更加灵活。
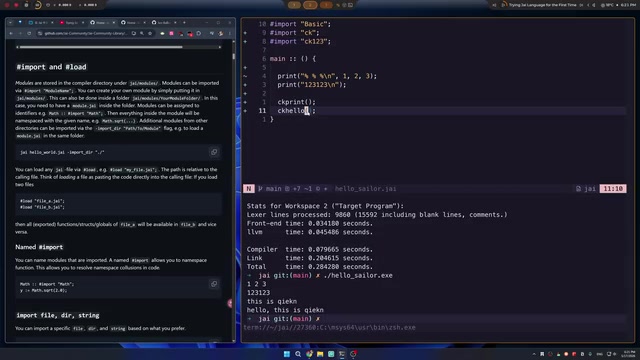
通过编译命令的 -import-directory 参数,可以添加自定义的模块搜索路径:
j hello_sailor.j -import-directory ./test
这样,放在 ./test 目录下的模块也能被 import 正常找到。这个特性在以下场景中特别实用:
- 多项目共享公共库:将公共模块放在统一目录,各项目通过参数引用
- CI/CD构建环境:在不同环境中灵活配置模块路径
- 第三方库管理:将下载的第三方模块放在项目本地目录
编译器的错误提示也做得相当到位——当找不到模块时,它会明确告诉你 "unable to find module called xxx in any of the module search directories",并列出所有搜索过的路径,帮助开发者快速定位问题。
编译速度与实际开发体验
视频中展示的编译速度令人印象深刻——整个项目的编译仅需 0.08秒。对于一门拥有完整模块系统的编程语言来说,这样的编译速度意味着极短的反馈循环。
快速编译带来的好处很直接:改完代码几乎可以立即看到结果,不用干等构建过程跑完。这对于日常开发中的调试和迭代效率提升非常明显,体验上接近解释型语言的即时反馈,同时又保留了编译型语言的性能优势。
将这一数据放在行业背景下更能体会其意义。作为对比,同等规模的Rust项目首次编译通常需要数秒到数十秒(主要因为borrow checker分析和单态化泛型的代码生成开销),C++项目因模板实例化和头文件重复解析也往往耗时较长。实现快速编译通常需要在语言设计层面做出取舍:限制泛型的复杂度、采用增量编译架构、避免复杂的类型推断算法、使用单遍或少遍编译策略等。Go语言同样以编译速度著称(通常在1-2秒内完成中型项目),其秘诀包括禁止循环依赖、简化类型系统、以及包级别的并行编译。J语言能达到如此编译速度,很可能也在语言复杂度和编译器架构上做了类似的精心设计——这种"编译速度优先"的设计哲学,对于需要频繁编译-运行-调试循环的系统编程场景尤为重要。
总结:J语言模块设计的核心亮点
J语言虽然目前还不是主流语言,但从其模块系统的设计中可以看出不少值得关注的思路:
- 常量绑定语法
:::统一了变量和函数的定义方式,概念简洁 - 类型安全的print函数:用统一的
%占位符替代C语言复杂的格式化标识符,既简单又安全 - import + load双关键字:清晰地分离了模块导入和文件包含两种需求,各司其职
- 灵活的搜索路径配置:通过
-import-directory参数兼顾标准库使用和自定义库管理 - 极快的编译速度:0.08秒的编译时间带来流畅的开发体验
对于关注编程语言设计的开发者来说,J语言在模块系统上的这些设计选择——特别是import与load的职责划分,以及类型安全的格式化输出——都值得深入研究和借鉴。如果你对系统编程语言的新方向感兴趣,不妨动手试试J语言,从一个简单的Hello Sailor程序开始探索。
核心要点
- J语言使用双冒号::定义常量和函数,函数通过箭头->指定返回类型,语法风格接近Rust和Zig等现代语言
- print函数强制要求字符串类型参数,使用统一的%占位符替代C语言的%s/%d等格式化标识符
- import关键字用于导入标准库模块,load关键字用于加载任意文件(类似C的#include),两者职责分明
- 多文件库需要提供module.j入口文件,通过load引入子文件,形成清晰的库组织结构
- 编译时可通过-import-directory参数指定额外的模块搜索路径,支持灵活的项目库管理
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。