开源多Agent智能诊断系统:MCP+RAG+Skill路由架构深度解析
整合MCP、RAG与Skill路由的开源多Agent智能诊断系统
该开源项目基于OneCall魔改,将MCP协议、RAG检索增强和Skill路由三大能力整合为统一的智能诊断系统。其核心创新在于"先选Skill再调工具"的两阶段策略,通过轻量级意图分类大幅降低Token消耗。系统支持电脑实时诊断、RAG多轮追问、MCP实时交互及知识库管理,模块化架构设计使其易于扩展。
项目概述
最近,一个基于 OneCall 魔改的开源多 Agent 项目引起了不少关注。该项目将 MCP(Model Context Protocol)、RAG(检索增强生成)、Skill(技能路由) 三大核心能力整合到一个统一的智能诊断系统中,能够对电脑进行实时诊断、生成报告,并支持多轮追问与联网检索。
MCP 协议背景:MCP 是由 Anthropic 于 2024 年底提出并开源的标准化协议,旨在解决大语言模型与外部工具、数据源之间的「最后一公里」连接问题。在 MCP 出现之前,每个 AI 应用都需要为不同工具编写定制化的集成代码,维护成本极高。MCP 借鉴了 LSP(Language Server Protocol)的设计思想,定义了一套统一的客户端-服务器通信规范,使得任何支持 MCP 的模型都能即插即用地调用文件系统、数据库、浏览器等本地或远程资源。目前 Claude、Cursor 等主流 AI 产品已率先支持 MCP,生态正在快速扩张。
这个项目的最大亮点在于其模块化的架构设计——通过 Skill 路由机制先筛选合适的技能模块,再调用对应工具执行任务,从而大幅降低 Token 消耗,提升响应效率。
核心功能演示
Skill 路由与智能诊断
Skill 路由本质上是多 Agent 系统中的「意图分发层」,其设计灵感来源于微服务架构中的 API 网关模式。在传统的 ReAct(Reasoning + Acting)框架中,模型需要在每一步推理时面对全量工具描述,当工具数量超过 20 个时,Token 消耗和模型的工具选择准确率都会显著下降——这一现象被称为「工具过载」(Tool Overload)问题。Skill 路由通过引入轻量级的意图分类器(可以是规则引擎、小模型或向量相似度匹配),将用户意图先映射到某个 Skill 域,再仅向主模型暴露该域内的工具子集,从而将工具选择的搜索空间从 O(N) 压缩到 O(K),K 远小于 N。
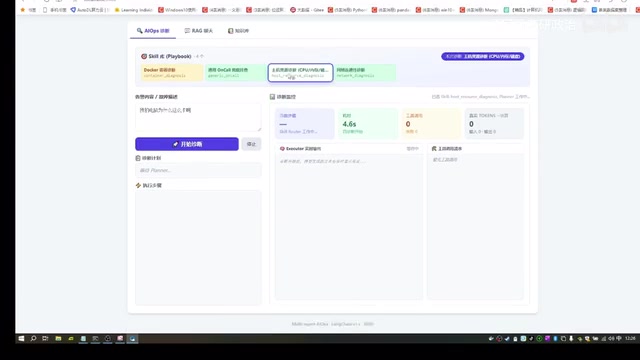
系统启动后,用户可以在前端界面输入问题,例如"我的电脑为什么这么卡",然后点击"开始诊断"。系统会经历以下流程:
- Skill 选择:根据问题语义,自动匹配最合适的技能模块
- 诊断计划生成:根据选定的 Skill 制定检索和诊断计划
- 工具调用:按计划依次调用系统工具进行数据采集
- 报告生成:汇总所有诊断数据,生成结构化的诊断报告
右侧界面会实时显示耗时和已调用的工具列表,中间区域则是实时检测的状态框。最终生成的诊断报告能够精准定位问题——比如演示中就准确识别出最大的资源占用来自一个刚启动的游戏。
值得一提的是,系统中设置了一个"通用 OneCall"兜底机制:当所有预定义的 Skill 都无法匹配用户问题时,系统会自动降级到通用模式进行处理,确保不会出现无响应的情况。
RAG 聊天与多轮追问
RAG 由 Meta AI 研究团队于 2020 年在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中正式提出。其核心思想是将「参数化知识」(模型权重中存储的知识)与「非参数化知识」(外部向量数据库中的文档)结合起来,在推理时动态检索相关片段注入上下文,从而突破模型训练数据截止日期的限制,并显著降低幻觉率。典型的 RAG 流程包括:文档切片 → Embedding 向量化 → 存入向量数据库 → 查询时相似度检索 → 将命中片段拼入 Prompt。
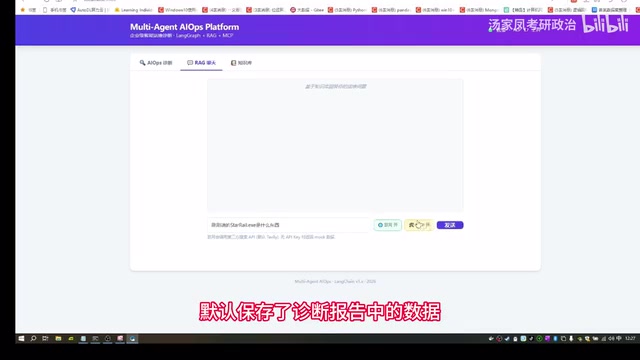
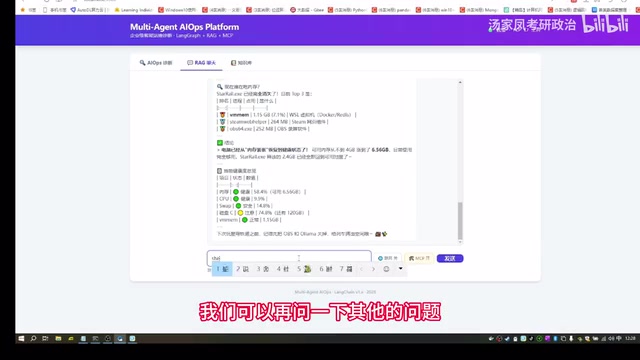
诊断报告生成后,用户可以切换到 RAG 聊天模式 进行进一步追问。这一模式的设计相当巧妙:
- 诊断报告中的数据会通过 Redis 缓存 自动保存,作为 RAG 的上下文知识库
- 用户的追问会基于报告内容进行检索增强,回答更加精准
- 支持开启联网搜索,在网络上查找与报告相关的补充资料(搜索范围限定在报告涉及的内容)
Redis 在多轮对话中的作用:Redis 作为内存键值数据库,在 AI 对话系统中承担着「短期记忆」的角色。相比将对话历史全部塞入 Prompt 的朴素方案,Redis 缓存具有三大优势:一是读写延迟在微秒级,不会成为响应瓶颈;二是支持设置 TTL(生存时间),可自动清理过期会话,避免内存泄漏;三是天然支持分布式部署,多个 Agent 节点可共享同一份上下文状态。本项目将诊断报告序列化后存入 Redis,RAG 检索时直接从缓存拉取结构化数据作为知识源,既保证了多轮追问的上下文连贯性,又避免了重复执行诊断流程的计算浪费。
这种"先诊断、再追问"的交互模式,既保证了上下文的连贯性,又避免了每次追问都重新执行完整诊断的资源浪费。
MCP 接口实时诊断
系统还支持通过 MCP 接口 直接与电脑进行交互诊断。用户在聊天界面打开 MCP 开关后,系统就能通过 MCP 协议实时调用本地工具,获取当前系统状态。MCP 采用标准的 JSON-RPC 2.0 作为底层通信格式,工具的输入输出 Schema 通过 JSON Schema 规范描述,这使得模型可以在运行时动态发现并调用新注册的工具,而无需重新训练或修改提示词模板。
在演示中,关闭游戏后再次通过 MCP 进行诊断,系统能够实时反映最新的系统状态,界面上清晰显示了正在调用的工具名称和执行进度。
知识库管理
文件上传与向量化处理
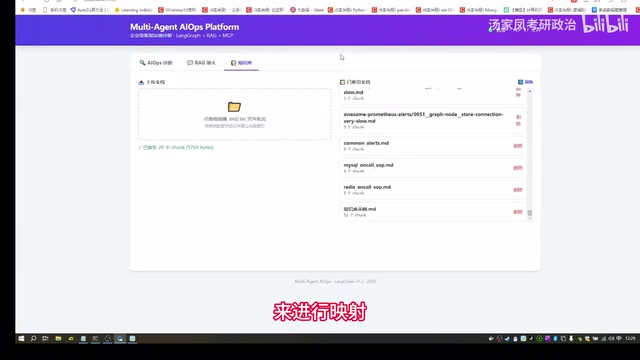
系统内置了知识库上传功能,用户可以将自定义文档上传到系统中。上传流程包含以下要点:
- 上传需要输入密码验证(目前为明文存储,后续可改为加密方式)
- 文件上传后,系统会通过千问的 Embedding 模型将文档内容进行向量化映射
- 上传的知识会被存储为 Markdown 文件,在 RAG 问答时会显示来源信息
Embedding 向量化与千问模型:Embedding(嵌入)是将文本映射为高维稠密向量的技术,语义相近的文本在向量空间中距离更近,这是 RAG 检索的数学基础。阿里云的千问(Qwen)系列提供了专用的 text-embedding 模型,支持中文语义的精准向量化,在 MTEB 中文榜单上表现优异。向量化后的文档片段通常存储在 Faiss、Milvus 或 Chroma 等向量数据库中,检索时通过余弦相似度或内积计算找出最相关的 Top-K 片段。本项目将上传文档转为 Markdown 后再进行向量化,保留了文档结构信息,有助于提升检索的语义准确性,同时在回答中显示来源文件名,增强了结果的可解释性。
检索命中与来源追溯
在 RAG 问答过程中,系统会显示检索的命中率和命中参数,用户可以清楚地看到回答引用了哪些知识库文档。这种「引用溯源」设计是企业级 RAG 系统的重要特性,能够帮助用户判断回答的可信度,也便于在知识库内容有误时快速定位并修正。同时支持对已上传的知识库数据进行删除管理,保持知识库的整洁。
架构优势分析
Token 消耗优化策略
该项目最值得关注的架构设计是其**"先选 Skill,再调工具"**的两阶段策略。传统的多 Agent 系统往往将所有工具描述一次性发送给大模型,导致 Token 消耗巨大。以 GPT-4o 为例,每个工具的 JSON Schema 描述平均占用 200-500 个 Token,当系统集成 50 个工具时,仅工具描述部分就会消耗 1 万至 2.5 万 Token,严重压缩了可用于实际推理的上下文窗口。而本项目通过 Skill 路由层先进行轻量级的意图分类,再加载对应 Skill 下的工具集,从演示效果来看 Token 消耗非常少。
模块化设计与可扩展性
整个系统的模块化程度很高,各层职责清晰:
- Skill 层:可自定义添加新的技能模块,灵活扩展诊断能力
- RAG 层:支持自定义知识库上传和管理,增强问答质量
- MCP 层:通过标准协议接入各类外部工具,实现实时交互
- 缓存层:Redis 提供高效的上下文管理,保障多轮对话连贯性
这种分层架构与软件工程中的「关注点分离」原则高度契合——每一层只需关注自身的核心职责,层与层之间通过定义良好的接口通信,使得单个模块的升级或替换不会影响整体系统的稳定性。
总结
这个开源项目展示了一种将多 Agent、MCP、RAG 和 Skill 路由有机结合的实践方案。其核心价值在于通过 Skill 路由机制实现了工具调用的精准匹配,配合 RAG 的上下文增强和 MCP 的实时交互能力,构建了一个功能完整且资源高效的智能诊断系统。
对于想要学习多 Agent 系统架构设计的开发者来说,这个项目在 Token 优化、模块解耦和交互体验方面都提供了值得借鉴的思路。从更宏观的视角来看,该项目也代表了当前 AI 工程化的一个重要趋势:不再追求单一超级模型解决所有问题,而是通过精心设计的路由与编排机制,让专业化的小模块各司其职,在成本与能力之间找到最优平衡点。
核心要点
- 项目整合了多Agent、MCP、RAG和Skill路由四大核心能力,构建了一个完整的智能诊断系统
- 通过"先选Skill再调工具"的两阶段策略,大幅降低Token消耗,提升系统效率
- RAG聊天模式通过Redis缓存保存诊断报告上下文,支持多轮追问和联网检索
- MCP接口基于JSON-RPC 2.0标准协议,支持实时与本地系统交互,获取最新的电脑状态进行诊断
- 内置知识库管理功能,支持文件上传、千问Embedding向量化和来源追溯
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。