Kimi K2.6开源实测:300个Agent协同的调度能力到底多强
Kimi K2.6以万亿参数MoE架构在Agent调度能力上实现开源最强突破
Kimi K2.6采用万亿参数MoE架构(激活参数仅32B),在Agent调度能力上取得核心突破,可同时调度300个子Agent执行4000步复杂任务,Agent Swarm测试领先GPT-5.4近8个百分点。编程实战能力出色,部署门槛低至2张4090即可LoRA微调。但在纯推理和视觉理解方面仍落后于顶尖闭源模型。
Kimi K2.6模型架构:MoE路线的坚定践行者
从架构参数来看,K2.6延续了MoE(混合专家)路线:总参数量达到万亿级别,但实际激活参数仅32B,上下文窗口支持256K。更重要的是,它原生支持图片和视频输入,具备多模态处理能力。
关于MoE架构:混合专家(Mixture of Experts,MoE)是一种将大型神经网络拆分为多个"专家"子网络的架构范式。在推理时,门控网络(Gating Network)会根据输入动态选择少数几个专家参与计算,而非激活全部参数。这种设计最早可追溯至1991年Jacobs等人的研究,但真正在大语言模型领域爆发是在2022年前后,以Google的Switch Transformer和GLaM为代表。K2.6的万亿总参数、32B激活参数设计,意味着每次推理只调用约3%的参数,推理成本与一个32B稠密模型相当,但模型的知识容量和泛化能力却接近千亿级稠密模型的水平。
这种"大参数、小激活"的设计思路,在推理效率和模型能力之间取得了不错的平衡。对于需要部署在有限硬件上的团队来说,32B的激活参数意味着推理成本远低于同等能力的稠密模型。
Agent调度能力:K2.6真正的核心突破
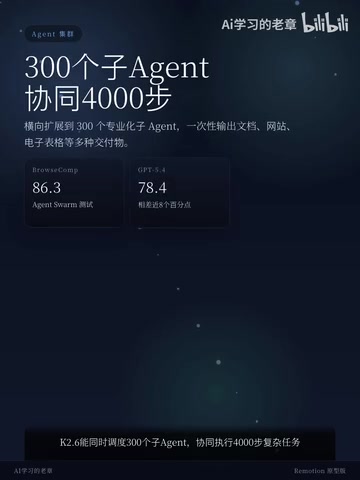
K2.6最值得关注的能力是Agent调度。它能同时调度300个子Agent,将一个大任务拆解成数百条并行子任务——文档处理、网站抓取、表格分析,一口气全部搞定。
理解多Agent协同:AI Agent(智能体)是指能够感知环境、制定计划并自主执行一系列动作以完成目标的AI系统,区别于传统的单轮问答模型。在多Agent协同(Multi-Agent Orchestration)架构中,一个"主控Agent"负责任务分解与调度,将大任务拆解为若干子任务分发给多个"工作Agent"并行执行,最终汇总结果——这与软件工程中的微服务架构、并行计算中的MapReduce思想高度类似。能够稳定调度300个并发子Agent并维持4000步以上的任务链,对模型的工具调用准确性、上下文管理、错误恢复和状态追踪能力都提出了极高要求,这也是为什么多Agent协同能力被视为衡量下一代AI系统的核心指标之一。
在权威的Rios Comp Agent Swarm测试中,K2.6拿下了86.3分,而GPT-5.4只有78.4分,差距接近8个百分点。在AI榜单的评测体系中,这算是相当大的差距,说明K2.6在多Agent协同场景下具备了真正的领先优势。
与前代K2.5相比,进步幅度更是惊人:
- LCP Mark:从29.5飙升到55.9,近乎翻倍
- Apex Agents:提升了2.4倍
这些数据表明,月之暗面在Agent工具调用方面做了大量针对性优化,而不仅仅是简单地扩大模型规模。
编程与实战能力:不只是跑分好看
编程能力同样不含糊。在Terminal Bench 2.0测试中,K2.6打出66.7分,比GPT-5.4和Claude Opus 4.6都略高一筹。

更有说服力的是两个实战案例:
案例一:从零构建推理引擎
K2.6使用Zig语言在Mac上从零编写了一个推理引擎,耗时12小时,经过4000多次工具调用,将吞吐量从15 tokens/s优化到193 tokens/s,比LM Studio还快20%。
关于Zig语言:Zig是一门由Andrew Kelley于2016年发起的系统级编程语言,定位为C语言的现代化替代品。它强调显式内存控制、无隐藏控制流、编译期计算和极致的性能可预测性,没有垃圾回收机制,也没有隐式异常。Zig在AI推理引擎领域逐渐受到关注,原因在于它能够生成高度优化的机器码,同时比C++拥有更简洁的语法和更安全的内存模型。K2.6选择用Zig从零构建推理引擎并非随意为之——能够在12小时内完成从零编写、调试到性能优化的完整工程闭环,并将吞吐量从15 tokens/s提升至193 tokens/s,说明K2.6不仅理解算法逻辑,还具备底层系统优化的工程直觉,这是当前绝大多数AI模型难以企及的能力边界。
案例二:重构金融撮合引擎
K2.6自主重构了一个运行8年的老旧金融撮合引擎,修改了4000行代码,吞吐量直接提升185%。

这两个案例展示的不是简单的代码补全能力,而是端到端的工程执行能力——理解需求、拆解任务、调用工具、迭代优化,整个流程自主完成。
部署门槛:2张4090即可微调,中小团队也能上手
部署方面也有好消息。KTransformers框架支持CPU和GPU混合推理,8张L20加一颗Intel CPU就能跑起来。
更令人惊喜的是LoRA微调的门槛:只需要2张4090就够了,训练吞吐达到44.55 tokens/s。
LoRA微调技术解析:LoRA(Low-Rank Adaptation)是由微软研究院于2021年提出的参数高效微调方法(PEFT)。其核心思想是:大型预训练模型在微调时,权重矩阵的更新量具有低秩特性,因此可以用两个小矩阵的乘积来近似表示权重变化量,而非更新全部参数。以一个维度为4096×4096的权重矩阵为例,全量微调需要更新约1670万个参数,而LoRA在秩为16时只需更新约13万个参数,显存占用降低超过99%。这使得原本需要数十张A100才能完成的微调任务,可以在消费级GPU(如RTX 4090)上实现,让中小团队能够在自有数据上对模型进行领域适配,构建垂直行业应用。

对于中小团队来说,这个硬件门槛已经完全可以接受。两张4090的成本大约在3-4万元人民币,相比动辄需要数十张A100的全量训练方案,LoRA微调让更多团队有机会基于K2.6构建自己的垂直应用。
不足与局限:客观看待K2.6的差距
当然,K2.6也有明显的短板需要正视:
- 纯推理任务:在不涉及Agent调度的纯推理场景下,K2.6仍然落后于GPT-5.4和Gemini等闭源模型
- 视觉理解:虽然支持多模态输入,但视觉理解能力与顶尖模型仍有差距
- 部署成本:万亿参数的全量部署成本依然不低,混合推理方案虽然降低了门槛,但对算力的要求仍然不可忽视
- 许可条款:K2.6采用Modified MIT License,商用时需要仔细审查许可条款中的限制条件
关于Modified MIT License:MIT License是开源世界中最宽松的许可证之一,允许商业使用、修改和分发,唯一要求是保留版权声明。然而,"Modified MIT License"意味着在标准MIT条款基础上附加了额外限制,具体内容因项目而异。企业用户在商用前需重点关注:是否有用户规模限制、是否禁止特定用途(如军事、监控)、是否要求署名或开放衍生模型权重等。这些条款直接影响企业的合规风险评估,是商业落地前不可忽视的法律尽调环节。
总结:Kimi K2.6是Agent赛道的开源标杆
综合来看,Kimi K2.6的定位非常清晰——它不追求在所有维度上超越闭源模型,而是在Agent调度和工具调用这个特定赛道上做到了开源最强。300个Agent协同、4000步复杂任务执行、近乎翻倍的版本迭代提升,这些数据共同指向一个结论:如果你在做AI Agent相关的产品,K2.6是目前开源世界中最值得认真评估的选择。
月之暗面选择在Agent能力上重点突破,而非追求全面超越,这种策略在当前开源与闭源竞争的格局下是务实且聪明的。毕竟,对于大多数实际应用场景来说,"能干活"比"更聪明"更重要。
核心要点
- Kimi K2.6在Agent调度能力上实现突破,可同时调度300个子Agent协同执行4000步复杂任务,Agent Swarm测试86.3分领先GPT-5.4近8个百分点
- 编程实战能力出色,用Zig语言从零构建推理引擎并将吞吐优化至193 tokens/s,自主重构8年老金融引擎提升吞吐185%
- 部署门槛大幅降低,LoRA微调仅需2张4090,KTransformers支持CPU+GPU混合推理,对中小团队友好
- 相比K2.5版本进步显著,LCP Mark近乎翻倍,Apex Agents提升2.4倍,体现了Agent工具调用的针对性优化
- 纯推理和视觉理解仍落后闭源模型,全量部署成本较高,商用需注意Modified MIT License条款限制
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。