LangChain 1.2 Agent记忆机制:短期与长期记忆实战详解
解析AI Agent默认无记忆的原因及短期/长期记忆机制
文章基于LangChain 1.2,通过对话实验直观展示默认Agent因LLM无状态特性而缺乏记忆能力的问题,并详细介绍了短期记忆(会话内上下文拼接,受上下文窗口限制)和长期记忆(基于向量数据库的跨会话持久化存储)两种解决方案的原理与适用场景。
为什么你的Agent总是'失忆'?
在构建AI Agent时,很多开发者都踩过同一个坑:Agent无法记住之前的对话内容。你告诉它"我叫张三",下一轮对话再问"我叫什么",它却一脸茫然。这并不是模型能力不够,而是Agent的记忆机制没有正确配置。
本文基于LangChain 1.2版本,从零开始讲解Agent的短期记忆与长期记忆机制。你将了解默认Agent为什么没有记忆能力,以及如何通过上下文管理为Agent赋予"记住对话"的能力。
LangChain 1.2中Agent的基础创建方式
在LangChain 1.2中,创建Agent的方式相比旧版本有了明显简化。核心函数是create_agent,通过它可以快速搭建一个具备基本对话能力的Agent。
创建Agent的三个核心要素
Agent的核心能力可以归纳为三点:
- 大模型推理能力:Agent底层依赖LLM进行推理和决策
- 工具调用能力:通过
tools参数指定Agent可使用的外部工具 - 记忆功能:Agent能够记住历史对话内容(本文重点讲解)
创建一个基础Agent的代码结构如下:
from langchain import create_agent
# 指定模型和工具,创建Agent
agent = create_agent(
model=deep_seek_model, # 底层使用的LLM
tools=[...] # 可调用的工具列表
)
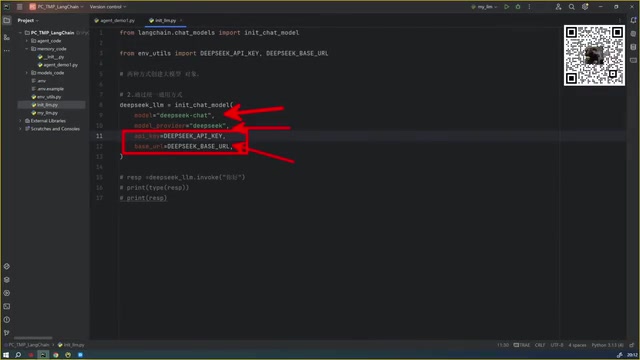
其中模型的创建使用init_chat_model方法,需要指定模型名称、供应商、API Key和Base URL等参数。这些配置通常放在环境变量中统一管理。
无记忆Agent的问题:一个直观的对话实验
基本调用方式
创建好Agent后,通过agent.invoke()方法与其对话:
# 第一次对话
response = agent.invoke({"role": "user", "content": "我叫张三,你是谁?"})
print(response["messages"][-1].content)
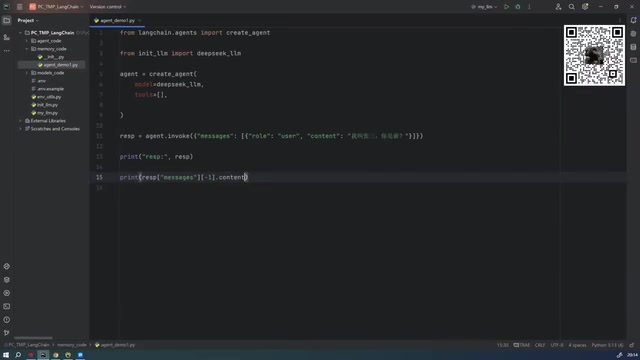
Agent的返回结构中包含messages列表,其中按顺序存放了用户的提问(Human Message)和AI的回复(AI Message)。要获取最终回复内容,只需取messages[-1].content即可。
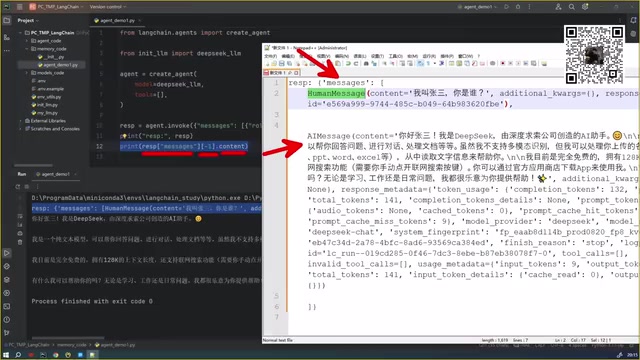
记忆缺失的直观表现
关键问题出现在第二次对话时:
# 第一次对话
response1 = agent.invoke("我叫张三,你是谁?")
print(response1["messages"][-1].content)
# 输出:你好张三!我是...
print("-" * 50)
# 第二次对话
response2 = agent.invoke("我叫什么名字?")
print(response2["messages"][-1].content)
# 输出:我无法知道你的名字
尽管两次调用在同一段代码中、程序并未终止,但Agent依然无法回忆起你刚才说过的名字。第一次对话它明明回复了"你好张三",第二次却说"我无法知道你的名字"。
默认Agent为什么没有记忆?
要理解这个问题,需要先理解大语言模型的本质:LLM是无状态的(Stateless)推理函数。每次API调用都是完全独立的推理过程,模型本身不存储任何会话信息,这与传统数据库或有状态服务有根本区别。所谓"记忆",在技术实现上其实是将历史对话文本拼接到当前请求的Prompt中,让模型在同一次推理里"看到"历史内容,从而产生记住的效果。
因此,默认创建的Agent没有配置任何记忆机制。每次invoke调用对Agent来说都是一次全新的、独立的对话,前一次对话的上下文信息不会自动传递到下一次调用中。这就像一个失忆的人,每次见面都不记得之前发生过什么。要解决这个问题,就需要显式地为Agent引入记忆机制。
短期记忆与长期记忆:两种记忆机制详解
LangChain中的Agent记忆机制分为两大类,适用于不同的应用场景。
短期记忆(Short-term Memory)
短期记忆也称为会话记忆或上下文记忆,主要特点包括:
- 生命周期短:仅在当前会话期间有效,会话结束即丢失
- 容量有限:通常受限于LLM的上下文窗口大小(如4K、8K、128K tokens)
- 实现方式:将历史对话消息作为上下文传入每次请求
短期记忆解决的核心问题是:在一次连续对话中,Agent能记住前面说过的内容。比如多轮问答、上下文理解等场景。
值得注意的是,上下文窗口(Context Window)是LLM单次能处理的最大Token数量。早期GPT-3只有4K tokens,现代模型如GPT-4 Turbo支持128K tokens,Gemini 1.5 Pro甚至达到100万tokens。随着对话轮次增加,历史消息会不断累积,逐渐逼近窗口上限。在实际工程中,通常需要配合消息截断(只保留最近N轮对话)或摘要压缩(用LLM将早期对话压缩成摘要)等策略来管理上下文长度,避免超出限制导致报错或性能下降。
长期记忆(Long-term Memory)
长期记忆则是跨会话持久化的记忆,适用于需要"认识用户"的场景:
- 持久存储:即使程序重启、服务器重启,记忆依然存在
- 容量更大:通常借助外部存储系统(数据库、向量库、文件系统等)
- 选择性记忆:不是记住所有对话内容,而是提取关键信息进行存储
长期记忆让Agent能够跨越多次会话,记住用户的偏好、历史交互记录等重要信息。例如,用户上周告诉Agent自己喜欢Python,下周再来对话时Agent仍然知道这个偏好。
在技术实现上,长期记忆通常借助向量数据库(如Chroma、Pinecone、Weaviate、Milvus等)来实现语义检索。其核心原理是:对话内容首先被Embedding模型(如OpenAI的text-embedding-ada-002)转换为高维向量后存入数据库;检索时,将当前问题同样转为向量,通过余弦相似度(Cosine Similarity)找到最相关的历史记忆片段,再将这些片段注入到当前请求的Prompt中。这种方式比传统关键词匹配更智能,能够理解语义层面的相似性——即使用词不同,只要含义相近也能被检索到。
Agent开发中的实用注意事项
返回结构的正确解析
Agent的返回值是一个包含messages列表的字典,列表中按顺序存放了:
- 用户输入的Human Message
- 中间可能的工具调用消息(Tool Message)
- 最终的AI Message(回复内容)
获取最终回复的标准写法:
final_answer = response["messages"][-1].content
LangChain版本兼容性说明
目前很多企业仍在使用LangChain 1.0之前的版本,而本教程基于1.2版本。新版本的create_agent API更加简洁直观,但记忆机制的核心概念是相通的。如果你的项目使用旧版本,Agent的创建方式会有所不同,但短期记忆和长期记忆的实现原理一致。
总结:从理解'失忆'到构建记忆能力
本文通过一个简单的对话实验,直观展示了默认Agent缺乏记忆能力的问题。核心要点回顾:
- LangChain 1.2中使用
create_agent可以快速创建Agent - 默认Agent每次调用都是独立对话,不会自动保留上下文
- 要实现连续对话能力,必须显式添加记忆机制
- 记忆分为短期记忆(会话内上下文管理)和长期记忆(跨会话持久化存储)两种
- 短期记忆受限于LLM上下文窗口,需配合截断或摘要策略管理长度
- 长期记忆依赖向量数据库实现语义检索,能跨会话保留关键用户信息
理解了"为什么Agent没有记忆"这个根本问题,才能更好地掌握后续如何为Agent添加记忆功能。这是构建真正实用的AI Agent不可跳过的基础一步。
核心要点
- LangChain 1.2中通过create_agent函数创建Agent,需指定模型和工具参数
- 默认创建的Agent没有记忆机制,每次invoke调用都是独立的新对话
- Agent返回结构中通过messages[-1].content获取最终AI回复内容
- 记忆机制分为短期记忆(会话内上下文)和长期记忆(跨会话持久化存储)
- 短期记忆受LLM上下文窗口限制,长期记忆依赖向量数据库实现语义检索
- Agent三大核心能力:大模型推理、工具调用、记忆功能
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。