LangChain 1.3 事件流实战:4大视角实时监控Agent运行全过程
LangChain 1.3事件流V3让Agent执行过程从黑箱变为实时可观测的透明箱。
LangChain 1.3引入事件流V3机制,通过类型化投影和简化解析两大升级,提供模型输出、工具调用准备、工具执行详情、状态变化四个监控视角,全方位透视Agent运行过程。该机制支持实时流式输出、推理过程展示、复杂Agent调试及精细化Token成本控制,将Agent从不可观测的黑箱变为透明可调试的系统。
在 LangChain 1.3 之前,使用 Agent 的体验就像开盲盒——输入一个问题,然后漫长等待,中间发生了什么完全不可知。这种黑箱式的交互方式在调试复杂多步 Agent 时尤其令人头疼。
Agent(智能体)是 LLM 应用中的核心架构模式,它允许大语言模型自主决定何时调用外部工具、如何分解复杂任务。与简单的 Prompt-Response 模式不同,Agent 可能经历多轮推理循环(ReAct 循环),每轮都包含"思考-行动-观察"三个阶段。这种多步骤的自主决策机制虽然强大,但也意味着一次用户请求背后可能隐藏着 5-10 次甚至更多的 LLM 调用和工具执行。在没有可观测性(Observability)支持的情况下,开发者只能看到最终输出,无法判断中间某一步是否走偏、是否产生了不必要的工具调用,这在生产环境中是不可接受的。业界对 AI 可观测性的重视程度正在快速提升,LangSmith、Phoenix、Helicone 等专门的 LLM 监控平台也应运而生。
LangChain 1.3 版本带来的事件流(Event Stream)机制彻底改变了这一局面。它相当于给 Agent 装上了一个实时直播画面,让每一步推理、每一次工具调用都清晰可见。事件流本质上是基于服务器推送事件(Server-Sent Events, SSE)或异步生成器(Async Generator)模式实现的。与传统的请求-响应模式不同,事件流建立的是一个持久化的单向数据通道,服务端可以在任意时刻向客户端推送结构化事件。在 LangChain 的实现中,Agent 执行图(基于 LangGraph 的有向无环图)中的每个节点在执行时都会发射对应的事件,这些事件被序列化后通过流式通道传递给消费者。这种设计借鉴了响应式编程(Reactive Programming)的思想,将 Agent 的执行过程建模为一个可订阅的事件序列,消费者可以选择性地监听自己关心的事件类型。
事件流V3:类型化投影与简化解析两大核心升级
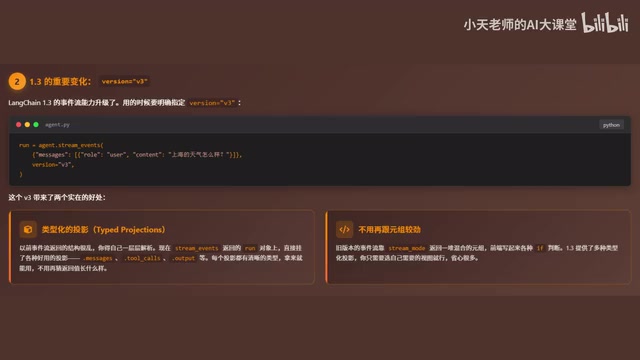
LangChain 1.3 中的事件流迎来了重大升级,需要显式指定 version="v3" 才能启用新功能。V3 版本带来了两个关键改进:
第一,类型化投影(Typed Projections)。 以前事件流返回的是复杂的嵌套结构,开发者需要自己解析和猜测数据格式。现在可以直接通过 run 对象访问 messages、tool_cause、output 等属性,所有类型都有明确定义,开箱即用。
类型化投影的概念来源于数据库领域的投影操作(Projection),即从完整的数据集中选取特定字段子集。在 V2 及更早版本中,事件流返回的是通用的字典结构,开发者需要通过字符串键名手动提取数据,这不仅容易出错,还无法获得 IDE 的自动补全和类型检查支持。V3 版本引入了强类型的数据类(dataclass)或 Pydantic 模型来封装每种事件,使得 Python 的类型检查器(如 mypy、pyright)能够在编码阶段就发现潜在的属性访问错误。这种从弱类型到强类型的演进,是 LangChain 框架走向生产级成熟度的重要标志。
第二,告别繁琐的元组处理。 旧版本需要使用 stream_mode 配合大量 if-else 判断来解析数据,而 V3 版本只需选择想要的投影类型,就能方便地获取目标数据。
四大监控视角:全方位透视Agent运行
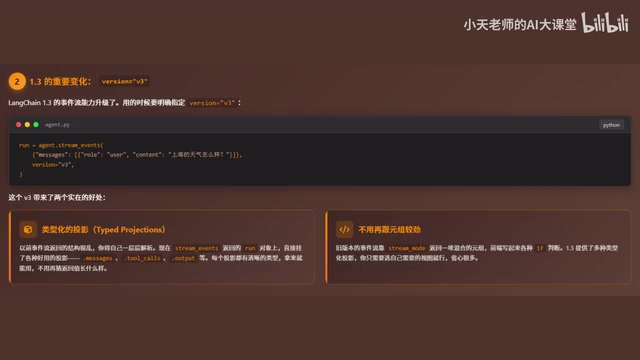
事件流提供了四个不同层面的监控视角,覆盖了 Agent 运行的完整生命周期。
视角一:模型正在说什么(run.messages)
这是最直观的视角,模型的回答会一个字一个字地实时返回。大语言模型的文本生成本质上是一个自回归(Autoregressive)过程——模型每次只预测下一个 Token,然后将其拼接到已有序列中继续预测。OpenAI、Anthropic 等 API 提供商利用这一特性,支持在每个 Token 生成后立即通过流式接口返回,而不必等待整个序列生成完毕。对于一个 500 Token 的回答,如果首 Token 延迟(Time to First Token, TTFT)为 500ms,完整生成需要 10 秒,那么流式输出可以让用户在 0.5 秒后就开始看到内容,而非干等 10 秒。这种感知延迟的大幅降低对用户体验至关重要,也是现代 AI 聊天产品的标配能力。
run.messages 包含几个核心字段:
- text:文本增量片段,用于实现打字机效果
- reasoning:大模型的推理过程(目前仅 OpenAI O 系列支持)。OpenAI O 系列(如 o1、o1-mini、o3 等)是 OpenAI 推出的专注于复杂推理的模型系列。与 GPT-4 等通用模型不同,O 系列模型在生成最终答案前会进行显式的"链式思考"(Chain of Thought),这个思考过程会消耗额外的推理 Token(reasoning tokens)。OpenAI 的 API 允许开发者获取这些推理 Token 的内容,这为开发者提供了前所未有的模型内部思考可见性。不过需要注意的是,推理 Token 虽然不会出现在最终输出中,但仍然计入 Token 用量和费用,因此在成本控制场景下需要特别关注。
- tool_cause:工具调用参数的增量,实时展示模型生成工具名称和参数的过程
- output:该条消息最终的完整内容
视角二:工具调用准备阶段(message.tool_cause)
当 Agent 决定调用外部工具时,会经历两个阶段:
- 模型逐 token 生成工具调用的参数块,你可以通过
message.tool_cause实时观察参数的生成过程 - 参数确定后,系统才会真正执行工具
说个细节,message.tool_cause 提供了 get() 方法,可以获取最终确定的完整工具调用对象。它本质上是工具调用动作的组成部分,而不仅仅是旁观者。
视角三:工具执行详情(run.tool_cause)
这个视角让你看到工具真正运行时的整个生命周期:
- 具体是哪个工具被调用
- 输入参数是什么
- 输出片段(如果支持流式返回)
- 完整输出结果
- 是否报错及错误信息
视角四:状态变化与最终输出(run.values / run.output)
run.values 返回每一步执行后 Agent 的状态快照,让你清晰看到状态随执行步骤的变化轨迹。这一功能与 LangGraph 的架构密切相关。LangGraph 是 LangChain 生态中用于构建有状态、多步骤 Agent 的框架,它将 Agent 的执行流程建模为一个状态图(State Graph)。图中的每个节点代表一个执行步骤(如 LLM 调用、工具执行、条件判断),边代表步骤之间的转换逻辑,而状态(State)则是在节点之间传递的共享数据结构。每当一个节点执行完毕,状态会被更新并传递给下一个节点。run.values 正是对这些状态转换的快照记录,它使得开发者可以像调试状态机一样调试 Agent,清晰地看到每一步执行后数据的变化情况。
run.output 则是整个 Agent 运行结束后的最终返回值。
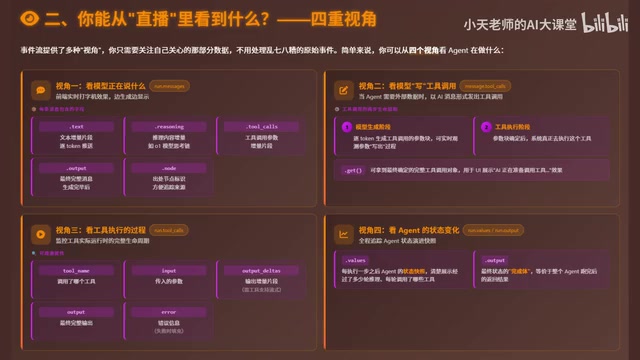
动手实践:用事件流构建天气查询Agent
以一个查询天气的 Agent 为例,来看看事件流的具体实现方式。
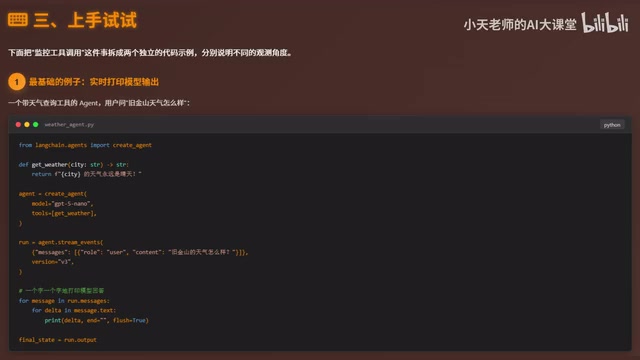
核心步骤如下:
- 定义工具函数
getWeather - 通过
create_agent将工具和模型绑定 - 调用
agent.stream_events,指定version="v3" - 遍历
run.messages,逐个打印 text 增量
实时查看工具调用参数的生成过程,只需监听 message.tool_cause 事件,每当有新的 chunk 到来就打印输出。要获取最终完整的工具调用信息,使用 message.tool_cause.get() 方法即可。
监控工具执行的完整生命周期也很简单:遍历 run.tool_cause,对每个 call 打印工具名、输入参数、输出片段、最终输出和错误信息。
场景选择指南:不同需求匹配不同投影
面对不同的开发场景,选择合适的投影方式至关重要:
| 场景 | 推荐投影 |
|---|---|
| 聊天界面打字机效果 | message.text |
| 展示模型推理过程 | message.reasoning |
| 实时查看工具参数生成 | message.tool_cause |
| 获取工具执行结果 | run.tool_cause |
| 统计 Token 用量/成本控制 | message.usage |

实际应用:体验提升与成本控制
即时反馈的聊天体验
通过监听 run.messages 循环中的 text 增量,前端每接收到一个 token 就立刻追加到屏幕上,用户几乎感觉不到思考延迟。这种流式输出的体验,比等待完整响应后一次性展示要好得多。
推理过程的优雅展示
可以将 reasoning 内容单独提取,用折叠面板等特殊样式展示。感兴趣的用户展开查看 AI 的思考步骤,不感兴趣的用户直接看答案,两不耽误。
复杂Agent的高效调试
对于多工具、多轮推理的复杂 Agent,通过查看每一步的状态变化,可以清晰追踪经过了多少轮、每轮调用了哪些工具。工具调用失败时,run.tool_cause 中的 error 字段能直接定位问题所在,省去大量排查时间。
精细化Token成本控制
message.usage 投影可以获取每次模型调用的 Token 使用情况,具体支持以下场景:
- 监控长期运行服务的用量趋势
- 设置预算阈值预警,避免超支
- 按终端用户统计消耗,方便多租户场景下的成本分摊
在 SaaS(软件即服务)模式下,多个终端客户(租户)共享同一套 Agent 基础设施,但每个租户的 LLM 调用量差异巨大。如果不进行精细化的用量追踪,服务提供商要么只能采用粗粒度的按月订阅定价(可能导致亏损),要么无法为大客户提供有竞争力的阶梯价格。message.usage 投影返回的数据通常包括 prompt_tokens(输入 Token 数)、completion_tokens(输出 Token 数)和 total_tokens(总 Token 数),结合各模型的单价(如 GPT-4o 的输入价格为 $2.50/百万 Token,输出为 $10.00/百万 Token),可以精确计算每次调用的成本。将这些数据按租户 ID 聚合后,就能实现按实际用量计费(Pay-as-you-go)的商业模式。
总结
LangChain 1.3 的事件流机制将 Agent 从黑箱变成了透明箱。四个监控视角——模型输出、工具调用准备、工具执行、状态变化——覆盖了 Agent 运行的完整链路。
无论是构建流畅的聊天界面、调试复杂的多步 Agent,还是进行精细化的 Token 成本控制,事件流 V3 都提供了强大而直观的支持。如果你正在使用 LangChain 构建 Agent 应用,升级到 1.3 并启用事件流 V3,会让开发和调试体验有质的提升。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。