LangChain对话记忆实战:四种记忆类型原理与最新实现
系统梳理四种对话记忆类型原理及LangChain新版实现方式
文章阐述了对话记忆对AI聊天机器人的核心作用——因为LLM本身无状态,需要记忆组件将历史消息注入Prompt。系统介绍了四种经典记忆类型:Buffer(完整保留)、Buffer Window(滑动窗口)、Summary(摘要压缩)和Summary Buffer(混合方式),分析了各自的优缺点和适用场景,并展示了在LangChain 0.3中通过RunnableWithMessageHistory实现这些记忆类型的方法和工程优化建议。
为什么对话记忆如此重要
对话记忆(Conversational Memory)是聊天机器人和AI Agent的核心组件。没有它,模型只能响应最近一条消息,完全无法理解上下文——这意味着它根本不具备"对话"能力。
理解这一点需要先认清大语言模型的本质:LLM本身是无状态的(stateless)——每次API调用都是独立的,模型不会自动记住上一轮说了什么。对话记忆组件的核心职责,就是在每次调用时将历史消息重新注入到Prompt中,让模型"看起来"拥有记忆。这也意味着,所谓的记忆管理,本质上是一个token预算分配问题:如何在有限的上下文窗口(Context Window)内,最大化保留对当前回复有价值的历史信息。主流模型的上下文窗口从早期的4K token已扩展至128K甚至更长,但在高并发生产环境中,token消耗直接对应延迟与成本,记忆策略的选择依然至关重要。
然而,LangChain在0.3版本中已经弃用了早期的记忆组件(如ConversationBufferMemory、ConversationChain等),转而推荐使用基于LCEL的RunnableWithMessageHistory来实现对话记忆。本文将系统梳理四种经典记忆类型的原理,并展示如何在最新版LangChain中正确实现它们。
四种对话记忆类型概览
1. 对话缓冲记忆(Conversation Buffer Memory)
这是最简单直观的记忆类型:所有消息以列表形式存储,需要时全部返回。没有任何压缩或裁剪,完整保留每一条交互记录。
优点: 信息零损失,实现简单 缺点: 随着对话变长,token消耗线性增长,延迟和成本都会上升
在当前大模型普遍支持高上下文窗口的背景下,如果你预期对话不会太长,Buffer Memory其实是最实用的选择。
2. 对话缓冲窗口记忆(Conversation Buffer Window Memory)
在Buffer Memory基础上增加了一个参数k,只返回最近的k条消息。超出窗口的历史消息会被直接丢弃。
优点: token消耗可控,延迟稳定 缺点: 可能丢失关键信息(比如用户在对话开头自我介绍的名字)
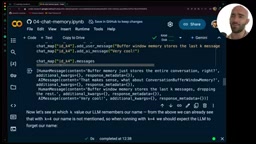
你可能没注意到,原版LangChain中k=4实际保存的是最近4对交互(即8条消息),这种设计容易造成混淆。在新版实现中,建议让k直接对应消息条数,语义更清晰。
3. 对话摘要记忆(Conversation Summary Memory)
这种类型不直接存储原始消息,而是通过LLM将历史交互压缩为一段摘要。每当新消息加入时,摘要会被迭代更新。
优点: 随着对话变长,token消耗增长缓慢,能保留全局信息 缺点: 每次更新摘要都需要额外的LLM调用,短对话反而更费token;信息压缩不可避免地会丢失细节
这里的"额外LLM调用"在工程上意味着什么?每次更新摘要,系统需要将当前摘要与新消息一并发送给LLM,生成新摘要。这不仅增加了响应延迟(通常额外100–500ms),还产生了额外的token费用。以GPT-4o为例,若每轮对话都触发摘要,一次100轮的长对话可能产生数十次额外调用,成本不可忽视。因此,批量触发摘要(如每积累N条消息才压缩一次)是生产环境中降低成本的关键策略,详见后文工程实践部分。
一个重要的工程细节:在传递消息给摘要LLM时,应该只传递message.content而非整个消息对象,否则会把token使用量等元数据也混入摘要中。
4. 对话摘要缓冲记忆(Conversation Summary Buffer Memory)
这是前两种方式的混合体:保留最近k条消息的完整内容(缓冲区),同时将超出缓冲区的历史消息压缩为摘要。
优点: 兼顾近期交互的高分辨率和历史信息的全局覆盖 缺点: 实现复杂度最高,需要精心调优摘要的提示词
新版LangChain的实现方式
核心组件:RunnableWithMessageHistory
LCEL(LangChain Expression Language)是LangChain在0.1版本引入的声明式链式调用语法,通过管道符|将各组件串联,使数据流向清晰可读。RunnableWithMessageHistory正是LCEL生态中专门处理有状态对话的包装器——它在每次invoke前自动加载历史消息、在invoke后自动保存新消息,将状态管理与业务逻辑彻底解耦。这一设计比旧版ConversationChain更符合函数式编程思想,也更易于单元测试和横向扩展。
在LangChain 0.3中,所有记忆类型都通过RunnableWithMessageHistory来实现。其核心思路是:
- 定义Prompt模板:使用
MessagesPlaceholder标记历史消息的插入位置 - 构建Pipeline:将Prompt与LLM通过LCEL链接
- 实现
get_session_history函数:返回特定session的消息历史对象 - 用
RunnableWithMessageHistory包装Pipeline
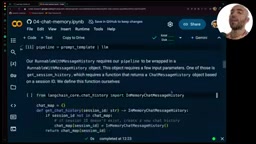
关键配置项包括:
history_messages_key:必须与MessagesPlaceholder中的变量名一致input_messages_key:对应用户输入的变量名session_id:用于隔离不同用户/对话的唯一标识
自定义记忆类型的实现模式
对于Buffer Memory,直接使用内置的InMemoryChatMessageHistory即可。但对于Window Memory、Summary Memory等,需要继承BaseChatMessageHistory并实现三个核心接口:
class CustomMessageHistory(BaseChatMessageHistory):
messages: list # 消息存储
def add_messages(self, messages): # 添加消息的逻辑
pass
def clear(self): # 清空历史
pass
如果自定义类引入了新参数(如k或llm),需要通过history_factory_config中的ConfigurableFieldSpec将其暴露给LangChain,以便在invoke时动态传入。
如何选择合适的记忆类型
通过LangSmith的监控数据可以直观对比不同记忆类型的token消耗:
| 记忆类型 | 短对话token消耗 | 长对话token消耗 | 信息保留度 |
|---|---|---|---|
| Buffer | 低 | 高(线性增长) | 100% |
| Buffer Window | 固定 | 固定 | 低(丢弃旧消息) |
| Summary | 较高(额外LLM调用) | 中等(增长缓慢) | 中等 |
| Summary Buffer | 较高 | 中等 | 较高 |
选择建议:
- 对话预期较短(<20轮):直接用Buffer Memory
- 对话可能很长但不需要早期细节:Buffer Window Memory
- 对话很长且需要全局上下文:Summary Memory
- 对话很长且需要兼顾近期细节和全局上下文:Summary Buffer Memory
工程实践要点
在生产环境中实现对话记忆时,有几个值得注意的优化点:
- 批量摘要而非逐条摘要:不要每超出2条消息就触发一次摘要,建议设置较大的缓冲区(如20条),超出后一次性摘要10条,减少LLM调用次数
- 控制摘要长度:在摘要提示词中明确限制输出长度(如"保持在一个简短段落内
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。