LangChain LCEL表达式语言详解:管道操作符、RunnableLambda与并行执行实战
深入解析LangChain LCEL的核心概念与实际应用
本文介绍了LangChain Expression Language(LCEL)如何借鉴函数式编程的函数组合思想,通过管道操作符(|)替代传统LLMChain实现更灵活的链式调用。文章详解了管道操作符基于Python __or__ 魔术方法的底层原理,以及RunnableLambda、RunnableParallel和RunnablePassThrough三个核心组件在文本后处理和多源RAG检索中的实际应用。
引言
LangChain Expression Language(LCEL)是LangChain框架中构建链式调用的现代方式,它取代了传统的LLMChain方法,提供了更灵活、更直观的链式组合能力。LCEL的设计哲学深度借鉴了函数式编程中的「函数组合」(Function Composition)思想——在数学和函数式编程中,函数组合指将多个函数串联,使前一个函数的输出成为后一个函数的输入,形如 f(g(x))。Haskell、Scala等函数式语言中的管道操作符(如 |> 或 .)正是这一思想的体现。LCEL将这种范式引入LLM应用开发,使每个处理步骤(Prompt格式化、模型推理、输出解析)都成为纯粹的数据变换函数,彼此解耦、独立可测。本文将深入解析LCEL的核心概念,包括管道操作符的底层原理、RunnableLambda、RunnableParallel和RunnablePassThrough的实际应用,帮助你快速上手LCEL并构建复杂的LLM应用链。
从传统LLMChain到LCEL的演进
传统方式的局限性
在LangChain早期版本中,构建链式调用需要使用LLMChain类。典型用法是将Prompt Template、LLM和Output Parser分别定义,然后作为参数传入LLMChain:
chain = LLMChain(prompt=prompt, llm=llm, output_parser=output_parser)
chain.invoke({"topic": "RAG"})
这种方式存在两个主要问题:一是参数受限于预定义的接口,灵活性不足;二是该API已被官方标记为deprecated(弃用),后续版本将不再维护。
LCEL的简洁表达
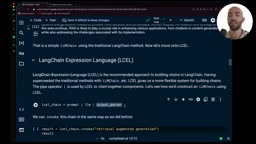
相比之下,LCEL使用管道操作符(|)将组件串联起来,语法极其简洁:
chain = prompt | llm | output_parser
chain.invoke({"topic": "RAG"})
管道操作符的语义非常直观:将左侧组件的输出作为右侧组件的输入。这种声明式的写法让整条链的数据流向一目了然,也更符合函数式编程的思维方式。
管道操作符的底层原理
Python魔术方法:运算符重载的秘密
Python的魔术方法(Magic Methods,也称Dunder Methods)是Python数据模型的核心机制,允许开发者为自定义类重载内置运算符的行为。__or__ 对应按位或运算符 |,当Python解释器遇到 a | b 时,实际执行的是 a.__or__(b)。LangChain正是利用这一机制,让所有继承自 Runnable 基类的组件都能用 | 符号自然串联。类似地,__add__ 对应 +,__mul__ 对应 *,__getitem__ 对应 []。这种运算符重载机制使得领域特定语言(DSL)的构建成为可能——LCEL本质上就是一种嵌入在Python中的链式调用DSL,让开发者能以接近自然语言的方式描述数据处理流程。
手动实现一个Runnable类
为了理解其工作原理,我们可以自己实现一个简化版的Runnable类:
class Runnable:
def __init__(self, func):
self.func = func
def invoke(self, input):
return self.func(input)
def __or__(self, other):
def chained(input):
return other.invoke(self.invoke(input))
return Runnable(chained)
核心逻辑在于__or__方法:它创建一个新的Runnable,该Runnable先执行当前函数,再将结果传给下一个Runnable。这就是LCEL链式调用的本质——通过函数组合实现数据的逐步变换。
链式执行示例
定义三个简单函数并用管道操作符链接:
add_five = Runnable(lambda x: x + 5)
sub_five = Runnable(lambda x: x - 5)
mul_five = Runnable(lambda x: x * 5)
chain = add_five | sub_five | mul_five
chain.invoke(3) # 3+5=8, 8-5=3, 3*5=15 → 输出15
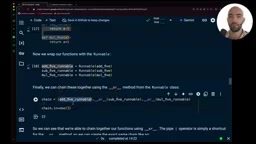
输入3,经过加5得8,减5得3,乘5得15。这个简单示例清晰展示了管道操作符如何将多个操作串联成一条数据处理流水线。
Runnable Lambda:将任意函数变为可组合组件
LangChain提供的RunnableLambda本质上就是上面我们手动实现的Runnable类的官方版本。它可以将任意Python函数包装为LCEL兼容的组件,从而无缝接入链式调用。
实际应用:文本后处理链
下面这个示例展示了如何在LLM生成结果之后追加自定义的文本处理逻辑:
from langchain_core.runnables import RunnableLambda
def replace_word(text):
return text.replace("AI", "Skynet")
chain = prompt | llm | output_parser | RunnableLambda(replace_word)
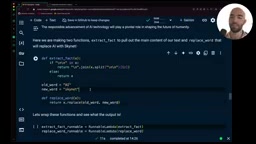
这个链先让LLM生成一份关于AI的报告,然后通过RunnableLambda将所有"AI"替换为"Skynet"。虽然是个趣味示例,但它展示了一个重要能力:任何Python函数都可以通过RunnableLambda无缝接入LCEL链中,极大地扩展了链的处理能力。
多参数函数的处理技巧
需要注意的是,LCEL中每个Runnable的输入都是单一对象。如果你的函数需要多个参数,推荐的做法是让函数接收一个字典,在函数内部进行解包:
def multi_param_func(inputs):
text = inputs["text"]
word = inputs["word"]
return text.replace(word, "replaced")
这种模式在实际项目中非常常见,尤其是在需要同时传递上下文和用户输入的场景下。
Runnable Parallel与PassThrough:并行执行的威力
应用场景:多源RAG检索
检索增强生成(Retrieval-Augmented Generation,RAG)是当前LLM应用中最主流的架构模式之一。其核心思想是在LLM生成回答之前,先从外部知识库中检索与问题相关的文档片段,将其作为上下文注入Prompt,从而弥补LLM知识截止日期的局限并减少幻觉。向量数据库(如Chroma、Pinecone、Weaviate)是RAG的关键基础设施,它将文本转化为高维向量并支持语义相似度检索。
在实际的RAG应用中,我们经常需要从多个知识库同时检索信息。这正是RunnableParallel和RunnablePassThrough的用武之地。
假设我们有两个向量数据库:
- Vector Store A:存储Deep Seek R3的发布时间信息
- Vector Store B:存储Deep Seek V3的架构参数信息
构建并行检索链
from langchain_core.runnables import RunnableParallel, RunnablePassThrough
retrieval = RunnableParallel(
context_a=retriever_a,
context_b=retriever_b,
question=RunnablePassThrough()
)
chain = retrieval | prompt | llm | output_parser
这段代码中有两个关键组件:
- RunnableParallel:同时执行两个检索器,分别从不同数据源获取上下文信息,并将结果合并为一个字典输出
- RunnablePassThrough:将用户的原始问题原封不动地传递到下一步,不做任何修改
当我们提问"What architecture does the model Deep Seek released in December use?"时,LLM需要综合两个数据源的信息才能给出完整回答。值得一提的是,DeepSeek V3采用的是混合专家模型(Mixture of Experts,MoE)架构——与传统密集模型(每次推理激活全部参数)不同,MoE模型包含多个「专家」子网络和一个路由器(Router),每次推理时路由器只激活少数几个专家处理当前输入。这使得模型可以拥有极大的参数总量(671B),但实际计算量远小于同等规模的密集模型,在保持高性能的同时显著降低了推理成本。
最终输出:"Deep Seek V3 model released in December 2024 is a Mixture of Experts model with 671 billion parameters.
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。