LangChain少样本提示词模板实战:FewShotPromptTemplate完整教程
LangChain少样本提示词模板通过示例引导大模型减少幻觉
文章介绍了LangChain的FewShotPromptTemplate,通过在提示词中嵌入少量示例来引导大模型输出,降低幻觉率。详解了核心参数(Examples/ExampleSelector、ExamplePrompt、Prefix、Suffix等),区分了文本补全模型和聊天模型的不同实现方式,并展示了批量文件重命名的实用案例。
为什么需要少样本提示词模板
大语言模型在实际应用中经常出现输出不准确、产生幻觉的问题。所谓幻觉(Hallucination),是指模型生成看似合理但实际不正确或无中生有的内容。幻觉产生的根本原因在于模型本质上是基于概率的文本生成器,它优化的是下一个Token的条件概率分布,而非事实准确性。当缺乏明确的约束和引导时,模型容易在"自由发挥"中偏离预期。
LangChain 提供的 FewShotPromptTemplate(少样本提示词模板)正是为解决这一痛点而设计的工具。它基于少样本学习(Few-Shot Learning)的原理,通过在提示词中嵌入少量示例来引导大模型理解任务意图,从而确保输出符合预期。
少样本学习源自元学习(Meta-Learning)领域,其核心思想是让模型通过极少量的标注样本快速适应新任务。在传统机器学习中,模型通常需要成千上万的训练样本才能达到良好效果,而少样本学习试图模拟人类"举一反三"的认知能力。GPT系列论文中首次系统性地将In-Context Learning(上下文学习)与Few-Shot结合,证明大语言模型可以仅通过提示词中的示例就完成任务适配,无需梯度更新或微调。这种能力被认为是大模型涌现能力(Emergent Abilities)的重要表现之一。
少样本提示通过提供具体的输入-输出映射示例,相当于在推理时为模型建立了一个"局部约束空间",使其输出模式被锚定在示例所定义的范式内,从而大幅降低模型"自由发挥"导致幻觉的概率。研究表明,少样本方式在格式化输出、分类任务和规则遵循方面的幻觉率可降低40%-70%。
这种方法特别适用于翻译、文本分类、逻辑推理等复杂任务场景。相比零样本(Zero-Shot)直接提问,少样本方式能显著提升模型输出的准确性和一致性。
FewShotPromptTemplate 核心参数详解
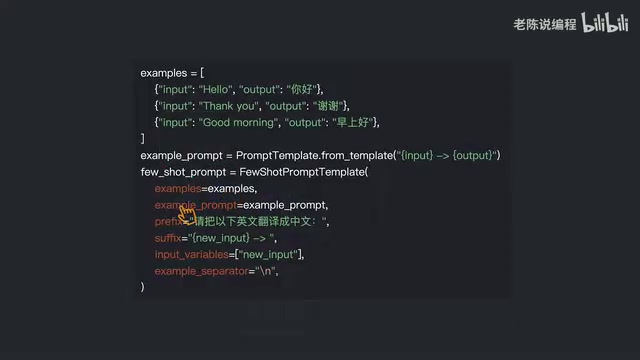
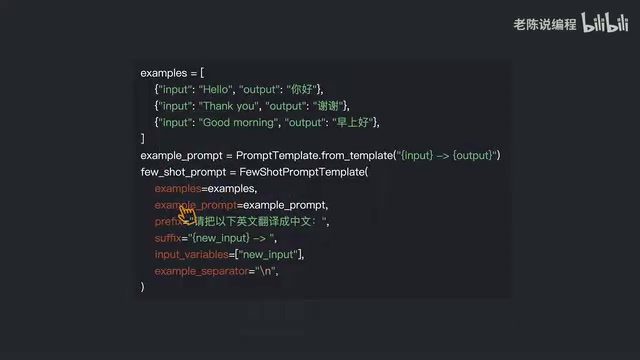
创建 FewShotPromptTemplate 时,需要理解以下关键参数:
必填参数(二选一)
- Examples:直接传入示例数据列表
- ExampleSelector:通过选择器动态选取示例
需要特别注意的是,这两个参数互斥且必填其一,同时传入或都不传入都会导致报错。通常在简单场景下使用 Examples 参数直接传入示例数据。
ExampleSelector 是 LangChain 提供的示例动态选择器,当示例库规模较大时(如数十甚至数百个示例),将所有示例都放入提示词会导致 Token 消耗过大甚至超出上下文窗口限制。ExampleSelector 通过语义相似度(基于向量嵌入)、最大边际相关性(MMR)或长度限制等策略,从示例库中选取与当前输入最相关的少量示例。常用的实现包括 SemanticSimilarityExampleSelector(基于向量数据库检索最相似示例)和 LengthBasedExampleSelector(根据 Token 预算动态调整示例数量)。这种机制本质上是将 RAG(检索增强生成)的思想应用到了示例选择环节。
其他重要参数
- ExamplePrompt:示例的格式化模板,定义每个示例如何呈现
- Prefix:放在所有示例之前的引导文本,用于说明任务背景
- Suffix:放在所有示例之后的用户输入提示,通常包含占位变量
- Input Variables:用户输入变量列表,对应 Suffix 中的占位符
- ExampleSeparator:示例之间的分隔符,默认为换行
文本补全模型的少样本实战
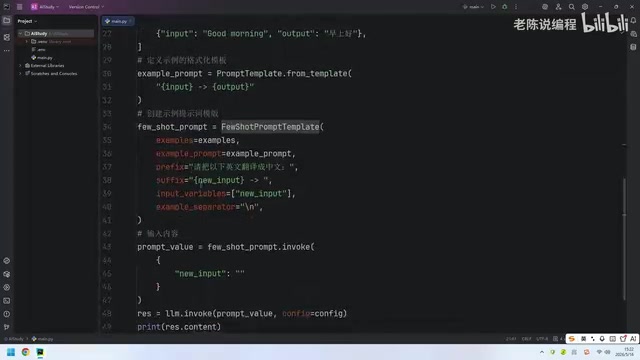
对于文本补全模型(如 text-davinci-003 等),直接使用 FewShotPromptTemplate 即可。文本补全模型采用单向文本生成范式,接收一段连续文本作为输入,续写后续内容。其 API 接口接受一个字符串类型的 prompt 参数,因此 FewShotPromptTemplate 最终会将所有内容(Prefix、示例、Suffix)拼接为一个完整的字符串。
基本流程如下:
- 定义示例数据(如英译中的翻译对)
- 创建 ExamplePrompt 格式化模板
- 组装 FewShotPromptTemplate,填入 Prefix、Suffix 等参数
- 传入用户输入,生成最终提示词
开发建议:在开发测试阶段,务必将生成的完整提示词打印出来检查,确认格式和内容是否符合预期。这是调试提示词工程的重要手段。
聊天模型的少样本实现:FewShotChatMessagePromptTemplate
对于聊天模型(如 GPT-3.5/4),需要使用 FewShotChatMessagePromptTemplate,这是专门为对话格式设计的少样本模板。
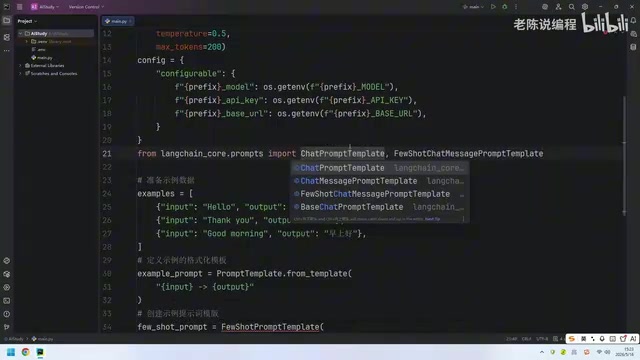
与文本补全模型的关键区别
聊天模型(Chat Model)如 GPT-3.5-turbo 和 GPT-4 采用对话轮次结构,输入是由 system、user、assistant 三种角色消息组成的消息列表(messages array)。这种结构化的输入格式使得模型能更好地理解对话上下文和角色定位。因此在 LangChain 中,两种模型对应不同的提示词模板类,以适配各自的输入格式要求。
与文本补全模型不同,聊天模型的示例格式化模板需要改用 ChatPromptTemplate.from_messages() 方法,内部通过字典定义角色(role)和内容(content)。这符合聊天模型的消息格式规范。每个示例会被转换为一组 user-assistant 消息对,模拟真实的对话交互历史,让模型从"对话记忆"中学习任务模式。
实现步骤
- 使用
ChatPromptTemplate.from_messages()创建示例模板 - 用
FewShotChatMessagePromptTemplate包装示例模板和示例数据 - 将少样本模板与系统提示、用户输入合并为完整的 ChatPromptTemplate
- 调用
invoke()方法传入变量,生成最终消息列表
经过测试,聊天模型同样能够准确完成翻译任务,验证了少样本模板在对话场景中的有效性。
实用场景:少样本提示词实现批量文件重命名
教程最后展示了一个极具实用价值的应用——将少样本功能集成到 PySide6 开发的 AI 应用界面中,实现批量文件重命名功能。
PySide6 是 Qt for Python 的官方绑定库,由 Qt 公司维护,采用 LGPL 许可证,允许商业使用。它提供了丰富的 GUI 组件用于构建跨平台桌面应用。将 LangChain 的少样本功能集成到 PySide6 应用中,代表了一种"AI 能力本地化"的开发范式——将大模型的智能推理能力封装为桌面工具,使非技术用户也能通过图形界面享受 AI 辅助。
通过少样本示例,可以教会大模型按照特定规则生成文件名。例如提供几组"原始文件名 → 规范文件名"的示例,模型就能理解命名规则并批量处理。用户只需在界面上提供几组命名示例,后端通过 FewShotPromptTemplate 构建提示词调用大模型,即可自动推断命名规则并批量应用。这种方式的优势在于:
- 一次开发,一劳永逸:规则变更时只需修改示例,无需改代码
- 灵活性强:不同的命名规则只需更换示例集
- 降低维护成本:非技术人员也能通过修改示例调整行为
总结与最佳实践
使用 LangChain 少样本提示词模板时,建议遵循以下原则:
- 示例质量优先:2-5个高质量、有代表性的示例胜过大量低质量示例。研究表明,示例的多样性和边界覆盖度比数量更重要
- 格式一致性:确保所有示例遵循相同的输入输出格式,格式不一致会导致模型困惑,输出质量下降
- 调试先行:开发阶段始终打印完整提示词进行检查,确认 Token 消耗是否在预算内,格式是否正确
- 模型匹配:文本补全模型用 FewShotPromptTemplate,聊天模型用 FewShotChatMessagePromptTemplate。混用会导致格式错误
- 动态选择:当示例库较大时,考虑使用 ExampleSelector 根据输入动态选取最相关的示例,既节省 Token 又提升相关性
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。