LangChain提示词模板详解:Few-Shot与思维链实战指南
以RAG为切入点,系统讲解LangChain中的提示词模板与核心提示技术。
文章阐述了提示词工程推动NLP从「预训练-微调」范式转向「预训练-提示-预测」新范式的重要意义,并以RAG为核心场景,详细解析了RAG提示词的四层结构(规则、上下文、问题、答案),介绍了LangChain ChatPromptTemplate的用法、Few-Shot提示和Chain-of-Thought思维链等关键技术及其应用场景。
提示词为何如此重要
提示词(Prompt)看似简单,却是推动AI从预训练时代迈向大模型时代的核心驱动力。要理解这一转变的深度,需要回顾NLP领域的范式演进。在大语言模型出现之前,NLP领域主要依赖「预训练-微调」范式(Pre-train Fine-tune Paradigm)。开发者需要在特定任务数据集上对BERT、GPT-2等模型进行监督微调,这不仅需要大量标注数据,还需要专业的ML工程能力和昂贵的计算资源——收集数据、标注、训练、评估,整个周期动辄数月。
提示词工程(Prompt Engineering)的兴起标志着「预训练-提示-预测」新范式的到来。模型本身的能力通过自然语言指令被直接激活,无需修改任何模型权重。在LLM普及之前,要让AI模型适应特定任务,需要收集大量数据、花费数天甚至数月进行微调。而现在,只需要通过不同的提示词就能引导模型完成各种任务——这是一个真正的范式转变,从数月的工作量缩短到几分钟。
LangChain围绕提示词构建了丰富的功能体系,允许开发者构建动态的提示管道,根据不同变量和输入来修改传入LLM的结构和内容。本文将以RAG(检索增强生成)为切入点,系统讲解LangChain中的提示词模板与核心提示技术。
RAG提示词的四层结构解析
在深入提示词结构之前,有必要理解RAG技术本身的来龙去脉。检索增强生成(Retrieval-Augmented Generation,RAG)由Meta AI在2020年的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中正式提出。其核心动机是解决LLM的两大固有缺陷:知识截止日期(Training Cutoff)导致模型无法获取最新信息,以及幻觉问题(Hallucination)导致模型在知识边界外自信地输出错误内容。RAG通过在推理阶段动态检索外部知识库,将模型权重中存储的「参数化知识」与实时获取的「非参数化知识」相结合,使模型能够访问实时、私有或专业领域的信息,而无需重新训练整个模型。
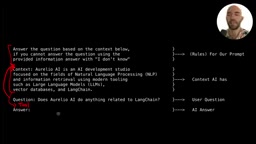
一个典型的RAG提示词包含四个核心部分:
规则与指令(System Prompt)
这是几乎所有提示词都会包含的部分,用于设定LLM的行为模式:如何响应用户查询、采用什么样的人格、关注什么内容、有哪些边界约束。核心原则是提供尽可能多的上下文信息,但保持简洁——LLM本身对自己所处的应用场景一无所知,我们需要明确告诉它一切,同时避免冗余和「过度提示」。
上下文(Context)
这是RAG特有的部分,指从外部来源(Web搜索、数据库查询、向量数据库)获取的信息。这些外部知识用于增强LLM自身模型权重中包含的知识——这正是「检索增强」的含义。对于聊天模型,上下文通常放在用户/助手消息中,较新的模型也支持放在工具消息中。
问题(Query)
用户的输入查询,通常作为用户消息传入。如果发现LLM有时偏离系统提示中设定的规则,可以在此处附加额外的指令进行约束。
答案(Output)
由助手生成的响应内容。
LangChain ChatPromptTemplate基础用法
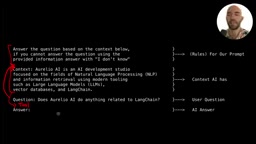
在LangChain中,我们使用ChatPromptTemplate来构建提示模板。以下是一个标准的RAG提示模板示例:
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's query based on the context below. "
"If you cannot answer using the provided information, "
"answer with 'I don't know'.\n\nContext: {context}"),
("user", "{query}")
])
LangChain会自动识别模板中的输入变量(如context和query)。你也可以使用SystemMessagePromptTemplate和HumanMessagePromptTemplate对象来更显式地定义,两种方式效果相同,选择取决于你对代码可读性的偏好。
RAG场景下的温度参数选择
在RAG场景中,建议使用低温度(temperature=0)。理解这一建议需要了解温度参数的数学本质:Temperature控制LLM输出的随机性,其实现方式是对Softmax函数中的logits进行缩放。当temperature趋近于0时,模型几乎总是选择概率最高的token(即贪婪解码),输出高度确定;当temperature趋近于无穷大时,所有token的概率趋于均等,输出接近完全随机。典型取值范围为0到2,RAG场景推荐00.3,因为RAG要求LLM输出准确、真实的信息,而高温度在增加创造性的同时也会放大幻觉风险。如果是创意写作场景,则可以将温度提高至0.71.2。低温度使输出更具确定性,理论上能有效减少幻觉。
Few-Shot提示:用示例引导模型行为
Few-Shot提示的核心思想是在正式对话前,向LLM提供几个输入-输出示例,展示期望的行为模式。这一技术源于元学习(Meta-Learning)领域的「上下文学习」(In-Context Learning,ICL)能力,在GPT-3的论文中被首次系统性描述。其理论假设是:足够大的语言模型在预训练阶段已经隐式学习了「从示例中归纳规律」的元能力,Few-Shot示例本质上是在激活模型的这种潜在能力,而非触发真正的梯度更新学习——这也解释了为什么示例数量不需要很多(通常3~8个即可),以及为什么示例质量比数量更重要。
什么时候需要Few-Shot提示
对于GPT-4o等顶级模型,Few-Shot提示的必要性已经降低,因为它们的指令遵循能力足够强。但对于较小的开源模型(如Llama 2/3),Few-Shot提示仍然是让模型遵循特定输出格式的有效手段。
FewShotChatMessagePromptTemplate实战
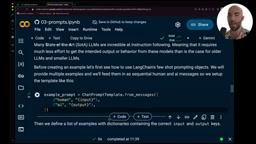
假设你希望LLM始终按照特定的Markdown格式输出(主标题→摘要→子标题→要点→结论),可以通过FewShotChatMessagePromptTemplate提供格式示例:
from langchain.prompts import FewShotChatMessagePromptTemplate
examples = [
{"input": "query1", "output": "formatted_answer1"},
{"input": "query2", "output": "formatted_answer2"}
]
example_prompt = ChatPromptTemplate.from_messages([
("human", "{input}"),
("ai", "{output}")
])
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples
)
一个值得尝试的进阶技巧是动态选择示例:根据用户话题(通过关键词匹配或语义相似度判断),动态切换不同的示例集,让Few-Shot示例与当前对话内容更加匹配。
Chain-of-Thought思维链:让模型逐步推理
Chain-of-Thought(思维链)提示鼓励LLM逐步展示推理过程,类似于数学课上老师要求学生写出完整的解题步骤。这一技术由Google Brain团队在2022年的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中正式提出,研究发现只需在Few-Shot示例中加入中间推理步骤,模型在算术、常识推理和符号推理任务上的表现就能大幅提升。后续研究还衍生出了Zero-Shot CoT(仅需在提示末尾添加「Let's think step by step」即可激活推理链,无需任何示例)和Self-Consistency(多路径采样后取多数答案,进一步提升准确率)等重要变体。

思维链为什么有效
通过「写下推理过程」,LLM能够获得三个方面的提升:
- 减少幻觉:逐步推理比直接跳到答案更准确
- 便于调试:工程师可以看到模型在哪一步出了问题
- 提升复杂任务表现:将大问题分解为可管理的子问题
实验对比:计算按键次数
这里有一个直观的实验——计算输入数字1到500需要多少次按键:
- 无Chain-of-Thought(强制直接回答):输出1511,错误
- 有Chain-of-Thought(要求逐步分解):将问题拆分为1-9位数、10-99位数、100-499位数、500的按键数,最终得出1392,正确答案
- 不做任何限制:现代LLM默认就会使用Chain-of-Thought,同样得出正确答案
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。