LinCTX:帮AI编程助手省掉99%Token的开源神器

LinCTX通过智能压缩和缓存复用,大幅减少AI编程助手的Token浪费。
AI编程助手每次对话都需重复读取文件,造成大量Token浪费。开源工具LinCTX作为中间层,通过基于代码语义的智能摘要压缩和缓存复用机制,将重复文件读取降至仅13个Token,支持10种文件读取模式和95种命令压缩,兼容Cursor、Claude Code等24种主流AI工具,本地运行保障安全,可减少60%-99%的Token消耗。
AI编程助手的隐性成本:Token浪费有多严重
用Cursor、Claude Code等AI编程工具写代码时,很少有人留意一个隐性成本——每次AI读取文件、执行命令,都在消耗大量Token。一个中型项目一天下来,仅仅是重复读取相同文件,就可能多花几十美元。
这里有必要解释一下Token的概念和成本量级。Token是大语言模型处理文本的基本单位,并非简单的"一个字"或"一个词"。对于英文,一个Token大约对应4个字符或0.75个单词;对于中文,一个汉字通常被拆分为1-2个Token。主流AI API(如OpenAI GPT-4o、Anthropic Claude)按Token数量计费,输入和输出分别定价。以Claude 3.5 Sonnet为例,输入价格约为每百万Token 3美元,输出约为15美元。一个中型项目的代码库可能包含数万行代码,每次完整传输给AI就意味着数万甚至数十万Token的消耗,这使得Token成本成为AI编程工具使用中一个容易被忽视但实际影响巨大的隐性开支。
问题的根源在于:AI编程助手每次都在"原样"读取文件内容。一个几千行的配置文件,不管AI是否已经看过,每次都会完整传输。这种粗暴的方式造成了巨大的Token浪费。之所以如此,与大语言模型的上下文窗口(Context Window)机制密切相关。上下文窗口是模型单次对话能"看到"的最大Token数量,目前主流模型的窗口大小从128K到200K Token不等。但关键问题在于:每轮新的对话或请求,模型并不会自动"记住"之前读过的文件内容——它需要将所有相关上下文重新放入窗口中。这意味着当开发者在一个会话中多次修改和调试代码时,AI助手可能需要反复将同一批文件完整地重新加载到上下文中,每次加载都会产生新的Token消耗。这种架构性的重复传输,正是LinCTX试图解决的核心痛点。
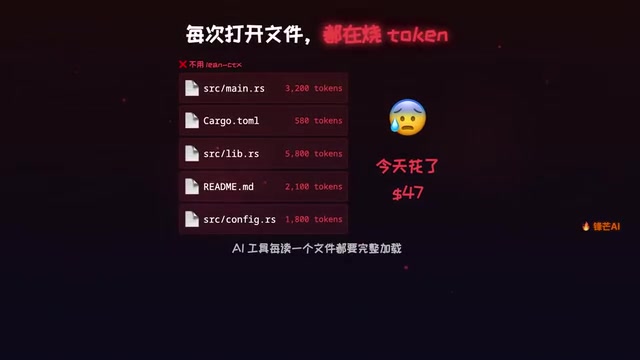
而今天要介绍的开源工具LinCTX,正是为解决这个问题而生。它在GitHub上被称为"AI开发的上下文操作系统",目前已获得1600+星标,由Rust编写,能帮你省掉60%到99%的Token消耗。
LinCTX的核心原理:智能压缩+缓存复用
LinCTX的设计思路非常巧妙——它作为一个中间层,安装在你和AI编程工具之间,自动对每一次文件读取和命令输出进行智能压缩。

智能摘要压缩:首次读取即大幅缩减
当AI第一次读取一个文件时,LinCTX不会原样传输全部内容,而是将其压缩成结构化的摘要。原来需要几千Token的文件,压缩后可能只需要几百Token,同时保留了AI理解代码所需的关键信息。
这种智能摘要压缩并非简单的文本截断或zip式压缩,而是基于代码语义的结构化提取。对于源代码文件,它会解析代码的抽象语法树(AST),提取函数签名、类定义、接口声明、导入关系等骨架信息,同时省略函数体内部的具体实现细节。这种方式类似于为AI提供一份代码的"目录"而非"全文"——AI可以据此理解文件的整体结构和API接口,当需要深入某个具体函数时再按需获取。这一思路与软件工程中的"关注点分离"原则一脉相承:大多数时候AI并不需要逐行阅读每个文件的完整实现,它只需要知道"有哪些模块、暴露了哪些接口、类型定义是什么"就足以完成大部分编程辅助任务。
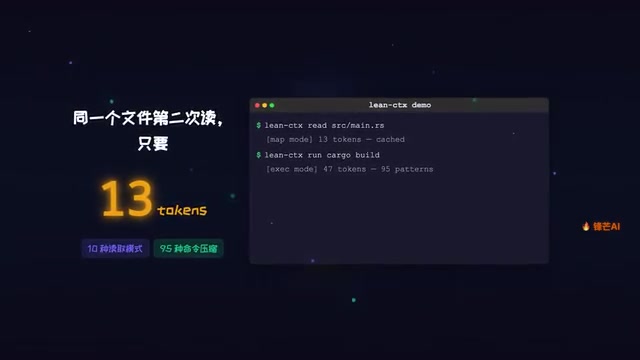
缓存机制:第二次读取只要13个Token
这是LinCTX最核心的能力。同一个文件第二次被读取时,由于已经有了缓存,只需要传输13个Token就够了。一个原本需要几千Token的文件,第二次读取时直接降到13个Token,压缩比堪称恐怖。
在实际开发中,AI助手反复读取同一批文件是极其常见的场景——比如反复查看配置文件、工具函数、类型定义等。缓存机制在这些高频场景下能带来巨大的成本节省。
覆盖范围:10种读取模式 + 95种命令压缩
LinCTX不仅处理文件读取,还覆盖了开发中常用的命令输出压缩。
具体来说:
- 10种文件读取模式:针对不同类型的文件(源代码、配置文件、文档等)采用不同的压缩策略
- 95种命令压缩模式:覆盖了
git、npm、cargo等几乎所有日常开发命令的输出压缩
开发过程中,命令行工具的输出往往包含大量冗余信息。以npm install为例,一次安装可能输出数百行依赖解析日志、版本协商信息和进度条字符,但AI真正需要关注的可能只是"是否安装成功"和"有哪些警告或错误"。类似地,git log可能返回数千行提交历史,cargo build会输出详细的编译过程。LinCTX的95种命令压缩模式针对每种命令的输出格式进行定制化处理,提取关键信息(如错误码、警告信息、最终状态)并丢弃噪音数据。这种针对性压缩比通用文本压缩更高效,因为它理解每种命令输出的语义结构。
无论你是前端开发者频繁使用npm,还是Rust开发者依赖cargo,LinCTX都能对命令输出进行智能压缩,减少不必要的Token消耗。
兼容性与安全性
兼容24种主流AI编程工具
LinCTX的兼容性相当出色,支持目前主流的AI编程工具:
- Cursor — 最热门的AI代码编辑器
- Claude Code — Anthropic的命令行编程工具
- GitHub Copilot — 微软/GitHub的AI编程助手
- Windsurf — Codeium推出的AI IDE
总共兼容24种AI工具,基本做到了全面覆盖。
本地运行,代码不外泄
安全性方面,LinCTX采用本地运行的方式,一个命令即可安装。所有的压缩和缓存操作都在本地完成,代码永远不会离开你的电脑。对于处理敏感项目或企业代码的开发者来说,这是一个重要的安心保障。
项目活跃度与社区状况

LinCTX上线后在短时间内就取得了亮眼的数据:
- 1600+ GitHub星标
- 20位 代码贡献者
- 172个 版本更新
这个更新频率非常惊人——172个版本意味着几乎每天都有多次更新迭代,说明项目团队对产品打磨非常积极。
LinCTX选择Rust作为开发语言并非偶然。Rust是由Mozilla研究院发起的系统级编程语言,以"零成本抽象"和内存安全著称。它通过独特的所有权(Ownership)和借用检查(Borrow Checker)机制,在编译期就消除了空指针、数据竞争等常见bug,无需垃圾回收器即可保证内存安全。对于LinCTX这样需要作为中间层拦截和处理大量文件I/O操作的工具,Rust的高性能和低延迟特性至关重要——它确保了压缩和缓存操作本身不会成为开发流程的瓶颈。近年来,Rust在开发者工具领域的采用率快速增长,Turbopack、SWC、Ruff等知名项目都选择了Rust来替代传统的JavaScript或Python实现,以获得数量级的性能提升。
LinCTX值得安装吗?
如果你每天都在使用AI编程助手,LinCTX几乎是一个"装了不亏"的工具。它的价值主张很清晰:
- 省钱 — 减少60%-99%的Token消耗,对于重度AI编程用户来说,每月可能节省数百美元
- 无感接入 — 作为中间层运行,不需要改变现有的开发习惯
- 安全可控 — 本地运行,开源透明,代码不外泄
当然,"省99%Token"这个数字需要理性看待,它更多代表的是缓存命中时的极端场景。实际节省比例取决于你的项目规模、文件重复读取频率等因素。但即便是保守估计的60%节省,对于日常开发来说也已经非常可观。
在AI编程工具的使用成本日益受到关注的今天,LinCTX提供了一个优雅的解决思路:不是让AI少做事,而是让AI更聪明地获取信息。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。