Llama 3.3 70B深度测评:13道题实测最强开源大模型
Meta发布Llama 3.3 70B,以700亿参数达到4050亿参数模型性能,成为最强开源大模型。
Meta低调发布Llama 3.3 70B模型,仅用700亿参数便匹敌此前4050亿参数的Llama 3.1 405B性能。通过监督微调和RLHF优化训练,该模型在13道涵盖逻辑推理、数学和编程的测试中通过12道,表现优于Qwen 2.5系列。模型完全开源免费,支持本地部署和函数调用,大幅降低了高质量AI的使用门槛,标志着开源与闭源模型差距快速缩小。
文章正文
在所有人都在关注OpenAI连续发布会的时候,Meta悄然发布了Llama 3.3 70B模型。这款仅有700亿参数的模型,却号称能匹敌此前4050亿参数的Llama 3.1 405B的性能。经过13道涵盖逻辑推理、数学计算、编程能力的全面测试,结果令人惊喜——它可能是目前最强的开源大语言模型。
OpenAI发布会令人失望,Meta趁势出击
在Llama 3.3发布的同一时间段,OpenAI正在进行其备受期待的连续发布活动。然而,评测者对OpenAI的表现颇为失望:第一天发布的O1完整版模型表现平平,而更让人难以接受的是O1 Pro模式——每月高达200美元的订阅费用,却只提供了一个"相当平庸的推理模型"。评测者直言:"既然DeepSeek R1和QWQ都是免费的,谁会为此买单?"更糟糕的是,新的O1完整版甚至还没有开放API访问。
相比之下,Meta的Llama 3.3 70B不仅完全开源,还可以在Hugging Face、Ollama等多个平台免费使用,甚至可以在本地部署运行。这种鲜明的对比,让开源社区再次看到了希望。
开源部署生态背景:Hugging Face是目前全球最大的AI模型托管平台,提供模型权重下载、在线推理API以及数据集共享等服务,被称为AI领域的"GitHub"。Ollama则是一个专为本地部署设计的开源工具,通过将模型量化压缩(如将32位浮点数压缩为4位整数),使普通消费级GPU甚至CPU也能运行数十亿参数的大模型。以Llama 3.3 70B为例,经过4-bit量化后,模型大小约为40GB,可在配备64GB内存的Mac Studio或单张48GB显存的专业GPU上流畅运行。这种本地部署能力对数据隐私敏感的企业和个人用户具有极高价值。
Llama 3.3 70B技术解析:以小博大的秘密
Llama 3.3 70B本质上是对此前Llama 3.1 70B的微调版本,采用了优化的Transformer架构,并通过监督微调(SFT)和基于人类反馈的强化学习(RLHF)进行训练——这与此前Athene Phi 2的训练方法类似。
Transformer架构与参数规模:Transformer架构自2017年Google提出以来,已成为几乎所有现代大语言模型的基础。其核心是自注意力机制(Self-Attention),允许模型在处理每个词时同时关注输入序列中的所有其他词。参数规模(如70B代表700亿个可训练参数)通常与模型能力正相关,但并非线性关系。近年来研究表明,通过更高质量的训练数据、更优化的训练策略和更精细的后训练对齐,较小参数量的模型完全可以在实际任务中超越参数量更大但训练质量较低的模型——Llama 3.3 70B正是这一趋势的典型体现。
SFT与RLHF技术原理:监督微调(Supervised Fine-Tuning, SFT)是指在预训练大模型基础上,使用高质量标注数据集进行二次训练,使模型行为更符合特定任务需求。而基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)则更进一步:通过收集人类对模型输出的偏好评分,训练一个"奖励模型",再用强化学习算法(如PPO)优化主模型,使其输出更符合人类期望。这一技术组合最早由OpenAI在InstructGPT论文中系统阐述,是ChatGPT能够进行自然对话的核心技术基础。后训练(Post-training)阶段的质量,往往比预训练参数规模更能决定模型的实际可用性。
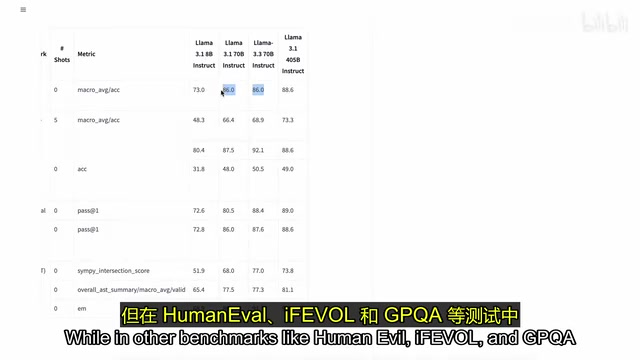
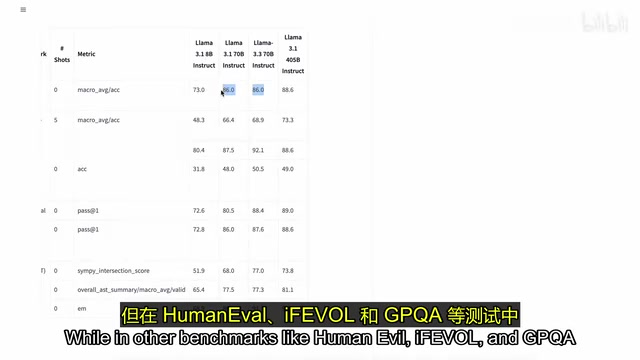
从基准测试来看,Llama 3.3在MMLU上的提升并不算特别显著,但在Human Eval、iFEVOL和GPQA等基准测试中展现出了重大改进。
主流基准测试解读:大语言模型评测领域存在多个标准化基准测试,各有侧重:MMLU(Massive Multitask Language Understanding)涵盖57个学科的选择题,测试模型的广泛知识储备;HumanEval是OpenAI设计的代码生成基准,包含164道编程题,以代码能否通过单元测试为评判标准;GPQA(Graduate-Level Google-Proof Q&A)则专注于博士级别的科学推理题,即便是领域专家也难以通过网络搜索直接找到答案,是衡量深度推理能力的高难度基准。iFEVOL(Instruction Following Evaluation)则专门测试模型遵循复杂指令的能力。这些基准的组合使用,能够从多个维度较为全面地评估模型能力。
此外,该模型还支持函数调用(Function Calling),这对于构建AI Agent和工具链集成至关重要。
函数调用与AI Agent:函数调用(Function Calling)是指大语言模型能够识别用户意图,并以结构化格式(通常为JSON)输出调用外部工具或API所需的参数,而非仅生成自然语言文本。这一能力最早由OpenAI在GPT-3.5/4中系统化引入,是构建AI Agent的关键基础设施。AI Agent是指能够自主规划、调用工具、执行多步骤任务的AI系统——例如自动搜索网页、执行代码、查询数据库等。支持函数调用意味着Llama 3.3 70B可以无缝集成到LangChain、LlamaIndex等主流Agent框架中,大幅拓展其在生产环境中的应用场景。
你可能没注意到,Meta并没有为这次发布撰写专门的博客文章,仅在Twitter上链接了Hugging Face页面。这种低调的发布方式与模型本身的强大性能形成了有趣的反差。模型目前已在Together AI、Hyperbolic和GLHF等平台上线,用户可以免费试用。
13道题全面实测:逻辑、数学、编程逐项验证
评测者设计了13道覆盖多个维度的测试题目,对Llama 3.3 70B进行了系统性评估。以下是各类测试的详细表现:
逻辑推理与语言理解能力测试
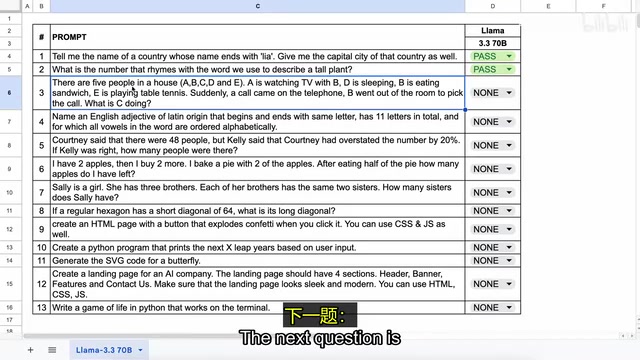
第一题:国家名称推理 — 要求说出一个以"LIA"结尾的国家名及其首都。模型正确回答,通过。
第二题:语音韵律推理 — "什么数字与描述高大植物的词押韵?"答案应为3(three与tree押韵)。模型正确回答,通过。
第三题:场景逻辑推理 — 给出A到E五个人的活动描述,问C在做什么。模型推断C在与E打乒乓球,这是一个合理的推断,通过。
第四题:复杂词汇约束 — 要求找出一个满足多重条件的11字母拉丁语源英文形容词。这道题模型未能正确回答,是唯一的失败项。
数学计算能力测试
第五题:百分比计算 — Courtney说有48人,Kelly说Courtney多报了20%,实际有多少人?模型正确计算出40人。
第六题:应用题推理 — 涉及苹果购买、烘焙和食用的多步骤问题,模型正确回答剩余2个苹果。
第七题:姐妹关系推理 — Kelly有三个兄弟,每个兄弟有相同的两个姐妹,Sally有几个姐妹?模型正确回答1个。
第八题:几何计算 — 正六边形短对角线为64,求长对角线。模型正确给出73.9的答案。
编程与代码生成能力测试
编程测试是Llama 3.3表现最为亮眼的领域,5道编程题全部通过:
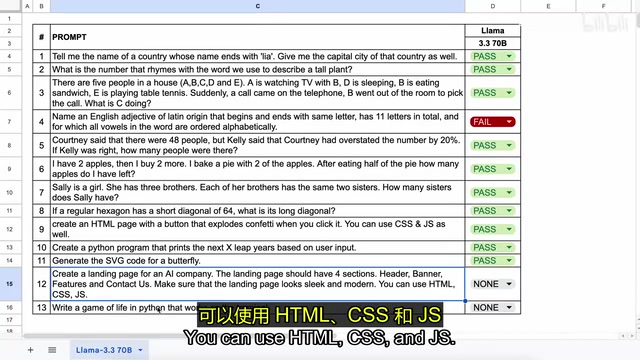
- HTML彩纸爆炸效果:创建带有点击按钮触发彩纸动画的网页,效果运行良好
- Python闰年检测:根据用户输入判断闰年,程序运行正确
- SVG蝴蝶生成:生成的SVG代码确实呈现出蝴蝶的形态
- AI公司落地页:包含Header、Banner、Features和Contact Us四个板块的现代化页面,视觉效果出色
- 终端版生命游戏:Python实现的Conway生命游戏,在终端中正常运行
Conway生命游戏背景:Conway生命游戏(Conway's Game of Life)是英国数学家约翰·霍顿·康威于1970年设计的元胞自动机,是计算机科学中的经典算法题。其规则极为简单:在二维网格中,每个细胞根据周围8个邻居的存活状态决定下一代是否存活——活细胞邻居过少或过多会死亡,死细胞恰好有3个活邻居会复活。尽管规则简单,生命游戏却能产生极其复杂的涌现行为,甚至被证明是图灵完备的。在AI编程能力测试中,生命游戏是一道经典题目,因为它需要模型正确理解二维数组操作、边界条件处理和终端渲染逻辑,能较好地检验代码生成的综合质量。
最终成绩:13题中通过12题,仅在复杂词汇约束题上失败。
横向对比:Llama 3.3 vs Qwen 2.5 vs GPT-4O
评测者明确表示,Llama 3.3 70B"远优于"此前的Llama 3.1 70B,甚至在个人使用体验上超过了Qwen 2.5系列。他认为后训练(Post-training)过程是关键因素——此前Athene团队对Qwen模型进行类似的后训练也取得了更好的结果,而这次是Meta官方亲自操刀,效果自然更加出色。
评测者还大胆预测:如果Meta对405B版本进行同样的微调优化,其性能有望超越GPT-4O,并接近Claude的水平。这意味着开源模型与闭源模型之间的差距正在以前所未有的速度缩小。
Llama 3.3对开源AI生态的深远影响
从更宏观的视角来看,Llama 3.3 70B的发布具有多重意义:
推理成本大幅降低:70B参数量意味着远低于405B的推理成本和硬件需求,却能提供相近的性能。这让更多开发者和中小企业能够部署高质量的AI模型。在云端推理场景中,70B模型的单次推理成本通常仅为405B模型的五分之一左右,这对于高并发的生产环境意义重大。
本地部署门槛降低:通过Ollama等工具,用户可以在消费级硬件上运行这一模型,数据隐私和离线使用不再是奢望。量化技术(Quantization)的成熟使得在普通PC上运行70B级别模型成为可能,进一步打破了AI能力的硬件壁垒。
开源vs闭源格局改写:当一个免费开源的70B模型能够在多数任务上媲美甚至超越收费数百美元的闭源服务时,商业模式的可持续性值得重新审视。开源模型的快速迭代节奏——得益于全球开发者社区的共同贡献——正在形成闭源商业模型难以匹敌的创新速度优势。
Llama 3.3 70B的出现,标志着开源大语言模型进入了一个新的阶段。正如评测者所言:"Qwen的领先地位已经动摇,Llama真正回到了竞争的核心。"对于整个AI社区而言,这无疑是一个值得庆祝的时刻——真正的竞争,才能推动真正的进步。
核心要点
- Llama 3.3 70B仅用700亿参数就达到了此前4050亿参数Llama 3.1 405B的性能水平,实现了以小博大的技术突破
- 在13道涵盖逻辑推理、数学计算和编程能力的全面测试中,Llama 3.3通过了12道题,表现优于Llama 3.1 70B和Qwen 2.5
- 模型采用监督微调(SFT)和RLHF训练,支持函数调用,已在Hugging Face、Ollama、Together AI等多个平台免费开放使用
- 评测者认为OpenAI的O1 Pro模式(月费200美元)性价比远不如免费的开源替代方案,开源与闭源模型的差距正在快速缩小
- Llama 3.3 70B的发布重塑了开源模型竞争格局,评测者预测若Meta对405B版本进行同样优化,有望超越GPT-4O
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。