Loop Engineering实践指南:循环工程的痛点与解决方案
什么是Loop Engineering?
最近,AI编码圈子里一个新概念正在快速升温——Loop Engineering(循环工程)。OpenCloud作者Peter Steinberger和Claude Code负责人Boris Cherney都在积极推广这一理念。Boris甚至直言:"我已经不再给Claude写Prompt了,我写Loops,然后让Loops去干活。"
简单来说,Loop Engineering的核心思路是:不再手写每一条Prompt,而是设计一套循环系统,让AI编码助手自主地、持续地完成任务。 开发者的角色从"写指令的人"变成了"设计循环的人"。
这一理念的兴起与AI编码助手从单轮对话向多轮自主执行的演进密切相关。早期的AI编码工具(如GitHub Copilot)主要做代码补全,开发者仍需逐行引导。随着Claude Code、Cursor、Windsurf等Agentic编码工具的出现,AI开始具备理解项目上下文、执行多步操作的能力。Loop Engineering正是在这一背景下诞生的——它试图将AI编码助手从"被动响应者"升级为"主动执行者",通过循环机制实现任务的持续自主推进。
在Claude Code中,这套体系建立在几个关键功能之上:
- slash loop:给Prompt设置运行间隔,比如每5分钟检查一次GitHub仓库有没有新Issue,有就自动处理
- slash go:设定完成标准,让Coding Agent一直干到达标为止
- slash routines:定时任务,比如每小时醒来一次,读取Spec文档,处理下一个任务
Loop Engineering本质上就是把这些能力组合成系统,让AI编码助手能够接管更大范围的工作,并一步步自主推进。
循环工程的核心架构:Orchestrator + Workers
Loop Engineering的核心架构是一个主控Orchestrator Agent。开发者只需从高层说明目标,Orchestrator会自己搭建循环系统,拆解任务,逐轮执行。
Orchestrator-Workers模式是分布式系统中的经典架构模式,在AI Agent领域被广泛采用。Orchestrator(编排器)负责任务分解、调度和状态管理,Workers(工作者)负责具体执行。这种模式在Anthropic发布的《Building Effective Agents》指南中被列为推荐的多Agent协作模式之一。与之类似的还有MapReduce模式和Pipeline模式,但Orchestrator模式的优势在于它能动态调整任务分配策略,更适合处理复杂度不确定的编码任务。
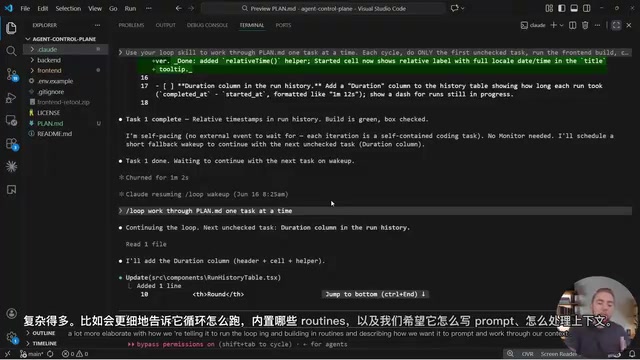
以Claude Code为例,你只需告诉它"使用Loop Skill",传入一个包含任务列表的Spec文档,它就会:
- 加载Loop Skills,理解如何调度
- 每一轮处理第一个未完成的任务
- 完成后验证,进入下一轮
- 循环往复,直到所有任务完成
有意思的是,循环中的Prompt完全由AI自己生成,而非开发者手写。比如它会自动写出类似"slash loop一次处理PlanMD里的一个任务"这样的调度指令。Boris的实际系统会内置更细的routines和上下文处理策略,但底层逻辑就是这么回事。
Loop Engineering的三大痛点
循环工程并非银弹。在实际落地过程中,有三个核心问题值得警惕:
痛点一:可靠性难以保障
Boris声称自己有时会一次管理成千上万个AI Agents。但这现实吗?实际情况是,循环工程适合做Proof of Concept或快速探索想法,但并不适合驱动所有AI编码工作。不少团队搭好系统后就放任运行,结果跑了一天回来发现产出质量堪忧。这里的核心矛盾在于:当前大语言模型的单步准确率虽然已经很高(在某些基准测试中超过90%),但在多步串联的循环场景中,错误会以指数级累积——如果每步准确率为95%,经过20步循环后整体准确率就会降至约36%。这就是为什么纯粹依赖AI自主循环在长链任务中容易失控。
痛点二:Token成本飙升
Orchestrator需要理解Spec、判断启动多少Workers、循环跑几轮,每一步都消耗大量Token。一个相对简单的应用,仅Orchestrator跑过的所有循环就消耗了超过一百万Tokens。大量的上下文传递和推理开销几乎不可避免。
要理解这个数字的含义:Token是大语言模型处理文本的基本计量单位,一个英文单词通常对应1-2个Token,中文字符通常对应1-2个Token。当前主流模型如Claude 3.5 Sonnet的上下文窗口为200K Token,GPT-4o为128K Token。在循环工程中,每一轮循环都需要将任务描述、代码上下文、历史决策等信息传入模型,这些信息会快速累积。以Claude API为例,输入Token价格约为$3/百万Token,输出约为$15/百万Token,一百万Token的消耗意味着数十美元的直接成本,这还仅仅是单个Orchestrator的开销。
痛点三:上下文窗口膨胀
很多循环配置本质上还是同一个Coding Agent Session在跑循环。运行时间一长,大模型的上下文就会越塞越满,最终直接把模型压垮。当上下文接近窗口上限时,模型的注意力机制会出现"迷失在中间"(Lost in the Middle)现象——即模型对上下文中间部分的信息关注度显著下降,导致遗漏关键信息或产生矛盾的输出。真正的解决方案需要将工作分发到不同的独立编码会话中,并让它们能互相通信。
解决方案:用Harness工作流让循环可控
针对上述问题,一套基于Archon的Harness(工作流框架)方案应运而生,核心思路是把决策权从AI手中拿回来,只在真正需要时才调用大模型的推理能力。
Archon是一个专为AI Agent编排设计的开源工作流框架,它的核心理念是将确定性流程控制与AI推理能力相结合。与LangGraph、CrewAI等Agent框架不同,Archon更强调"工程可控性"——即开发者可以精确定义每个节点的行为、模型选择和失败处理策略。这种设计哲学源自传统软件工程中的工作流引擎(如Airflow、Temporal),但针对AI Agent的特殊需求做了适配,特别是在会话隔离、模型路由和人机协作方面。
确定性工作流替代纯AI调度
与纯粹的Loop Engineering不同,Archon工作流是提前设计好的确定性流程。以修复GitHub Issue为例,工作流包含:
- 提取Issue编号和上下文
- 用LLM分类(修Bug还是新功能)
- 根据分类走不同路径
- 调查Issue → 实现 → 验证 → 创建PR
每一步都跑在独立的Coding Agent会话中,避免上下文膨胀。流程推进由工作流引擎控制,而非完全交给AI判断。这种设计的关键优势在于:确定性节点(如条件分支、循环控制、错误处理)不消耗任何Token,只有真正需要AI推理的节点才调用大模型,从而在保持灵活性的同时大幅降低成本和不确定性。
混合模型策略压缩成本
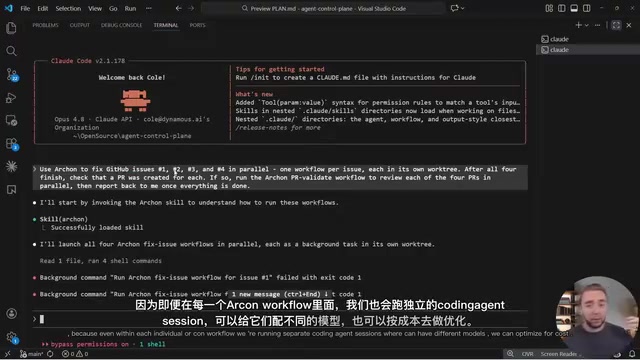
工作流的每个节点可以独立选择模型,按需分配算力:
- 分类步骤:用轻量模型(Haiku、Kimi K2.7)
- 实现阶段:用Claude Code
- 代码审查:用Codex
- 上下文探索:用更小的模型
这直接解决了"所有环节都用同一个最贵模型"导致的成本问题。混合模型策略(Model Routing)是当前AI应用成本优化的核心技术之一。不同模型在能力和价格上存在数量级的差异:Claude 3.5 Haiku的价格仅为Sonnet的约1/10,而Kimi K2.7等开源模型的API调用成本更低。关键洞察在于,并非所有任务都需要最强模型——分类、摘要等简单任务用轻量模型即可胜任,只有复杂的代码生成和架构决策才需要顶级模型。OpenRouter等模型路由服务也在推动这一趋势,允许开发者根据任务复杂度动态切换模型。
Human in the Loop保障质量
工作流的任意节点都可以加入人工确认环节——暂停、审查、再继续。这正是纯Loop Engineering最缺的:一个让人类在关键节点介入的机制。
Human in the Loop(HITL)是AI系统设计中的重要原则,指在自动化流程的关键决策点保留人类审查和干预的能力。在AI编码场景中,HITL尤为重要,因为代码错误的传播具有级联效应——一个早期的架构决策错误可能导致后续所有实现都需要推倒重来。HITL的实现方式包括同步审批(流程暂停等待人类确认)和异步审查(AI继续执行但标记需要人类复核的节点)。研究表明,在关键节点加入人类审查可以将AI编码的错误率降低60%以上,这使得HITL成为从原型探索走向生产级应用的关键桥梁。
持久化存储与可恢复性
所有日志和运行记录都存储在Neon(Postgres)数据库中。即使机器宕机或中途取消任务,也可以从中断的步骤继续执行。状态不再依赖某个Coding Agent的会话记忆。
Neon是一个基于PostgreSQL的Serverless数据库服务,支持自动扩缩容和分支管理。在AI工作流场景中,持久化存储解决的核心问题是"状态外化"——将原本存在于AI Agent会话内存中的任务状态、决策历史和中间结果转移到外部数据库中。这样即使单个Agent会话崩溃或超时,整个工作流的状态仍然完整可恢复。这一设计借鉴了微服务架构中的Saga模式和Event Sourcing模式,确保长时间运行的分布式任务具备容错能力。对于需要运行数小时甚至数天的大型编码任务,这种可恢复性是不可或缺的基础设施。
实战:可观测性Dashboard
为了解决循环工程中的可观测性问题,社区已经开源了一个专门为Loop Engineering设计的Dashboard。
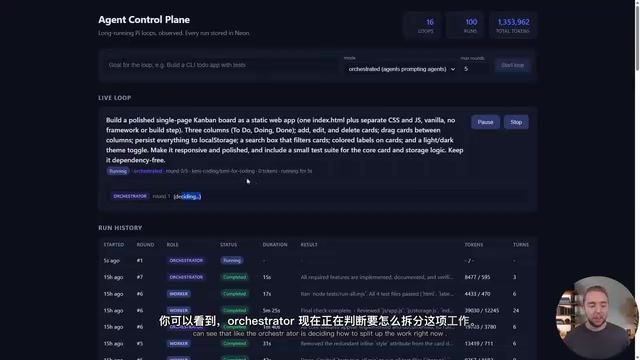
可观测性(Observability)是从DevOps领域借鉴而来的概念,最初由分布式系统追踪工具(如Jaeger、Zipkin)推广。在AI Agent场景中,可观测性面临独特挑战:不仅需要追踪传统的延迟、错误率等指标,还需要记录每一步的推理过程、Token消耗和决策依据。这对于调试AI Agent的异常行为至关重要——当一个循环产出了错误结果时,开发者需要能够回溯到具体是哪一轮、哪个决策节点出了问题。
这个Dashboard的核心能力包括:
- 全量API驱动:使用自己的API密钥(如Kimi K2.7),不依赖单一昂贵模型
- 运行历史追踪:每一轮循环的决策、Worker派发、Token消耗都可追溯
- 成本监控:内置Cost Tracking,清晰展示每次运行的开销
- Human in the Loop:Orchestrator进入下一轮前,人可以先审查上一轮的结果
以一个"构建单页看板Web App"的任务为例,Orchestrator初始规划加上给三个Workers写提示词,仅花费约6000个Token——相比纯Claude Code的循环方式,成本控制效果显著。这个数字意味着仅需不到一美分就完成了任务规划和分发,而在纯Loop Engineering模式下,同样的规划阶段可能消耗数万甚至数十万Token。
总结:从Loop Engineering到Harness Engineering
最终结论是:与其叫Loop Engineering,不如叫Harness Engineering。 循环工程的理念有价值——让Coding Agent更自主、能处理更大范围的任务。但前提是你必须有一套合适的系统来驾驭它:
- 确定性流程控制任务推进,而非完全依赖AI决策
- 混合模型策略控制Token成本
- 独立会话避免上下文窗口膨胀
- 持久化存储保障可恢复性
- 可观测性Dashboard让你看清每一步发生了什么
- Human in the Loop在关键节点保留人类判断
这一演进路径与软件工程的历史惊人地相似。早期的CI/CD也经历了从"全自动化"到"可控自动化"的转变——Jenkins最初被设计为完全自动的构建流水线,但实践中团队很快发现需要在关键节点加入人工审批门(Approval Gates)。同样,AI编码自动化也正在从"让AI全权负责"走向"人机协作的可控流程"。
循环工程不需要一个新的Buzzword,但它背后的工程实践——如何设计、监控和优化AI编码的自动化流程——确实值得每一位AI开发者深入研究。随着模型能力的持续提升和工具链的日趋成熟,掌握这套方法论的开发者将在AI辅助编程的新时代中占据显著优势。
核心要点
相关推荐
Claude Code接管WordPress发文实测:AI批量写作会偷懒?
实测Claude Code对接WordPress后台批量发文,发现AI写第一篇质量很高,后续文章却明显放水。分享批量任务质量把控技巧、AI偷懒应对策略及自动化发文方案的实用建议。

Claude Code自动剪辑视频:从素材到成片全流程实操指南
详解如何用Claude Code搭配开源项目VideoIn实现视频自动剪辑,涵盖环境搭建、音频提取、字幕生成、转场效果到成片输出的完整流程,帮助创作者将剪辑时间从数小时压缩到分钟级别。
Claude Code操控虚幻引擎5:两个免费插件实现AI游戏开发
详解Claude Code连接UE5的免费方案,通过Unreal Cloud和Vibe UE两个开源插件,实现AI直接操控虚幻引擎搭建游戏关卡、编辑蓝图、调整材质,附无尽跑酷实战案例与配置教程。