Mac本地跑Qwen3.6-27B:4种方案实测对比

MTP-LX是Mac上运行Qwen3.6-27B的最优方案,速度达43.6 tok/s。
本文对比了Mac上本地运行Qwen3.6-27B模型的四种方案:官网、Anthros GGUF、Anthros MLX+Diflash和MTP-LX。实测显示MTP-LX 4bit方案以43.6 tok/s的速度领先,几乎是其他方案的两倍,且在编码、写作、推理等任务中输出质量可接受。安装简便,是目前Mac用户的最优选择,唯一遗憾是暂不支持图像识别。
前言:27B模型的本地运行挑战
千问3.6 27B(Qwen3.6-27B)自上月发布以来,凭借旗舰级定位和出色的编码能力引发了广泛关注。它的核心卖点在于——用27B参数量挑战前代397B MOE旗舰模型的性能,在SWE Bench Verified、SWE Bench Pro、Terminal Bench 2.0等多项基准测试中均实现超越。
什么是MOE架构? 混合专家模型(Mixture of Experts,MOE)是一种稀疏激活架构:模型拥有大量参数,但每次推理只激活其中一小部分"专家"子网络。397B MOE模型虽然总参数量巨大,但实际激活参数可能仅有数十亿,因此推理成本远低于同等规模的稠密模型。Qwen3.6-27B作为稠密模型,用27B全量参数挑战397B MOE的性能,体现了模型架构和训练效率的显著进步。
SWE-Bench是什么? SWE-Bench(Software Engineering Benchmark)是专门评估大语言模型解决真实软件工程问题能力的权威基准。它从GitHub真实Issue中提取任务,要求模型阅读代码库、理解问题描述并生成能通过单元测试的补丁。SWE-Bench Verified是经过人工验证的高质量子集,SWE-Bench Pro则进一步提升了任务难度。相比传统的代码补全测试,SWE-Bench更贴近开发者的实际工作场景,因此被业界视为衡量编码能力的黄金标准。
然而,对于Mac用户来说,本地运行27B模型面临两大痛点:速度普遍偏慢,以及可选方案太多导致选择困难。从LM Studio、Ollama到OMLX、Diflash MLX、MTP-LX,不同后端的表现差异巨大。本文基于实测,对比4种方案的速度与质量表现,帮你找到最优解。
四种方案速度对比
在Mac上运行Qwen3.6-27B,实测了以下4种方案:
| 方案 | 量化精度 | 生成速度 | 备注 |
|---|---|---|---|
| 千问官网 | 完整精度 | 最优质量 | 需联网 |
| Anthros UD Q5 GGUF | 5bit | ~18 tok/s | 风扇噪音明显 |
| Anthros MLX 6bit + Diflash | 6bit | ~22 tok/s | 速度中等 |
| MTP-LX | 4bit | ~40+ tok/s | 速度翻倍 |
理解量化精度与tok/s 模型量化(Model Quantization)是将神经网络权重从高精度浮点数(如FP32、BF16)压缩为低比特整数表示的技术。4bit量化意味着每个权重仅用4个二进制位存储,相比16bit精度可将模型体积压缩约75%,显著降低内存占用和推理延迟。量化不可避免地引入精度损失,但现代量化算法(如GPTQ、AWQ、GGUF的K-quant系列)通过校准数据集和误差补偿机制,将质量损失控制在可接受范围内。
tok/s(tokens per second,每秒生成的词元数)是衡量推理速度的核心指标。对于中文用户,一个汉字通常对应1-2个token;对于英文,一个单词约为1-1.5个token。人类阅读速度约为5-8 tok/s,因此20 tok/s以上已接近"实时流式输出"的主观体验。40+ tok/s则意味着模型输出速度远超人类阅读速度,用户几乎感受不到等待。
MLX与GGUF的架构差异 MLX是Apple专为Apple Silicon芯片设计的机器学习框架,能够充分利用M系列芯片统一内存架构(UMA)的优势——CPU与GPU共享同一块内存池,避免了传统GPU推理中的数据搬运开销。GGUF(GPT-Generated Unified Format)则是llama.cpp生态的通用模型格式,跨平台兼容性强,但在Apple Silicon上的优化程度不如原生MLX。这也解释了为何表格中MLX方案(22 tok/s)普遍快于GGUF方案(18 tok/s),而深度优化的MTP-LX则在此基础上进一步突破。
最令人意外的是,4bit的MTP-LX方案速度达到了43.6 tok/s,相比6bit MLX + Diflash方案几乎翻倍,而且输出质量依然可圈可点。
编码能力实测:多场景横向对比
3D场景与游戏生成
使用MTP-LX 4bit版本,有博主成功生成了一个元素丰富的3D游戏场景,包含建筑、小车、广场、树木、道路和广告牌等多种元素,效果相当惊艳。
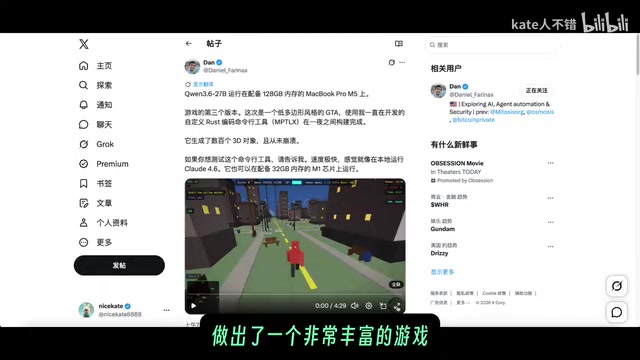
相比之下,官网版本在生成「纤夫拉船」场景时,船体从山体中穿出,存在明显的逻辑问题;部分植物飘浮在空中。而Anthros UD Q5版本生成的十字路口仿真效果则明显较差。
礼物包装智能助手
这个测试场景很好地体现了各方案的差异:
- 官网版本:造型不错,有蝴蝶结设计,但3D预览存在立方体/长方体混淆的bug,包装纸图案区域出现空白
- Anthros Q5版本:3D预览效果尚可,但切换形状后功能缺失,包装步骤指南是亮点
- MTP-LX 4bit版本:界面设计最为精美,点击不同礼物右侧会出现对应预览,场合切换功能正常,包装盒与包装纸有轻微分离
仓库分拣仿真系统
各版本在机械臂仿真任务上都存在不同程度的问题——物体穿模、机械臂细节粗糙、箱子位置摆放不合理等。但考虑到这只是一个4bit量化的27B模型,能在本地以40 tok/s的速度生成这样的结果,已经超出预期。
CSS艺术生成
MTP-LX版本在生成「绵羊理发店」CSS艺术时表现出色:小鸭头上有蝴蝶结、理发师给绵羊理发的场景、格子围布、深红色沙发——多个物体的位置摆放和细节处理都相当精细,唯一遗憾是窗户与门重合。

MTP-LX安装与配置指南
MTP-LX的安装流程相当简洁:
- 安装:通过
brew install完成基础安装 - 初始化:运行
mtplx start,进入交互式命令界面 - 选择模型:首次使用推荐选择默认的 speed 模型(即4bit版本),如需更高质量可下载作者发布的高质量版本
- 选择模式:按默认模式即可
- 接入方式:支持 Web UI、OpenCode 等多种对话渠道

配置完成后,MTP-LX会自动被 Open WebUI 识别,无需额外设置。在参数调整方面,千问官方建议编码任务使用温度0.6,一般任务使用温度1.0。
温度参数(Temperature)的含义 温度是控制语言模型输出随机性的超参数。温度越低(趋近0),模型越倾向于选择概率最高的词元,输出更确定、更保守;温度越高,模型的采样分布更平坦,输出更多样、更有创意但也更容易出错。编码任务需要精确性,因此推荐较低的0.6;创意写作或通用对话则适合更高的1.0,以获得更自然流畅的表达。
值得一提的是,知名开发者Ivan测试了MTP-LX 0.3.5版本,在数学基准测试中5分30秒内取得了93.3%的正确率,验证了4bit量化下的输出质量依然可靠。
写作与推理能力简测
除编码外,MTP-LX 4bit版本在其他任务上的表现也值得关注:
写作能力:让它将「他很难过」改写为有画面感的句子,输出为「他蜷在墙角,把脸埋进臂弯,肩膀无声地起伏」——简洁有力,没有浓重的AI味。辞职文案「交还钥匙,晴空日晨不回头,谢幕只向前迎风,原来转身也可以这么轻」也颇为洒脱。
推理能力:面对「月收入7000、一线城市、四年凑够60万」的理财规划题,模型思考了11分钟给出详细方案。经GPT-5.5 Thinking评分为55分(满分100),而同题GPT-5.5 Pro得分82分——与顶尖模型确实存在差距,但对于本地运行的27B模型而言已属不易。
幻觉测试:询问「李白在98年纽约马拉松获得亚军」这类荒谬问题时,模型能正确识别出历史时间矛盾,未产生幻觉。
幻觉(Hallucination)问题 大语言模型的"幻觉"是指模型生成看似合理但实际上错误或虚构的内容,这是当前LLM的主要缺陷之一。幻觉产生的根本原因在于模型本质上是概率性的文本预测系统,而非真正的知识检索系统。测试模型对荒谬前提的识别能力,是评估其事实可靠性的重要维度。Qwen3.6-27B在此测试中表现良好,说明其在训练阶段对事实一致性有较好的对齐。

总结与推荐
经过四种方案的全面对比,MTP-LX是目前Mac上运行Qwen3.6-27B的最优选择:
- 速度优势明显:4bit量化下达到40+ tok/s,是其他方案的近两倍
- 质量可接受:虽然是4bit,但编码、写作、推理等任务的输出质量均在合理范围内
- 安装简便:几条命令即可完成部署,自动兼容Open WebUI
当前的遗憾是MTP-LX暂不支持图像识别能力。如果你需要视觉理解功能,可能需要考虑其他方案。但就纯文本和编码任务而言,MTP-LX + Qwen3.6-27B的组合已经能在Mac上提供相当流畅的本地AI体验。
对于Mac用户来说,27B参数量的模型能以40+ tok/s的速度流畅运行,这在一年前几乎不可想象。Apple Silicon的统一内存架构(UMA)使得大模型推理不再受限于独立显存容量,而MLX等原生框架的持续优化则进一步释放了硬件潜力。本地AI的可用性正在快速提升,值得每一位开发者关注和尝试。
核心要点
- MTP-LX 4bit方案在Mac上运行Qwen3.6-27B可达43.6 tok/s,速度是其他方案的近两倍
- 四种方案对比:官网 > MTP-LX 4bit > Anthros MLX 6bit + Diflash > Anthros UD Q5 GGUF,MTP-LX在速度与质量间取得最佳平衡
- 27B模型在编码任务上表现出色,能生成包含丰富元素的3D场景、交互式应用和CSS艺术
- MTP-LX安装简便,支持Open WebUI自动识别,但暂不支持图像识别功能
- 4bit量化的27B模型在写作和推理任务上质量可接受,但与GPT-5.5 Pro等顶尖模型仍有差距
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。