MCP vs Function Calling:本质区别与选型指南
引言:一个让开发者困惑的问题
大模型已经能通过Function Calling调用外部工具了,为什么业界还要费力推出MCP(Model Context Protocol)协议?这不是多此一举吗?
这个问题看似简单,实则触及了AI应用开发从"手工作坊"迈向"工业化生产"的关键转折点。今天我们就来深入拆解MCP与Function Calling的本质区别,以及各自的适用场景。


Function Calling:模型的"意图翻译器"
本质定义
Function Calling本质上是大模型的一种原子能力。模型本身只能生成文本,无法直接操作数据库或发送邮件。Function Calling的作用,是让模型把用户的自然语言翻译成一份标准化的、机器能读懂的JSON格式指令。
简单来说,它是模型的"嘴巴和手"——让模型能够表达意图并触发外部动作。
从技术实现上看,Function Calling的工作流程分为几个关键步骤:开发者首先通过JSON Schema格式定义可用函数的名称、参数类型和描述信息,然后将这些定义随用户消息一起发送给大模型API。模型在推理过程中,会判断当前用户意图是否需要调用某个函数,如果需要,模型不会直接返回自然语言回答,而是返回一个结构化的JSON对象,包含要调用的函数名和对应参数。随后,应用层代码负责解析这个JSON、执行实际的函数调用、获取结果,再将结果回传给模型生成最终的自然语言回复。这一能力最早由OpenAI在2023年6月的GPT-3.5/GPT-4 API更新中正式引入,随后Google的Gemini、Anthropic的Claude以及众多开源模型纷纷跟进实现了类似功能,但各家的API格式和参数定义方式存在显著差异。
Function Calling的痛点
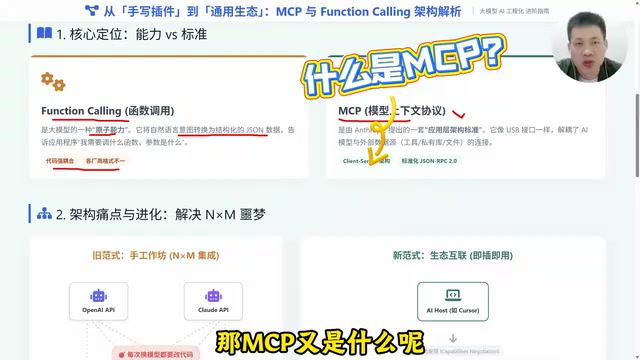
问题在于,使用Function Calling需要在代码里硬编码工具定义。对接OpenAI有一套格式,换成Claude又是另一套格式,换成Gemini还得重写。这就是典型的强耦合问题。
更致命的是所谓的"N×M噩梦":市面上有N个大模型(OpenAI、Claude、Gemini、各种开源模型),同时有M个工具(数据库、GitHub、Slack、本地文件库)。在Function Calling模式下,如果想让每个模型都能调用每个工具,理论上需要编写N×M份适配代码。
这个问题在软件工程领域并不新鲜——它本质上是经典的"集成复杂度爆炸"问题。在企业IT历史上,类似的困境曾反复出现:早期的数据库连接需要为每种数据库写专用驱动,直到ODBC/JDBC标准出现才得以缓解;Web服务领域也经历了从私有RPC协议到REST/GraphQL标准化的演进。引入中间抽象层将N×M的复杂度降为N+M,是软件架构设计中屡试不爽的策略。然而在AI工具调用领域,由于大模型厂商迭代速度极快、工具生态爆发式增长,这种集成痛苦被急剧放大——一个中型AI应用可能需要同时对接3-5个模型和10-20个外部工具,手动维护几十份适配代码的成本已经高到不可接受。
这种手工作坊式的开发方式,在AI应用爆发的今天显然难以为继。
MCP协议:AI世界的"USB接口"
从能力到架构的跃迁
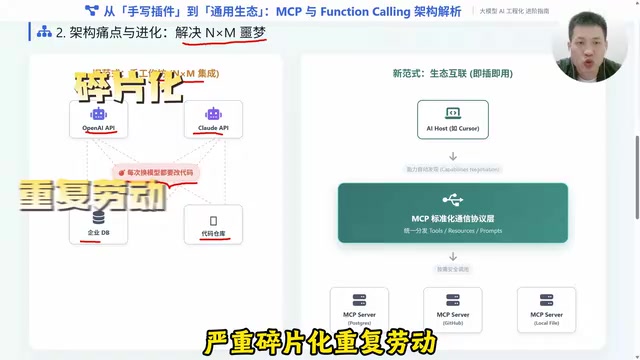
MCP(Model Context Protocol,模型上下文协议)不再仅仅是一个能力,而是一套标准化的架构。它规定了模型客户端和服务端之间的通信方式,把"怎么调工具"这件事彻底标准化了。
用一个形象的比喻:在USB接口出现之前,接鼠标、键盘、打印机都需要专门的接口。有了USB之后,一个口什么都能插。MCP做的就是这件事——为AI工具调用提供统一的"接口标准"。
MCP协议由Anthropic公司于2024年11月正式发布并开源,其设计目标是成为AI应用与外部数据源、工具之间的通用连接标准。从协议层面看,MCP基于JSON-RPC 2.0规范构建——这是一种轻量级的远程过程调用协议,使用JSON格式编码请求和响应,支持请求-响应和单向通知两种通信模式。在传输层,MCP提供了两种主要的通信方式:stdio(标准输入输出) 适用于本地进程间通信,启动快、延迟低,非常适合桌面应用场景(如Cursor、Claude Desktop);HTTP + SSE(Server-Sent Events) 则适用于远程服务部署,支持跨网络访问,更适合企业级和云端场景。这种分层设计让MCP既能在本地轻量运行,也能在分布式环境中灵活扩展。
MCP的Client-Host-Server架构
MCP采用Client-Host-Server架构。开发者只需要编写一个通用的MCP Server(比如一个接入PostgreSQL数据库的服务),那么不管是Cursor编辑器、Claude桌面端还是Windsurf,只要支持MCP协议,就能直接"插上去"使用,完全不需要重复开发。
具体来说,这三层架构各有明确的职责分工。Host(宿主) 是用户直接交互的应用程序,比如Claude Desktop、Cursor IDE或任何集成了MCP的AI应用,它负责管理整个会话的生命周期、执行安全策略、协调多个Client的工作。Client(客户端) 由Host内部创建和管理,每个Client与一个特定的MCP Server建立一对一的连接,负责协议层面的消息收发和能力协商——当连接建立时,Client和Server会互相交换各自支持的协议版本和能力清单,这个过程称为"能力协商(Capability Negotiation)"。Server(服务端) 则是实际暴露工具、资源和提示词的服务进程,它可以是一个连接数据库的本地脚本,也可以是一个部署在云端的微服务。这种分层设计的精妙之处在于:一个Host可以同时连接多个Server(比如同时接入GitHub Server、数据库Server和文件系统Server),而每个Server又可以被多个不同的Host复用,真正实现了多对多的灵活组合。
这意味着:写一次代码,到处运行。
MCP与Function Calling的三个本质差异
差异一:耦合度不同
Function Calling把工具逻辑"焊死"在业务代码里。想增加一个工具?停机、改代码、改Schema。
MCP则是彻底解耦的:Server独立运行,Host动态发现。这种即插即用的灵活性,才是工业化开发的标配。
差异二:交互广度——MCP的三位一体能力
很多人以为MCP只能调工具,实际上MCP实现了三位一体的能力:
- Tools(工具):执行动作,这是与Function Calling重叠的部分
- Resources(资源):静态上下文的挂载。比如几万行的代码库或巨大的PDF文档,Function Calling很难直接处理,但MCP可以通过Resource机制让模型像读取外部硬盘一样按需订阅和加载上下文
- Prompts(提示词):服务端可以统一下发提示词模板,让Prompt管理也变得标准化
Resources机制的设计尤为精巧。每个资源通过URI(统一资源标识符) 进行寻址,例如file:///workspace/src/main.py代表本地文件,postgres://database/users/schema代表数据库表结构。资源分为两种类型:直接资源(Direct Resources) 由Server主动暴露,Client可以直接列举和读取;资源模板(Resource Templates) 则是动态的URI模板,支持参数化查询,比如github://repos/{owner}/{repo}/issues可以根据不同的仓库动态获取Issue列表。更重要的是,Resources支持订阅机制——Client可以订阅某个资源的变更通知,当资源内容发生变化时(比如数据库记录更新、文件被修改),Server会主动推送更新,模型可以据此刷新上下文。这种能力让大模型不再是"一次性读取、静态推理",而是能够持续感知外部数据的变化。
Prompts机制则解决了另一个长期困扰开发者的问题:提示词的碎片化管理。在传统开发中,Prompt往往散落在各处代码里,难以统一维护和版本管理。MCP允许Server端定义标准化的Prompt模板,包含名称、描述、参数列表和模板内容,Client端可以动态发现和调用这些模板。例如,一个代码审查MCP Server可以提供名为code_review的Prompt模板,接受编程语言和代码片段作为参数,返回经过精心设计的审查提示词。这让Prompt的管理从"各自为战"变成了"集中治理"。
这三个维度的组合,让MCP协议的能力边界远超Function Calling。
差异三:安全性架构
在企业级应用中,安全性至关重要。
Function Calling的工具逻辑在应用内部执行,一旦模型生成危险指令,防御链路非常短。
而MCP采用Server架构,可以将其部署在Docker容器或远程沙箱中运行,设置严格的只读权限,甚至在网络层做隔离。这种安全纵深是原生Function Calling很难比拟的。
这种安全设计理念与当前企业安全领域的零信任架构(Zero Trust Architecture) 高度契合。零信任的核心原则是"永不信任,始终验证"——不因为请求来自内部网络就默认信任,每次访问都需要经过身份验证和权限校验。MCP的Server架构天然支持这种模式:每个MCP Server可以独立设置访问控制策略,比如数据库Server只开放只读查询权限、文件系统Server限制只能访问特定目录、API Server对敏感操作要求二次确认。通过将Server部署在Docker容器中,还可以利用容器的命名空间隔离(Namespace Isolation) 和资源限制(cgroups) 机制,确保即使某个Server被恶意利用,攻击面也被严格限制在容器边界内,不会波及宿主系统和其他服务。此外,MCP协议在设计上强调人机协同(Human-in-the-Loop) 原则——对于高风险操作(如删除数据、执行系统命令),Host应用应当在执行前向用户请求明确授权,而不是让模型自主决策,这为安全防护增加了关键的人工审核环节。
如何选择:场景决定方案
适合选Function Calling的场景
- 简单的、工具固定的SaaS应用
- 轻量级的聊天机器人(如微信机器人)
- 对延迟极度敏感的场景
原因:链路短、无额外协议开销、部署简单。没必要为一个简单的API调用去搭一套MCP服务。
适合选MCP协议的场景
- 构建复杂的AI Agent系统
- 工具需要被不同AI平台(Cursor、Windsurf、Claude)共同调用
- 需要接入企业内部私有数据库和代码仓库
- 追求生态复用率和长期可维护性
值得注意的是,AI Agent(智能体)的发展正在从单一的"对话-回复"模式快速演进为多步骤、多工具协作的复杂系统。现代AI Agent往往需要在一次任务中串联多个工具——比如先查询数据库获取用户信息,再调用内部API生成报告,最后通过邮件服务发送结果。在这种场景下,Agent需要一个统一的协议来发现、协商和调用各种异构工具,而不是为每个工具硬编码调用逻辑。MCP正是为这种复杂协作场景而生的基础设施。随着LangChain、AutoGen、CrewAI等Agent框架纷纷宣布支持或计划集成MCP协议,MCP正在成为AI Agent生态的"连接层标准"。可以预见,未来的AI Agent开发将越来越像搭积木——开发者从MCP Server生态中选取所需的工具模块,通过标准协议组装成完整的智能体系统,而不是从零开始编写每一个集成逻辑。
总结:从手工作坊到工业化生产
| 维度 | Function Calling | MCP协议 |
|---|---|---|
| 本质 | 原子能力 | 标准协议 |
| 耦合度 | 强耦合 | 完全解耦 |
| 交互范围 | 工具调用 | 工具+资源+提示词 |
| 安全性 | 应用内执行 | 沙箱隔离 |
| 适用场景 | 简单应用 | 复杂Agent系统 |
一句话总结:Function Calling解决的是"模型怎么表达意图"的问题,MCP解决的是"工具怎么标准化接入"的问题。
前者是嘴巴和手,后者是中枢神经系统和通用接口。从手写插件到通用协议,这是大模型应用开发从手工作坊向工业化生产跨出的关键一步。
未来,开发者可能不再需要为每个模型写枯燥的适配逻辑,而是直接发布一个个MCP Server,让AI生态像搭积木一样连接起来。这不是多此一举,而是必然的进化方向。
相关推荐
Codex编程智能体全解析:和ChatGPT到底有什么区别?
深入解析OpenAI Codex编程智能体的核心能力,对比Codex与ChatGPT在编程场景中的本质区别,帮助开发者理解AI编程智能体如何改变软件开发模式。

Databricks开源Omni:统一管理所有AI Agent的元框架
Databricks以Apache 2.0协议开源Omni项目,通过元框架统一管理Claude Code、Codex等多个AI Agent。支持统一会话、跨供应商交叉审查、安全策略强制执行和实时协作,彻底解决多Agent协同与供应商锁定问题。
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。