MCP没死!Anthropic两大杀招降本85%+12大Agent模式全解析

MCP未死,重定位云端主战场并大幅降本,配合12大Agentic模式构建生产级Agent架构。
面对社区对MCP成本高、占上下文、协议臃肿的批评,Anthropic将MCP战略重定位为云端标准化远程接入层,与本地CLI形成分工互补。通过工具搜索和代码沙箱两大技术,token消耗降低85%以上,成本差距从32倍缩至7倍。同时,文章拆解了生产级Agent内部运作的12大Agentic模式,涵盖记忆管理、工作流编排、权限切分和确定性自动化四大维度,构成完整的分层架构体系。
引言:MCP真的要凉了吗?
最近AI Agent圈子里最火的争议莫过于"MCP即将被淘汰"的论断。有测试发现,使用MCP的操作成本竟然是传统CLI的17倍,甚至能一口气吃掉大模型72%的上下文窗口。很多人直呼这玩意儿又贵又笨重,彻底没用了。
但事实真的如此吗?Anthropic官方给出了一个非常聪明的反转——MCP不仅没死,反而找到了自己真正的主战场。本文将从MCP的危机与重定位、官方降本技术、12大Agentic模式、以及未来多维协作生态四个维度,为你彻底拆解生产级AI Agent的规划架构。
MCP的三大痛点与战略重定向
社区吐槽最狠的三个问题
社区对MCP的批评总结起来就是三个字:太贵、太占、太笨。
- 成本悬殊:严格测试表明,干同样一件事,CLI的成本只有MCP的1/17
- 性能拖累:Perplexity的CTO直接表态内部正在远离MCP,因为它吃掉了模型72%的上下文窗口
- 协议臃肿:以GitHub MCP为例,里面有43个工具,每次交互都要把全部工具说明书打包给大模型,光说明书就浪费4000多个token
Anthropic的聪明反转
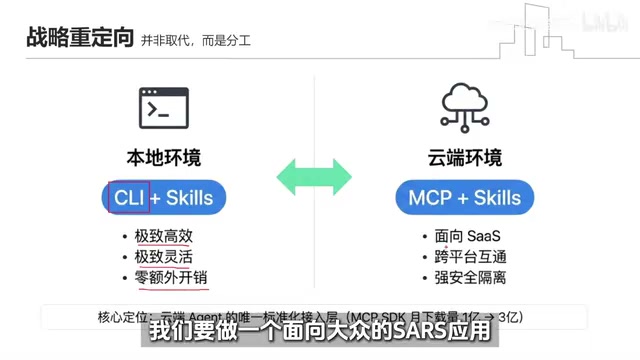
Anthropic并没有硬钢,而是做了一次战略重定向。官方坦诚承认:在本地开发环境追求极致高效和零额外开销,CLI确实是王者。
但关键趋势是——越来越多的生产级Agent跑在云端。在云端环境(SaaS应用、跨平台App),没有本地文件系统让你敲命令行。MCP提供的是一个强安全隔离的标准化远程接入层。
打个比方:本地自己搞小作坊用CLI效率最高,但要开全国连锁店服务千万用户,就必须有MCP这样的云端标准协议。这不是谁取代谁,而是分工不同:
- 本地环境 → CLI + Skills
- 云端环境 → MCP + Skills
定位一明确,市场也用脚投票了——MCP SDK月下载量短短几个月从1亿飙升到3亿。
官方两大杀招:Token降本85%以上
定位虽然理清了,但MCP在云端吃token的毛病总得解决。Anthropic放出了两个大招。
第一招:Tool Search工具搜索
过去让大模型调用工具的做法很粗暴——每次都把一整本厚厚的工具说明书全盘塞给模型,100%的token载入。
现在的逻辑完全变了:不再按API功能死板罗列,而是围绕用户真实意图动态抽取。模型先表达想做什么,系统再精准找出对应的那几页说明书递给模型。
这种按需加载的方式直接砍掉80%以上的工具定义token,且工具选择准确率没有任何下降。
第二招:程序化工具调用(代码沙箱)
工具返回的数据往往太多,原始数据直接涌入上下文会撑爆计费表。核心理念就一句话:别让模型当搬运工,让它写代码。
系统给模型提供一个安全的代码沙箱,工具拿到海量原始数据后,模型可以在沙箱里写一小段代码做条件过滤、算总数、重新排版,最后只把精炼后的结果拿回来。
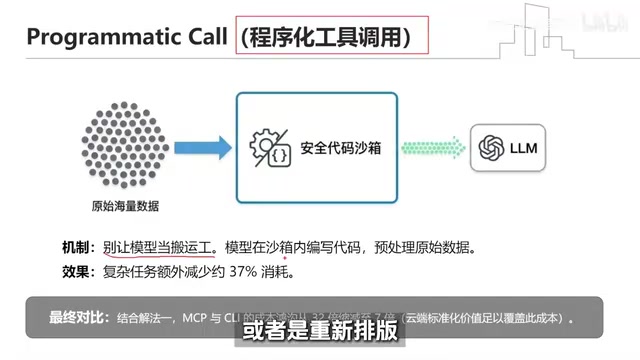
官方数据显示,处理复杂任务时这招能额外减少约37%的token消耗。
实际效果:从32倍差距缩减到7倍
两招叠加:砍掉85%说明书 + 省下37%数据搬运开销,成本差距从极端情况下的32倍直接缩减到约7倍。对于云端生产环境来说,花这点稍高的成本换取强安全隔离和跨平台标准化,完全划算。
实战案例:Cloudflare的极简哲学
Cloudflare需要通过MCP对外开放约2500个API端点。按老做法全部罗列给模型绝对是灾难。他们的解法极其聪明——只对外暴露两个工具:search和execute。
Agent先用search在2500个端点里精准搜到需要的API,再用execute在服务端执行具体操作。整个交互消耗的token只有区区1000个左右。这完美诠释了Anthropic的理念:好的MCP服务应该像设计CLI一样设计,让Agent通过代码编排服务。
12大Agentic模式:Agent内部大脑全拆解
解决了外部连接问题只完成了一半工作。一个真正的生产级Agent,内部大脑怎么运作才是成败关键。这套从Claude Code内部透出的12大模式,分为四大维度。
维度一:记忆与上下文管理
过去我们把公司规范、项目要求全塞进系统提示词,结果臃肿不堪。现在变成了按需、分层级的动态组装。
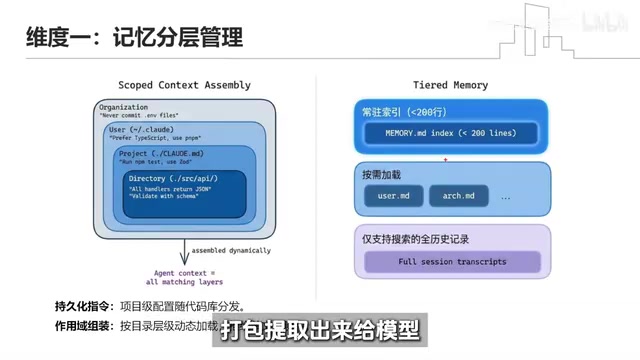
比如你在写后端API接口,系统只把外层通用架构规范 + 当前API目录下的专属规则提取出来,不相关的一概不管。记忆存储也分层:
- 常驻记忆:核心200行以内的规矩,永远跟着模型
- 触发加载:架构设计图等,触发特定场景再加载
- 历史归档:过去几十轮的聊天记录,只允许搜索,绝不占活跃内存
为对付上下文衰减,引入两个巧妙机制:
- 闲时梦境整合:类似人类睡眠时大脑整理记忆,Agent闲置时后台守护进程清洗重复/冲突记忆
- 渐进式压缩:快撞红线时,对老旧历史做轻度总结折叠,保证大脑始终清醒有余量
维度二:工作流编排
很多Agent拿到需求直接上手就干,结果搞崩代码。生产级做法引入强制约束:先探索、再规划、最后才执行。
在探索和规划阶段,Agent权限被锁死——只能读不能写。就像木工"量两次切一次",想清楚再动手。
对于复杂的无依赖任务(比如同时改三个互不相关的模块),系统用Fork-Join并行模式:克隆出多个子Agent同时干活,复用父节点缓存,干完后快速合并。
维度三:工具权限精细切分
过去图省事直接给大模型万能Shell环境,等于把金库钥匙交给实习生。现在的最佳实践是单用途极简工具集 + 风险矩阵:
- 🟢 绿色(跑测试):自动放行
- 🟡 黄色(推送代码):弹窗确认
- 🔴 红色(删库等危险操作):直接拦截
用精准的类型控制取代失控的万能权限。
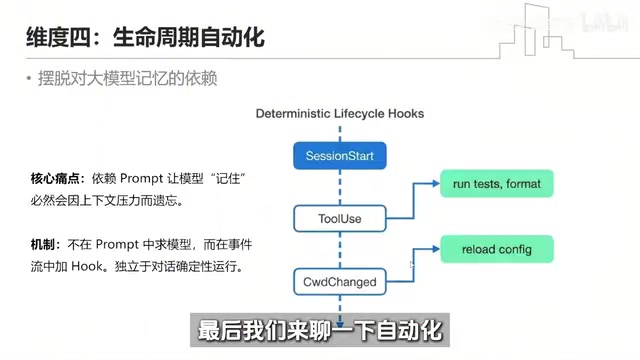
维度四:确定性自动化
在prompt里千叮万嘱"写完代码记得格式化",模型上下文一长就忘。解法是把这些动作从prompt里抽出来,放到事件流里加Hook。
只要系统监测到文件被修改或新任务开始,后台自动跑测试、自动格式化。不再求着大模型记住繁琐流程,而是让外部系统做确定性拦截。
未来蓝图:多维协作的Agent生态
在架构选型上从来不存在万能解。路线图非常清晰:
- 简单任务(查天气、写脚本)→ 直连API,不必搞重架构
- 本地开发追求极致效率 → CLI + Skills,王者组合
- 云端SaaS面向大众用户 → MCP + Skills,安全边界和标准化是生死命门
现在很多头部服务商(Tempo、Notion等)在发布MCP服务器时都会配套发一套Skills。逻辑很巧妙:MCP负责把路修通,Skills像教练告诉Agent怎么开车。
但不管外面选CLI还是MCP,只要任务复杂、状态开始流转,背后支撑的内核始终是那12大Agentic模式。没有清晰的内部大脑做编排,外部连接做得再好也是一团乱麻。
总结
MCP并没有死,它只是非常清醒地找到了属于自己的主战场——云端。官方用工具搜索和代码沙箱两大杀招把token消耗硬生生压了下来,配合内部12个编排模式和外部Skills的指导配合,一套真正安全的生产级Agent架构已经实实在在摆在我们面前。
对于开发者来说,理解这套分层架构的底层逻辑,在接到需求时就能精准选择武器——这才是AI应用落地的核心竞争力。
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。