Milvus 2.6核心新特性详解:分层存储、架构解析与RAG实战

Milvus 2.6核心特性与RAG实战落地方案解析
本文系统介绍了Milvus作为AI时代核心基础设施的定位,阐述了向量数据库解决非结构化数据相似度检索的本质问题,详细解析了Milvus 2.6的云原生存算分离架构设计,并结合RAG系统实战场景,帮助开发者理解企业级向量数据库的技术原理与落地方案。
为什么Milvus是AI时代的必备基础设施
2026年,大模型应用持续爆发,向量数据库已经成为AI应用开发中绕不开的核心组件。如果说MySQL是传统Java开发的标配,那Milvus就是AI大模型时代的"MySQL"——它是目前全球最受欢迎的开源向量数据库,GitHub上拥有数万star,社区活跃度极高。
本文基于一场深度技术公开课的内容,系统梳理Milvus 2.6.x版本的核心新特性,并结合高性能RAG(检索增强生成)项目实战,帮助开发者快速掌握企业级向量数据库的落地方案。
向量数据库的本质:从精确查询到相似度检索
传统关系型数据库的局限
MySQL等关系型数据库擅长处理结构化数据的精确查询:等值匹配、范围查询、模糊搜索(LIKE语句)等。但面对AI时代的非结构化数据——图片、文本、音频、视频——传统数据库就显得力不从心了。
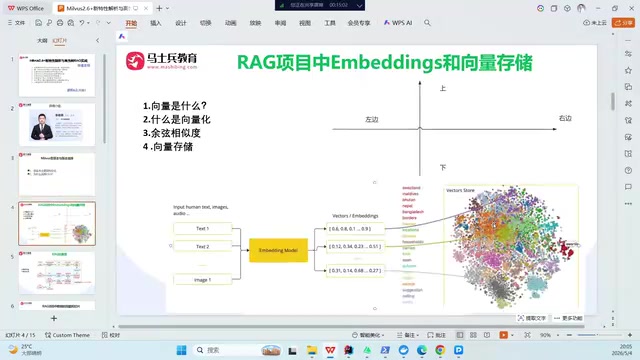
向量数据库到底解决什么问题
Milvus的核心能力是计算向量相似度。举个直观的例子:假设你有一个包含几十亿张图片的数据库,现在需要在几毫秒内找到一张与你家猫最相似的图片。这种高维向量的快速检索,正是Milvus的核心价值。
向量数据库的工作流程可以概括为四步:
- 向量化(Embedding):将非结构化数据(文本、图片等)通过模型转换为高维向量
- 向量存储:将向量数据高效写入数据库并建立索引
- 相似度计算:通过余弦相似度、欧氏距离等算法,快速找到最相似的向量
- 结果返回:将检索结果返回给上层应用
向量化(Embedding)的技术原理
向量化是将非结构化数据映射到高维数学空间的过程。以文本为例,BERT、GPT等预训练语言模型能将一段文字转换为768维或1536维的浮点数数组。这个数组在数学空间中的位置,编码了原始内容的语义信息——语义相近的内容,其向量在空间中的距离也更近,这一特性是向量检索的数学基础。图像领域的CLIP模型更进一步,能将图片和文字映射到同一向量空间,实现跨模态检索。向量维度越高,表达能力越强,但计算开销也随之增大,这是工程实践中需要权衡的核心矛盾。
这套流程在RAG系统中尤为关键——用户的查询被转换为向量后,在知识库中检索最相关的文档片段,再交给大模型生成回答。
RAG系统的完整技术链路
RAG(Retrieval-Augmented Generation,检索增强生成)是目前企业级大模型落地的主流架构范式,其核心思路是将大模型的生成能力与外部知识库的检索能力结合,解决大模型知识截止、幻觉频发、私域数据无法利用等痛点。完整的RAG链路包括两个阶段:离线阶段(文档解析→文本分块→Embedding向量化→写入向量数据库)和在线阶段(用户提问→查询向量化→向量检索→召回文档重排序→构建Prompt→LLM生成回答)。其中,文本分块策略(Chunk Size、重叠窗口)、检索召回数量(Top-K)、重排序模型(Reranker)的选择,是影响RAG系统最终效果的三个关键变量,也是工程优化的主战场。
Milvus 2.6云原生架构深度解析
核心组件与架构设计
Milvus 2.6采用了完全云原生的架构,这也是企业选择它的重要原因之一。架构中包含几个核心组件:
- Coordinator(协调器):负责将不同类型的操作路由到对应的处理节点
- Stream Node(流式节点):处理实时数据流的写入和消费
- Query Node(查询节点):承担向量检索查询的计算任务
- Data Node(数据节点):管理数据的持久化存储和索引构建
云原生架构与存算分离设计
Milvus 2.6的云原生架构核心是存算分离设计。传统数据库将计算和存储耦合在同一节点,扩容时必须同步扩展两种资源,成本高且灵活性差。Milvus将数据持久化到对象存储(S3/MinIO),计算节点(Query Node、Data Node)无状态化,可以独立弹性伸缩。这意味着查询压力大时只需扩展Query Node,存储压力大时只需扩展对象存储容量,资源利用率大幅提升。etcd在此架构中承担分布式协调角色,存储集群元数据和节点状态,是整个系统的"神经中枢"。这种架构设计使Milvus天然适配Kubernetes的Pod弹性调度能力,也是它被称为"云原生向量数据库
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。