Minimax M3 vs DeepSeek V4实测:恐龙快跑游戏谁更强

最近国产大模型赛道又热闹起来了——Minimax 发布了新模型 M3,号称性能全球前三,支持 1M 上下文和原生多模态。另一边,DeepSeek V4 Pro 也在开发者圈子中备受关注。两款国产顶级模型,到底谁的代码生成能力更强?B站UP主用同一份提示词,让两个模型各做一款"恐龙快跑"游戏,结果差距出乎意料。
2024年至2025年,国产大模型赛道经历了从"百模大战"到"头部收敛"的过程。DeepSeek凭借开源策略和极致的性价比(V3系列的训练成本仅为同级别模型的几分之一)迅速崛起,其MoE(混合专家)架构和Multi-head Latent Attention等创新技术引发了全球关注。MoE(Mixture of Experts,混合专家)架构是DeepSeek系列模型的核心技术支柱。传统的Transformer模型在每次推理时会激活所有参数,而MoE架构将模型的前馈网络层拆分为多个"专家"子网络,每次推理时只激活其中一小部分专家来处理当前输入。这种设计使得模型可以拥有极大的总参数量(从而具备强大的知识容量),但实际计算成本只相当于一个小得多的模型。DeepSeek V3采用的MoE架构拥有6710亿总参数,但每次推理仅激活约370亿参数,这正是其能以极低训练成本达到顶级性能的关键原因。而Multi-head Latent Attention(MLA)则通过将KV缓存压缩到低维潜在空间中,大幅降低了推理时的显存占用和计算开销,使得长上下文推理变得更加高效。
Minimax则走了一条差异化路线,从早期的语音合成(海螺AI)到如今的原生多模态大模型,始终强调多模态融合能力。此外,阿里的通义千问、字节的豆包、百度的文心一言等也在各自的优势领域持续迭代。这场竞争的焦点已经从单纯的基准测试分数,转向了实际应用场景中的综合体验——包括代码生成、多模态理解、Agent能力、推理速度和成本控制等多个维度的综合较量。
测试方案:同一提示词,Minimax M3 与 DeepSeek V4 双模型对决
这次测试的思路非常直接:准备一份恐龙快跑类型游戏的提示词,同时分别输入 Minimax M3 和 DeepSeek V4 Pro,观察两者在代码生成、游戏画面、可玩性等维度的表现。

在 Minimax 这边,使用的是 Minimax Code 平台,选择 M3 模型。模型接收到提示词后,会先自动拆分任务、列出详细的执行计划,然后按步骤逐一完成,最终将整个游戏代码打包输出。DeepSeek V4 Pro 那边也是类似的流程——粘贴同样的提示词,选择模型,点击运行,等待几分钟即可得到结果。
两个模型都在几分钟内完成了任务,速度上没有明显差距。真正的差别,体现在最终生成的游戏质量上。
游戏效果对比:画面精美度差距明显
先来看 Minimax M3 生成的恐龙快跑游戏。打开后第一感觉就是——画面相当精美。场景和角色都是通过 AI 绘画生成的,视觉效果远超普通的代码生成游戏。更让人惊喜的是,游戏还支持随机生成各种地图,可玩性大幅提升。
这里值得深入解释的是,M3在游戏生成过程中调用图像生成能力来美化素材,背后涉及一套完整的技术链路。原生多模态模型在生成游戏代码的同时,能够理解游戏场景的视觉需求,并生成对应的图像资源(如角色精灵图、背景贴图、UI元素等)。这些图像通常以Base64编码或URL引用的形式直接嵌入到HTML/CSS/JavaScript代码中。相比之下,传统的纯文本代码生成模型只能使用CSS绘制简单的几何图形,或者引用外部开源素材库,视觉表现力受到很大限制。
再看 DeepSeek V4 Pro 的作品。总体来说,游戏是能正常运行、正常游玩的,也有部分音效加持,基本功能没有问题。但在画面精美度上,和 M3 的作品放在一起对比就显得逊色不少。
这个差距的核心原因在于两者的架构差异。Minimax M3 具备原生多模态能力——视觉和文本在同一个参数空间中被处理,这意味着它在生成游戏时,不仅能写代码,还能同步调用图像生成能力来美化游戏素材。而 DeepSeek V4 Pro 虽然代码能力强劲,但在多模态融合方面暂时还没有达到同样的深度。
所谓原生多模态(Native Multimodal),是相对于"管道式多模态"而言的一种架构设计理念。传统的多模态模型通常采用模块拼接的方式——先用一个视觉编码器(如CLIP或ViT)将图像转换为特征向量,再将这些向量输入到语言模型中进行处理,各模块之间存在信息瓶颈。而原生多模态则是在模型训练阶段就将文本、图像、音频等不同模态的数据放在统一的参数空间中进行联合训练,使模型从底层就具备跨模态的理解和生成能力。这种架构的优势在于模态之间的信息流通更加顺畅,模型能够真正"理解"图像内容与代码逻辑之间的关联,而不仅仅是将图像描述翻译成文字后再处理。Google的Gemini系列是这一路线的代表,Minimax M3也采用了类似的技术路径。
进阶测试:用截图复刻象棋游戏验证多模态理解力
为了进一步验证 M3 的多模态理解能力,UP主还做了一个更有挑战性的测试——用几张象棋游戏的截图,让 M3 直接复刻出一个可玩的象棋游戏。

这一测试实际上考验了模型的多项核心能力。首先是视觉理解能力——模型需要从截图中识别出棋盘布局、棋子类型、UI元素的位置和样式等信息;其次是领域知识——中国象棋有复杂的走子规则(如马走日、象飞田、将帅不能照面等),模型需要将视觉信息与象棋规则知识进行关联;最后是代码实现能力——将上述理解转化为可运行的前端代码,包括棋盘渲染、点击交互、走子合法性判断、胜负检测等完整的游戏逻辑。这种从视觉输入到功能性代码输出的端到端任务,是评估多模态模型综合能力的理想测试场景,因为它要求视觉理解、逻辑推理和代码生成三种能力的紧密协作。
第一个版本出来后,象棋游戏的基本功能已经可以正常运行,棋子走法、规则判定都没有大问题。但画面比较粗糙,用UP主的话说就是"像个毛坯房"。
这时候,M3 的原生多模态能力就派上了用场。通过让模型生成一张精美的棋盘图片作为参考素材,再重新渲染游戏界面,最终效果就精致多了。

这个过程展示了一个重要的工作流:先用 AI 搭建功能框架,再用多模态能力打磨视觉体验。这种"代码+设计"一体化的能力,是纯文本模型很难做到的。
Minimax M3 的三大核心优势分析
从这次实测来看,Minimax M3 的竞争力主要体现在三个方面:
原生多模态融合
视觉理解和文本生成在同一参数空间中处理,不是简单的模块拼接。这让它在处理涉及图像的任务时(如截图复刻、游戏素材生成)有天然优势。你可以上传一段视频让它理解内容并整理成文档,也可以通过一张截图让它复刻网站或游戏。
Coding Agent 能力
不只是单纯地生成代码片段,M3 具备完整的问题拆解和任务规划能力。面对复杂需求时,它会先分析任务结构,制定执行计划,然后逐步实现。这种 Agent 化的工作方式,让它在处理完整项目时表现更加稳定。
Coding Agent是大模型从"代码补全工具"向"自主编程助手"演进的重要形态。早期的代码生成模型(如Codex、CodeLlama)主要擅长根据注释或上下文补全代码片段,但面对复杂的工程级任务时往往力不从心。Coding Agent的核心突破在于引入了任务规划(Planning)、工具调用(Tool Use)和自我反思(Reflection)等机制。模型在接收到复杂需求后,会先将任务分解为多个子步骤,制定执行计划,然后逐步实现每个子任务,并在过程中检查错误、自动修复。这种工作方式借鉴了软件工程中的项目管理思想,使AI能够处理涉及多文件、多模块的完整项目。目前业界的代表性产品包括Anthropic的Claude Code、OpenAI的Codex CLI,以及Cursor等AI编程IDE。
超长上下文支持
1M token 的上下文窗口在国产模型中属于顶级水平。对于游戏开发这类需要大量代码和资源描述的场景,长上下文意味着模型能在一次对话中保持对整个项目的完整理解,不会因为上下文截断而丢失关键信息。
上下文窗口(Context Window)是指大语言模型在一次推理过程中能够处理的最大token数量。早期的GPT-3.5仅支持4K token,相当于约3000个汉字,处理稍长的文档就会出现信息截断。随着RoPE位置编码扩展、Ring Attention、稀疏注意力等技术的发展,上下文窗口被不断拉长。在讨论上下文窗口时,理解token的计量方式也很重要。Token是大语言模型处理文本的基本单位,但它既不等同于一个字,也不等同于一个词。对于英文,一个token大约对应4个字符或0.75个单词;对于中文,由于编码方式不同,一个汉字通常会被拆分为1.5到2个token。因此1M token对于中文内容的实际容量约为50-65万个汉字,大致相当于一部中等长度的小说。这意味着模型可以在单次对话中完整阅读和理解一个大型代码仓库的全部内容。对于游戏开发场景而言,一个完整的小游戏项目可能包含数千行代码、资源描述文件、配置文件等,长上下文确保模型不会因为"遗忘"前面的代码而产生前后矛盾的输出。不过需要注意的是,上下文窗口的"有效利用率"(即模型在长文本中准确检索和关联信息的能力)同样重要,单纯的窗口长度并不等同于实际可用性。此外,长上下文的使用还涉及成本考量——大多数API服务按token数量计费,输入和输出的token价格通常不同,长上下文虽然能力强大,但也意味着更高的单次调用成本。
理性看待:DeepSeek V4 Pro 并非不堪
补充一点,这次测试中 DeepSeek V4 Pro 生成的游戏功能完整、可以正常游玩,代码质量本身并没有问题。两者的差距主要体现在多模态素材生成上,而非纯粹的编程能力。
如果你的需求是纯代码开发、算法实现、后端逻辑等不涉及视觉素材的场景,DeepSeek V4 Pro 依然是非常强力的选择。但如果你需要的是"一站式"的全栈开发体验——从代码到设计一步到位——那 Minimax M3 的多模态融合确实提供了更完整的解决方案。
总结:多模态AI编程正在改变游戏开发方式
国产大模型的竞争已经从单一的文本能力,演进到了多模态融合、Agent 化工作流的综合较量。Minimax M3 在这次恐龙快跑游戏的对决中,凭借原生多模态和 Coding Agent 的组合拳,展现出了令人印象深刻的综合实力。对于想用 AI 快速开发小游戏、复刻网页应用的开发者来说,这类多模态编程模型正在让"5分钟做一个游戏"从噱头变成现实。
从更宏观的视角来看,AI编程工具的演进正在经历三个阶段:第一阶段是代码补全(如GitHub Copilot早期版本),AI只能在光标位置补全几行代码;第二阶段是对话式代码生成(如ChatGPT、Claude),用户通过自然语言描述需求,AI生成完整的代码段;第三阶段则是我们正在进入的Agent化多模态编程时代,AI不仅能写代码,还能理解设计稿、生成视觉素材、自主调试和迭代。Minimax M3和DeepSeek V4 Pro的这次对比,恰好展示了第二阶段向第三阶段过渡的关键节点——纯文本代码能力已经趋于成熟,多模态融合和Agent化工作流正在成为下一个竞争高地。
当前AI编程工具的竞争格局也在快速演变。在IDE集成层面,Cursor和Windsurf代表了AI原生IDE的方向,它们将大模型深度嵌入开发环境,支持跨文件编辑和项目级理解;GitHub Copilot则依托VS Code的庞大用户基础持续迭代。在命令行工具层面,Anthropic的Claude Code和OpenAI的Codex CLI开创了终端内AI编程的新范式。在模型层面,除了本文讨论的Minimax M3和DeepSeek V4 Pro,Anthropic的Claude系列在SWE-bench等代码评测中长期占据领先位置,Google的Gemini则凭借超长上下文和多模态能力在全栈开发场景中表现突出。这场竞争的终局可能不是某个单一模型的胜出,而是不同模型在不同场景中各展所长的生态格局。
相关推荐
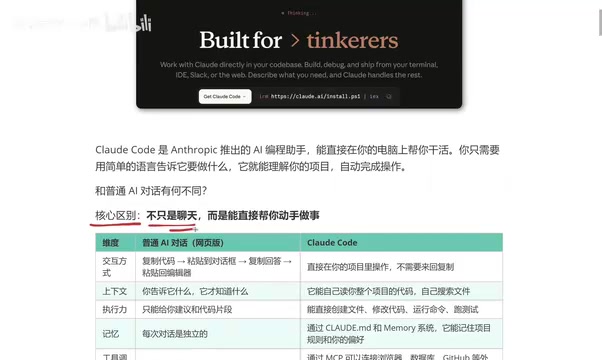
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。
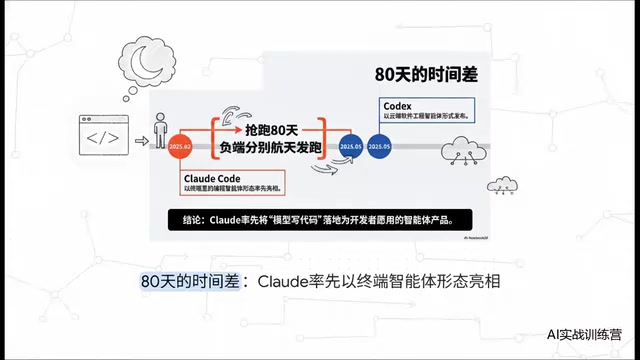
Claude Code vs Codex深度对比:技术趋同下谁更值得选
深度对比Claude Code与OpenAI Codex在先发优势、技术架构、市场份额和工程稳定性方面的差异。从18:4的创新领先到功能像素级对齐,解析AI编程工具趋同时代的终极选择标准。
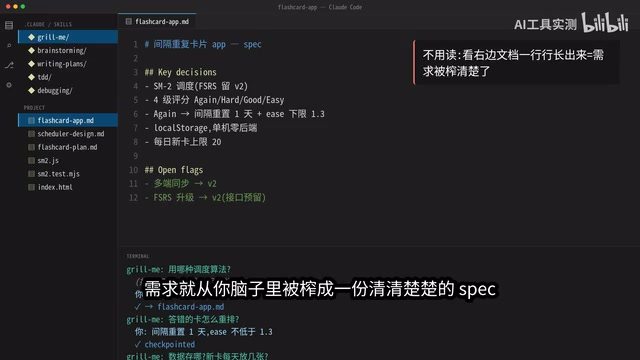
Claude Code每天必用的5个技巧:让AI反过来盘问你
分享Claude Code高效编程的5个实用技巧:Grill Me逼问需求、Brainstorming方案选型、Writing Plan执行计划、TDD测试驱动、Debugging精准修复,串成完整AI编程工作流,告别模糊需求和来回返工。