MiniMax M3上线Fireworks:512K上下文与MSA稀疏注意力解析
MiniMax M3正式上线Fireworks平台
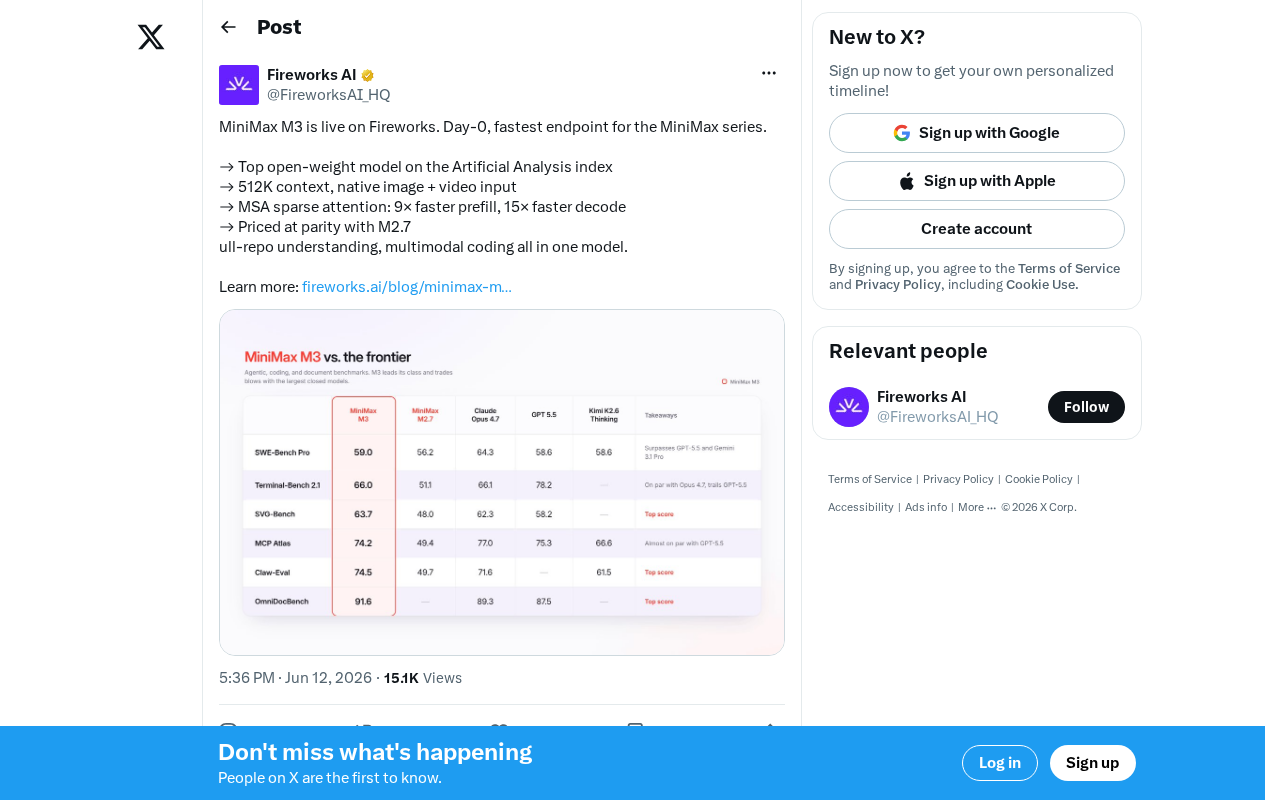
MiniMax M3模型已于发布当天(Day-0)在Fireworks平台上线,成为MiniMax系列中速度最快的推理端点。这款模型在Artificial Analysis评测指数中登顶开源权重模型榜首,标志着开源大模型竞争进入新阶段。
Fireworks AI是一家专注于大模型推理服务的云平台,由前Meta AI基础设施团队成员创立,其核心竞争力在于通过底层优化(如自研推理引擎FireAttention)为开发者提供低延迟、高吞吐的模型API服务。所谓Day-0上线,指的是模型发布当天即可通过Fireworks的API进行调用,这在推理服务商中并不常见——通常新模型需要经过适配、优化和压力测试才能上线。Day-0支持意味着Fireworks与MiniMax在模型发布前就已深度协作,完成了推理栈的适配工作,这也侧面反映了双方对M3商业化前景的高度信心。在推理即服务(Inference-as-a-Service)赛道中,Fireworks与Together AI、Groq、Anyscale等平台形成竞争关系,各家的差异化主要体现在推理引擎优化深度、支持模型的广度以及定价策略上。Fireworks的FireAttention引擎针对不同模型架构进行了深度的算子融合和显存优化,这也是其能够实现Day-0快速适配的技术基础。
Artificial Analysis是一家独立的AI模型评测与基准对比平台,其评测指数综合考量模型在多个维度的表现,包括推理质量(如MMLU、HumanEval等基准分数)、推理速度(首token延迟和吞吐量)以及性价比等。与单一基准排行榜不同,Artificial Analysis的综合指数试图回答一个更贴近实际使用的问题:在给定预算下,哪个模型能提供最好的综合体验?M3登顶该指数的开源权重模型榜首,意味着它不仅在某个单项上表现突出,而是在质量、速度和成本的综合权衡中取得了最优平衡。这一评测结果对企业级用户的模型选型决策具有重要参考价值,因为生产环境中的模型选择从来不是单纯追求某一项指标的最大化。
核心技术亮点
512K超长上下文与多模态能力
MiniMax M3支持高达512K的上下文窗口,并原生支持图像和视频输入。开发者可以在单一模型中处理超长文档理解、全代码仓库分析以及多模态编程任务,无需在多个专用模型之间切换。
上下文窗口(Context Window)是指大语言模型在单次推理中能够处理的最大token数量。512K token大约相当于70万至80万个英文单词,或约40万至50万个中文字符——这大致相当于《哈利·波特》全系列七本书的总篇幅。作为参考,GPT-4 Turbo的上下文窗口为128K,Claude 3.5 Sonnet为200K,Google Gemini 1.5 Pro虽然支持高达1M的上下文,但其推理速度和成本在超长输入下会显著恶化。512K的上下文长度意味着模型可以一次性读入一部完整的长篇小说、一个中大型软件项目的全部源代码(如Linux内核的核心模块),或数百页的法律合同。然而,超长上下文带来的核心挑战在于注意力机制的计算复杂度——标准Transformer的自注意力计算量与序列长度呈二次方关系(O(n²)),512K长度下的计算开销是128K的16倍,这正是MSA稀疏注意力机制要解决的核心问题。此外,超长上下文还面临"大海捞针"(Needle in a Haystack)问题,即模型能否在极长的输入中准确定位和利用关键信息,这对注意力机制的设计提出了更高要求。
512K的上下文长度在开源模型中属于顶级水平,足以容纳完整的大型代码库或数百页的技术文档,为长时程Agent应用提供了坚实的基础设施支撑。
MSA稀疏注意力机制:推理性能飞跃
M3最核心的技术创新在于其MSA(Mixed Sparse Attention)稀疏注意力机制。根据官方数据:
- 预填充速度提升9倍:大幅缩短首次响应延迟
- 解码速度提升15倍:显著提高token生成吞吐量
标准Transformer中的全注意力(Full Attention)机制要求每个token都与序列中的所有其他token计算注意力分数,计算复杂度为O(n²)。稀疏注意力的核心思想是:并非所有token对之间的注意力都同等重要,可以通过有选择地跳过不重要的注意力计算来降低复杂度。业界已有多种稀疏注意力方案,如Longformer的滑动窗口注意力(每个token只关注固定窗口内的邻近token)、BigBird的随机+局部+全局混合模式(引入少量全局token作为信息中继站),以及近期备受关注的Flash Attention系列(通过IO感知的算法优化加速注意力计算,但本质上仍是精确注意力)。MiniMax的MSA采用混合策略,"Mixed"一词暗示它可能在不同的注意力头(Attention Head)或不同的层中采用不同的稀疏模式——部分头使用局部注意力关注邻近token以捕捉局部语义,部分头使用全局注意力关注关键锚点token以维持长距离依赖,还可能包含基于内容的动态稀疏选择(根据token的实际语义重要性动态决定注意力分配)。这种混合设计的关键优势在于,它不是简单地丢弃信息,而是让不同的注意力头各司其职,从而在保持模型表达能力的同时大幅降低计算量。
要理解这些加速数字的含义,需要了解大语言模型推理的两个阶段。预填充(Prefill)阶段是模型一次性处理用户输入的全部prompt,计算所有输入token的注意力并生成KV Cache(键值缓存,存储每一层每个token的Key和Value向量,供后续解码阶段复用),这一阶段是计算密集型的,主要受GPU算力限制,决定了用户看到第一个输出字符的等待时间(即首token延迟/TTFT,Time To First Token)。解码(Decode)阶段则是模型逐个生成输出token,每生成一个新token都需要与之前所有token的KV Cache进行注意力计算,这一阶段是显存带宽密集型的,主要受HBM(高带宽显存)的读取速度限制,决定了输出文本的生成速度(即吞吐量/TPS,Tokens Per Second)。在512K超长上下文场景下,预填充阶段需要处理的token数量巨大,KV Cache的显存占用也会膨胀到数十GB甚至上百GB,这两个阶段的性能瓶颈都会被急剧放大。因此MSA在两个阶段分别实现9倍和15倍加速具有极高的实际价值——9倍的预填充加速意味着用户提交一个512K长度的prompt后,等待首个响应的时间从可能的数十秒缩短到几秒;15倍的解码加速则意味着长文本生成任务的完成时间大幅压缩。
这种稀疏注意力设计在保持模型质量的同时,极大降低了推理成本和延迟。对于需要处理超长上下文的应用场景,这一优化尤为关键——传统的全注意力机制在512K长度下的计算开销几乎不可接受,而MSA让大规模长文本推理变得实际可用。从成本角度看,推理加速直接转化为GPU利用率的提升和单位推理成本的下降,这也是M3能够在性能大幅提升的同时维持与M2.7相同定价的技术基础。
定价策略与市场定位
MiniMax M3的定价与前代M2.7保持一致,这是一个极具竞争力的策略。在性能大幅提升的同时维持价格不变,实质上为开发者提供了一次免费的能力升级。这种定价策略在云计算行业有着深厚的传统——AWS、Azure等云服务商长期奉行"性能提升、价格不变"的迭代节奏,以此锁定开发者生态。对于已经在使用M2.7的开发者来说,迁移到M3几乎是零成本决策,这有助于MiniMax快速扩大用户基数。
从应用场景来看,M3瞄准了三个高价值方向:
- 长时程Agent:512K上下文让Agent能够维持更长的任务记忆和推理链
- 全仓库代码理解:一次性加载整个代码仓库进行分析和修改
- 多模态编程:结合图像与视频输入进行UI还原、视觉调试等任务
AI Agent(智能体)是当前大模型应用的核心方向之一,指的是能够自主规划、执行多步骤任务的AI系统。与简单的问答式交互不同,Agent需要具备目标分解、工具调用、环境感知和自我纠错等能力,典型的框架包括LangChain的ReAct模式、AutoGPT以及近期备受关注的Manus等。长时程Agent面临的关键挑战是"记忆"问题——随着任务步骤增多,Agent需要记住之前的操作结果、中间推理过程和环境状态。传统的短上下文模型迫使开发者采用外部记忆机制(如向量数据库检索增强生成/RAG),这不仅增加了系统复杂度,还可能因信息检索不完整而导致Agent"遗忘"关键信息,或因检索到不相关内容而产生幻觉。512K上下文窗口配合极快的推理速度,使得Agent可以将完整的任务历史保持在上下文中,实现更连贯的长链推理。例如,一个软件开发Agent在执行跨越数十个文件的重构任务时,可以将所有相关代码、修改历史和测试结果同时保持在上下文中,而不必依赖外部检索来"回忆"之前的操作。这对软件开发Agent、数据分析Agent和研究助手等复杂应用场景尤为重要。
全仓库代码理解同样是一个高价值场景。传统的代码AI工具(如GitHub Copilot)主要基于当前文件和少量上下文进行补全,对跨文件依赖关系的理解有限。512K上下文使得M3可以一次性加载一个中型项目(通常在10万至30万行代码)的核心模块,理解模块间的调用关系、数据流和架构模式,从而提供更准确的代码修改建议和Bug定位。
开源模型竞争格局分析
MiniMax M3登顶Artificial Analysis开源模型指数,这一成绩值得关注。当前开源大模型赛道竞争激烈,Llama、Qwen、DeepSeek等系列持续迭代,MiniMax能够脱颖而出说明其在模型架构和训练策略上确有独到之处。
当前开源大模型赛道已形成多强并立的格局。Meta的Llama系列凭借先发优势和庞大的社区生态占据重要地位,Llama 3.1 405B曾是最大的开源模型之一,其开放的许可协议催生了大量下游微调模型和应用;阿里的Qwen系列在中英双语能力上表现突出,Qwen2.5已覆盖从0.5B到72B的完整参数规模,形成了从端侧到云端的全场景覆盖;DeepSeek则以其MoE(Mixture of Experts,混合专家)架构和极具竞争力的性价比引发行业关注——MoE架构通过在每次推理时只激活部分参数(专家网络),在保持大模型容量的同时显著降低计算成本,DeepSeek-V3在多项基准上逼近闭源模型水平。此外,Mistral AI的Mixtral系列在欧洲市场具有重要影响力,01.AI的Yi系列也在持续迭代。MiniMax此前以M2.7模型崭露头角,M3的发布标志着其从追赶者向领先者的角色转变。值得注意的是,"开源权重"(Open Weight)与"完全开源"(Open Source)存在重要区别——前者通常只公开模型权重供下载和推理使用,但训练数据、训练代码、数据处理流程等可能不完全公开,这意味着社区可以使用和微调模型,但难以完全复现训练过程。目前大多数所谓的"开源模型"实际上属于开源权重模型。
稀疏注意力并非新概念,但MSA能够在实际部署中实现9至15倍的加速,同时不牺牲模型在基准测试上的表现,这体现了工程实现层面的深厚功力。从学术研究到工程落地之间存在巨大的鸿沟——许多论文中提出的稀疏注意力方案在理论上能降低计算复杂度,但在实际GPU硬件上由于不规则的内存访问模式和低效的算子实现,往往无法兑现理论加速比。MSA能够在Fireworks的推理引擎上实现接近理论值的加速,说明MiniMax在算子优化和硬件适配方面投入了大量工程资源。Fireworks选择Day-0支持M3,也表明了推理服务商对其商业前景的认可。
对开发者的实际意义
对于正在构建AI应用的开发者来说,M3的组合优势——超长上下文、多模态输入、极快推理速度、开源权重——提供了一个极具吸引力的选择。特别是在Agent和代码智能领域,512K上下文配合15倍解码加速,意味着复杂任务的端到端完成时间可以大幅缩短。
开源权重的意义不仅在于免费使用,更在于部署灵活性和数据隐私保障。企业可以将M3部署在自有基础设施上(私有云或本地服务器),确保敏感数据不离开企业边界,这对金融、医疗、法律等对数据合规要求严格的行业尤为重要。同时,开源权重允许开发者针对特定领域进行微调(Fine-tuning),例如在专有代码库上训练以提升代码理解能力,或在行业特定文档上训练以增强领域知识。结合LoRA(Low-Rank Adaptation)等参数高效微调技术,开发者可以在消费级GPU上以较低成本完成模型定制。
值得持续关注的是M3在实际生产环境中的表现能否兑现基准测试的承诺——基准测试与真实场景之间往往存在差距,特别是在超长上下文的边缘情况(如信息在上下文末端的检索准确率)和多模态理解的鲁棒性方面。此外,社区围绕其开源权重会产生怎样的微调和应用生态也值得期待,一个活跃的社区生态往往能够放大模型本身的价值,正如Llama系列催生了数千个下游微调模型一样。
核心要点
核心要点
相关推荐
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。
Claude Code vs Codex深度对比:技术趋同下谁更值得选
深度对比Claude Code与OpenAI Codex在先发优势、技术架构、市场份额和工程稳定性方面的差异。从18:4的创新领先到功能像素级对齐,解析AI编程工具趋同时代的终极选择标准。
Claude Code每天必用的5个技巧:让AI反过来盘问你
分享Claude Code高效编程的5个实用技巧:Grill Me逼问需求、Brainstorming方案选型、Writing Plan执行计划、TDD测试驱动、Debugging精准修复,串成完整AI编程工作流,告别模糊需求和来回返工。