Mythos/Fable模型极限压榨指南:10天烧完8000美元推理额度
引言:一个让开发者失眠的模型
Anthropic最新发布的Fable模型(即带安全护栏的Mythos)正在让开发者们疯狂。YouTube知名科技博主Theo分享了他过去10天的极限使用体验——仅在一台笔记本上就烧掉了4350美元的推理费用,加上Mac Mini的1112美元,总计超过5400美元的推理量,而他实际只支付了200美元的订阅费。
在大语言模型的计费体系中,Token是最基本的计量单位——一个Token大约对应英文中的3/4个单词,中文中约1-2个字。推理(Inference)指模型接收输入并生成输出的过程,与模型训练不同,推理是每次使用时都会发生的实时计算。以Claude为例,API定价通常按输入Token和输出Token分别计费,高端模型的输出Token价格可达每百万Token数十美元。Theo消耗的数百万Token如果按API价格计算就是5400美元,但订阅制将这些成本打包为固定月费,形成了巨大的价格差——这正是"补贴"的含义所在。
这不是一个关于"如何节省Token"的教程,恰恰相反——这是一个关于如何在Fable被移除订阅计划之前(6月22日截止),最大化利用这些极度补贴的推理额度的实战指南。
理解限额机制:双重限制与破解策略
五小时会话限制的运作原理
Claude Code的Pro和Max订阅有两层限制:五小时会话限制和每周总量限制。关键发现是——计时器从你发送第一条消息时才开始倒计时。
这意味着一个简单的优化策略:在你准备开始工作之前,先去claude.ai发一条"hi"然后立即停止,让计时器提前启动。这样当你4.5小时后真正开始高强度工作时,限额会在30分钟内重置,而不是你用完后还要等4小时。
Theo甚至设置了一个Cron任务,每5小时自动触发一次Claude Code消息,确保计时器永远在倒计时状态。Cron是Unix/Linux系统中的定时任务调度器,允许用户按照预设的时间表自动执行命令或脚本。在macOS上,虽然Apple推荐使用launchd作为替代方案,但传统Cron语法仍然广泛使用。Theo利用这一机制自动发送消息来操控计时器,本质上是一种对限额系统的"时间套利"——让冷却期与实际工作时间完美错开,确保每次坐下来工作时都有充足的额度可用。
每周限制的数学逻辑
从实测来看,每次达到五小时限额的100%,大约消耗每周限额的25%。换言之,一周内你可以把五小时窗口打满4次就会耗尽周限额。
双账户轮换策略
Theo同时维护两个200美元的Claude Code账户,通过简单的/login命令在终端中切换。更巧妙的是——切换账户不会中断正在运行的工作流。下一次工具调用会自动路由到新账户,这意味着你可以在一个账户即将触顶时无缝切换到另一个。
工作流设计:让每一个Token都产生真正价值
PR审查与多Agent评判系统
Theo展示了一个实际案例:他的Lakebed项目有三个实现相同功能的PR(#35、#37、#39),分别由Codex和Claude Code独立构建。他让Mythos创建了一个完整的审查工作流,包含:
- 13个独立审计Agent
- 7个评判Agent
- 多个收割和综合Agent
多Agent系统(Multi-Agent System)是人工智能领域的经典架构模式,源自分布式AI研究。在LLM时代,它指的是多个AI实例各自承担不同角色,通过协调机制协同完成复杂任务。这种架构的核心优势在于:单个Agent的上下文窗口有限(即使是最先进的模型也只有100K-200K Token的有效处理能力),但通过分工可以处理远超单次对话容量的信息量;不同Agent可以采用不同的提示策略和评估标准,模拟人类团队中的角色分工;多个独立评判通过"投票"或加权综合机制,能显著提高结论的可靠性,类似于集成学习(Ensemble Learning)的思想。
整个工作流在30分钟内烧掉了180万Token,消耗了21%的新鲜使用窗口。这种"Agent审查Agent工作"的模式,虽然Token消耗惊人,但产出了人类难以在短时间内完成的全面分析。
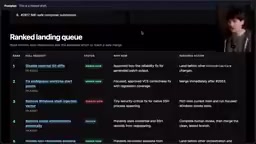
每日PR排序自动化
对于维护多个开源项目的开发者来说,一个更实用的应用是:每天早上让Mythos遍历所有仓库的PR,生成一个排序队列,按"合并难度"和"值得关注程度"排列。
Theo的T3 Code项目有400+个Issue和300+个PR,传统方式根本无法有效管理。Agent生成的排序报告让一个被忽视一个月的简单bug修复PR在5分钟内被合并。
HTML计划文件的妙用
Theo构建了一个简单服务来托管HTML格式的计划文件,让Agent可以输出可读的URL。这种方式的优势在于:
- 比Markdown更易读
- 可以在手机浏览器上随时查看
- 可以直接粘贴链接给另一个Agent继续工作
- 实现了"Codex写代码 → Mythos审查 → Codex根据审查修改"的完整闭环
远程工作流:用Mac Mini解放你的笔记本
Mac Mini作为永不关机的Agent主机
一个关键的工作流改进是将长时间运行的Agent任务转移到Mac Mini上。通过三种方式访问:
- SSH直连(同网络)或通过Tailscale(远程)
- macOS内置屏幕共享(支持Tailscale穿透)
- T3 Code远程系统(从另一台电脑或手机控制)
Tailscale是基于WireGuard协议构建的零信任网络(Zero Trust Network)工具,它为每台设备创建一个虚拟专用网络,无需传统VPN服务器。其核心优势是NAT穿透能力——即使设备位于不同的家庭路由器或企业防火墙后面,也能直接建立点对点加密连接,延迟通常只有几毫秒。与传统VPN需要暴露公网端口不同,Tailscale通过协调服务器交换密钥但不中转数据,大幅降低了安全风险。对于需要远程控制家中开发机的场景,这几乎是零配置的最优解。
这彻底改变了使用模式——从"跑短任务以便随时合上笔记本"变成了"让Agent进行长时间探索性工作"。你不再需要期望每次都能直接使用结果,而是期望获得有趣的发现来指导后续工作。
Fable/Mythos的编排能力与子Agent优化
编排是Fable的核心超能力
Fable在编排多Agent工作流方面表现出色,但有一个重要注意事项:Fable倾向于让子Agent也使用Fable模型,这会导致不必要的Token消耗。
编排(Orchestration)在AI系统中指的是顶层控制器负责任务分解、Agent分配、结果汇总和冲突解决的过程。一个好的编排层需要理解任务的全局结构,判断哪些子任务需要高智能模型、哪些只需要快速执行模型。这类似于软件工程中的微服务架构——不是每个服务都需要最强的硬件,合理的资源分配才能实现最优的性价比。
明确告诉Fable在编排时使用Opus或Sonnet作为子Agent模型,可以在不牺牲质量的情况下显著降低消耗。Fable的价值在于顶层的规划和协调,具体执行工作交给更经济的模型即可。
自动化Agent循环的进阶玩法
更高级的用法包括:
- 一个Agent创建PR,另一个Agent监控并自动审查
- Agent使用浏览器录屏证明修改有效
- Codex每5分钟唤醒一次,自动分配工作到不同线程
- 结合Sentry或Datadog数据,让Agent自主发现和修复问题
Sentry是一个实时错误追踪平台,能自动捕获应用程序中的异常、堆栈跟踪和上下文信息;Datadog则是全栈可观测性平台,涵盖基础设施监控、APM(应用性能管理)和日志管理。当这些工具与AI Agent结合时,形成了一个自主修复闭环:监控系统检测到生产环境的新错误→通过Webhook通知Agent→Agent分析堆栈跟踪和相关代码→生成修复PR→另一个Agent审查并合并。这种模式将平均修复时间(MTTR)从小时级压缩到分钟级,代表了AIOps(智能运维)的前沿实践方向。
心态转变:从恐惧驱动到兴奋驱动
正如Sawyer所建议的:"你需要比以前更有野心。让模型从头重写你的整个生产应用,让它部署、添加账户系统、多人协作功能——所有你在个人项目中通常不会做的事情。"
Theo强调了一个重要的心态区别:
- 错误心态:出于对失业的恐惧而疯狂使用AI → 结果是焦虑和低质量产出
- 正确心态:带着构建的兴奋感去探索极限 → 结果是自定义工具、fork的软件、更高效的工作流
关键原则是:降低"什么值得构建"的门槛,提高"构建到什么程度"的标准。当你发现自己在问"Agent能做这个吗"时,直接让它试,然后从失败中学习。这种心态转变的底层逻辑是:当边际成本趋近于零时(订阅制下每次额外使用不产生新费用),传统的成本-收益分析不再适用。你应该像拥有无限实验预算的研究员一样思考——每次失败的尝试都是免费的学习机会,而每次成功都是纯粹的收益。
总结:200美元撬动8000美元的窗口期
在Fable从订阅计划中移除之前的最后几天,这是一个难得的窗口期来体验未来AI辅助开发的样子——当推理成本不再是瓶颈时,开发者的生产力边界在哪里。虽然每月花费8000美元的推理费用不现实,但花200美元获得等值体验,绝对值得一试。
这种定价策略的不可持续性也值得深思:Anthropic目前的补贴模式本质上是用风险投资资金换取用户增长和使用数据,类似于早期Uber对乘客和司机的双向补贴。当补贴窗口关闭后,开发者需要重新评估哪些工作流在真实API价格下仍然具有正ROI——而现在正是在零风险环境下探索这些边界的最佳时机。
核心要点
相关推荐
Claude Code入门指南:核心优势、工具对比与安装部署详解
深入解析Claude Code的核心优势:全项目上下文理解、极高代码准确度与插件化集成方式。横向对比Cursor、Copilot、Trae等主流AI编程工具,并提供安装部署要点与实用建议。

Codex一句话生成微信小程序:从需求到上线全流程实战
详解如何用OpenAI Codex通过纯对话方式从零构建微信小程序,涵盖需求文档生成、设计规范定义、代码自动生成与Bug调试四步完整工作流,附实战经验与避坑指南。
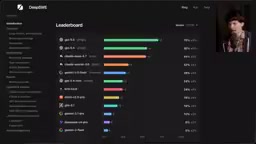
DeepSWE基准测试深度解析:揭露SWE-Bench缺陷与真实编程能力排名
深度解析DeepSWE编程基准测试如何揭露SWE-Bench Pro的数据污染和作弊问题。GPT-5.5以70%通过率领先,开源模型差距明显。涵盖测试结果、成本对比与开发者实用建议。