Node.js实现AI Agent:用Function Call替代提示词工程
用Function Call替代提示词约定,构建更标准准确的AI Agent
本文介绍如何使用Function Call机制替代提示词约定格式来构建AI Agent。通过JSON Schema定义工具(如bash、readfile),大模型能准确调用工具并传参,有效解决幻觉问题。文章通过抓包分析成熟Agent、实战改造Node.js代码、测试验证工具调用链等环节,展示了Function Call的标准化优势和扩展性。
前言:从提示词到Function Call的进化
在上一篇文章中,我们用Node.js实现了一个基础的AI Agent,通过系统提示词约定返回格式(command:开头执行命令,text:开头返回结果),配合循环调用大模型接口来完成任务。但这种方式存在一个致命问题——大模型幻觉。当我们仅靠提示词约束输出格式时,模型可能返回不符合预期的内容,导致Agent执行异常。
大模型幻觉(Hallucination)是指语言模型生成看似合理但实际不正确或不存在的内容。在Agent场景中,幻觉的表现形式包括:模型不遵循约定的输出格式、生成不存在的命令名称、编造文件路径或代码行号等。幻觉的根本原因在于大模型本质上是基于概率的文本生成器,它通过预测下一个token来生成内容,而非真正"理解"指令约束。当我们仅通过自然语言提示词来约束输出格式时,模型可能在某些上下文中"忘记"这些约束,尤其是在长对话或复杂推理场景下。Function Call通过将工具定义从自然语言层面提升到API结构化层面,从根本上解决了这一问题。
本文将介绍如何使用官方的Function Call功能来替代这种"土法炼钢"的方式,让AI Agent更加标准化、准确和可扩展。
为什么要使用Function Call
提示词方案的局限性
之前的实现方式是在系统提示词中告诉大模型:"你的回答有两种格式,一种是command:xxx表示要执行的命令,一种是text:xxx表示最终结果。"这种方式有几个问题:
- 幻觉风险:模型可能不按约定格式返回,导致解析失败
- 扩展性差:添加新工具需要修改提示词,容易造成混乱
- 不够标准:每个开发者的约定方式不同,缺乏统一规范
Function Call的三大优势
通过抓包分析成熟的AI Agent(如Claude Code、Aider等),可以发现它们都使用了Function Call机制:
- 更加标准:通过JSON Schema定义工具,大模型能百分百准确调用
- 更加准确:消除了格式解析的不确定性,减少幻觉
- 易于扩展:可以轻松添加多个工具(bash、read、write、search等)
JSON Schema是一种用于描述JSON数据结构的声明式语言,它定义了数据的类型、必填字段、字段描述、枚举值等约束条件。在Function Call机制中,JSON Schema扮演着"接口契约"的角色:开发者通过Schema精确描述每个工具接受什么参数、参数是什么类型、哪些是必填的。大模型在训练阶段已经学习了如何根据JSON Schema生成符合约束的参数,因此它能以接近100%的准确率生成合法的工具调用请求。这与传统的提示词方案形成鲜明对比——后者依赖模型对自然语言指令的"理解",而前者依赖模型对结构化规范的"遵循"。
抓包分析:成熟Agent如何使用Function Call
通过中间人代理工具抓包,可以清晰看到成熟Agent的请求结构。中间人代理(Man-in-the-Middle Proxy)是一种网络调试技术,通过在客户端和服务器之间插入代理服务器来截获、查看和修改HTTP/HTTPS流量。常用的工具包括mitmproxy、Charles Proxy和Wireshark等。在分析AI Agent时,开发者可以将Agent的API请求代理到本地抓包工具,从而看到发送给大模型的完整请求体(包括messages、tools定义、temperature等参数)以及模型返回的完整响应。这种逆向分析方法对于学习成熟产品的实现方式非常有效,能够揭示它们的工具设计思路、提示词工程策略和对话管理机制。
以一个拥有33k Star的开源Agent项目为例,它定义了以下工具:
bash:执行Shell命令read:读取文件内容write:写入文件delete:删除文件find:搜索文件list:列出目录
请求体中的tools参数以JSON Schema格式定义了每个工具的名称、描述和参数结构。大模型返回时会明确指定要调用哪个工具以及传入什么参数,完全消除了格式歧义。
实战:改造Node.js Agent支持Function Call
定义工具Schema
首先定义一个tools数组,每个工具包含名称、描述、参数定义和执行方法:
const tools = [
{
type: "function",
function: {
name: "bash",
description: "执行bash命令",
parameters: {
type: "object",
properties: {
command: { type: "string", description: "要执行的命令" }
},
required: ["command"]
}
},
execute: (args) => execSync(args.command).toString()
},
{
type: "function",
function: {
name: "readfile",
description: "读取文件内容,类似cat -n(带行号)",
parameters: {
type: "object",
properties: {
path: { type: "string", description: "文件路径" }
},
required: ["path"]
}
},
execute: (args) => {
const content = fs.readFileSync(args.path, 'utf-8');
return content.split('\
').map((line, i) => `${i + 1} | ${line}`).join('\
');
}
}
];
这里的设计将工具的Schema定义(传给API的部分)和执行逻辑(本地运行的部分)放在同一个对象中,使得工具的注册和管理更加内聚。type: "function"告诉API这是一个函数类型的工具,function字段包含符合JSON Schema规范的参数描述,而execute字段则是我们自定义的本地执行方法。
修改API请求逻辑
将tools参数传入API请求,并修改响应处理逻辑:
const response = await openai.chat.completions.create({
model: "your-model",
messages: messages,
tools: tools // 新增tools参数
});
当模型返回tool_calls时,解析工具名称和参数,执行对应方法,将结果以tool角色推入对话历史,然后继续请求模型直到获得最终文本回复。
OpenAI兼容的Chat Completions API定义了多种消息角色:system(系统指令)、user(用户输入)、assistant(模型回复)和tool(工具执行结果)。当模型返回tool_calls时,开发者需要执行对应工具,然后将执行结果以tool角色、附带tool_call_id推入对话历史。这种设计让模型能够区分"自己说的话"和"工具返回的真实数据",从而基于真实的执行结果进行下一步推理。整个循环过程为:用户提问→模型决定调用工具→开发者执行工具→结果回传→模型继续推理→可能再次调用工具→...→最终返回文本回复。这个循环被称为Agent Loop,是所有AI Agent的核心运行机制。
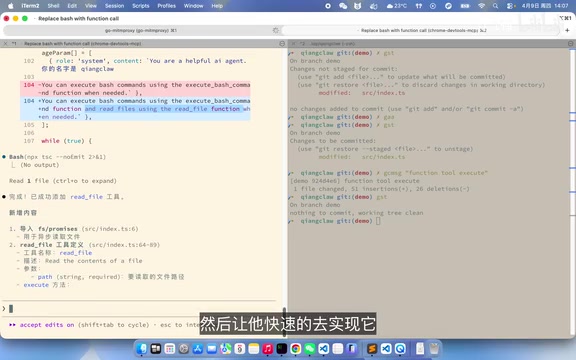
关键细节:文件读取加行号
一个值得注意的细节是,Claude Code在读取文件时会为每一行添加行号(类似cat -n命令)。这不是多余的设计——经过实测,添加行号后模型能更准确地定位代码位置,减少行号幻觉。这仅需一行代码实现:
content.split('\
').map((line, i) => `${i + 1} | ${line}`).join('\
');
为什么行号对模型如此重要?大模型在处理代码时,如果需要指出"第42行有bug"或"在第15行后插入代码",它必须准确计算行号。但模型本身并不擅长计数——它是逐token处理文本的,没有内置的行计数器。通过在输入中显式标注行号,我们将"计数"这个对模型来说困难的任务转化为"读取"这个简单的任务,从而大幅提升了代码定位的准确性。
测试验证:观察完整的工具调用链
当我们向Agent提问"这个项目做什么"时,可以观察到完整的工具调用链:
- 调用
bash执行ls列出当前目录 - 调用
readfile读取package.json了解项目依赖 - 调用
readfile读取README.md获取项目说明 - 调用
bash列出src目录结构 - 调用
readfile读取核心代码文件 - 最终返回项目分析结果
整个过程中,模型自主决定调用哪个工具、传入什么参数,完全不需要我们在提示词中做复杂的格式约定。这种自主决策能力来源于大模型在训练阶段学习到的"规划"能力——它能够将一个高层目标(理解项目)分解为多个子步骤,并根据每一步的执行结果动态调整后续计划。这正是AI Agent区别于简单聊天机器人的核心特征:具备感知-规划-行动的闭环能力。
与AI协作开发的两种模式
在实现过程中,有一个值得分享的开发理念:
精细控制模式:每次告诉AI一个小的改动点,理解每一步变化。适合学习和需要把控代码质量的场景。
结果导向模式:直接告诉AI"帮我实现一个完整的Agent",只关注最终结果。效率更高但可能导致后期看不懂代码。
推荐前者——既能快速开发,又能理解代码含义,在后续维护时不会陷入困境。这种模式也被称为"AI辅助的增量开发",它的核心思想是:让AI成为你的结对编程伙伴而非代码生成器。你保持对架构和逻辑的理解,AI帮你加速实现细节。当代码出现问题时,你有足够的上下文来定位和修复,而不是面对一堆"黑盒代码"束手无策。
后续展望:从两个工具到完整Agent
目前实现了bash和readfile两个工具,后续可以继续扩展:
write:写入文件grep/search:代码搜索website:网页抓取- Skill Loading:动态加载技能
- 上下文压缩:解决长对话token超限问题
- MCP集成:每个MCP方法都可以作为tool加入
MCP(Model Context Protocol)是Anthropic提出的一种开放协议,旨在标准化大模型与外部工具、数据源之间的通信方式。MCP采用客户端-服务器架构,MCP Server暴露一组工具(tools)、资源(resources)和提示模板(prompts),MCP Client(通常是AI应用)通过标准协议与之通信。每个MCP Server提供的方法都可以被映射为Function Call中的一个tool,这意味着开发者可以通过接入MCP生态来快速扩展Agent的能力,而无需为每个工具单独编写集成代码。目前已有大量社区贡献的MCP Server,覆盖数据库查询、文件系统操作、Web搜索、API调用等场景。
成熟的Agent如Claude Code可能有20个以上的工具定义,这正是Function Call机制的强大之处——标准化的接口让工具扩展变得简单而可靠。
核心要点
- Function Call通过JSON Schema定义工具,比提示词约定格式更标准、更准确,能有效减少大模型幻觉
- 实现一个AI Agent的核心是定义tools数组(含Schema和执行方法),将其传入API请求,并循环处理tool_calls直到获得最终回复
- 文件读取时添加行号是一个关键细节,能帮助模型更准确地定位代码位置
- 成熟Agent(如Claude Code)通常定义20+个工具,Function Call机制让工具扩展变得简单可靠
- 与AI协作开发推荐精细控制模式:每次描述小改动点,既保证开发效率又能理解代码含义
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。