NVIDIA开源AI-Q:让编程Agent具备深度研究能力的技能包

NVIDIA开源AI-Q技能包,让编程Agent具备深度研究能力
NVIDIA开源的AI-Q技能包通过四阶段深度研究流水线(意图分流、分层研究、混合模型路由、闭环验证),解决现有Agent编排工具在开发效率、分析深度和安全合规方面的痛点。它支持Claude Code等主流工具快速接入,采用MCP协议实现数据连接,提供三种认证模式保障安全,支持本地部署确保数据主权,Benchmark准确率达94%。
当你的 Agent 遇到复杂的深度研究任务时,是不是总感觉像个"只扫了眼标题的实习生"?NVIDIA 最近开源的 AI-Q 技能包,正试图从根本上解决这个问题——让 Claude Code、Codex 等编程 Agent 具备真正的深度研究能力。
现有 Agent 编排工具的三大痛点
做过 Agent 编排的开发者一定深有体会:Demo 跑得飞起,一碰深度任务就抓瞎。Agent 编排(Agent Orchestration)是指协调多个AI代理协同完成复杂任务的技术体系。 LangChain、AutoGen 等框架虽然降低了 Agent 开发门槛,但在处理需要多轮推理、跨文档综合分析的深度研究任务时,普遍面临"广度有余、深度不足"的困境。这本质上源于大语言模型的上下文窗口限制与单次推理深度之间的矛盾——模型擅长模式匹配,却难以自主规划长链条的逻辑推演。无论是 LangChain、Claude Code 还是其他主流工具,简单对话确实顺手,但要让它跑几个小时的复杂逻辑研究,分分钟就掉链子。
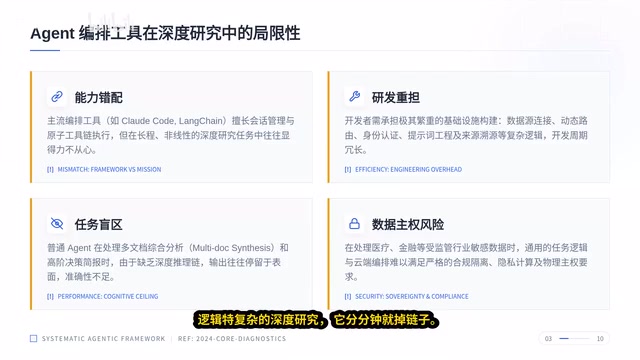
具体来说,当前工具存在三个核心问题:
第一,开发效率低下。 开发者的大量时间花在调数据连接、动态路由和没完没了的 Prompt 调优上,开发周期被无限拉长,真正的业务逻辑反而没时间写。
第二,分析深度不足。 你丢给 Agent 十份文档让它分析,它给你的反馈毫无深度,本质上还是在做信息搬运,而非逻辑推演。现有工具大多在机械执行,像个只会按指令干活的搬砖工。
第三,安全合规无法满足。 尤其在金融、医疗等行业,合规和数据主权是硬性红线。通用的云端工具根本搞不定这道坎,导致 Agent 永远只能在核心业务门口转悠。
AI-Q 的四阶段深度研究流水线
NVIDIA 推出的 AI-Q(AIQ)本质上是一个"现成的研究员插件"。你把任务丢给它,它自己去理解需求、搜索资料,最后直接输出一份带引用的报告。不用再死磕复杂逻辑和写不完的 Prompt,直接往系统里一插就行。
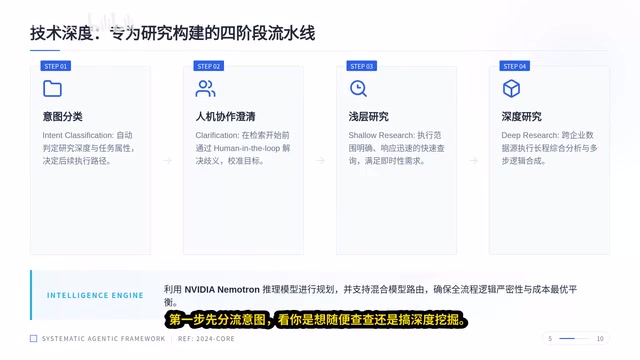
这套流水线分为四个阶段:
阶段一:意图分流
系统首先判断你的查询类型——是随便查查,还是需要深度挖掘。如果碰到指令模糊的情况,Agent 会主动找你确认,避免自作聪明、南辕北辙。这一步看似简单,却是后续所有流程高效运转的前提。
阶段二:分层研究
简单查询走浅层研究路径,响应极快;复杂任务则交给深度研究模块,它会翻阅各种企业数据源,进行长周期的逻辑合成。这种分层设计既保证了效率,又不牺牲深度。
阶段三:混合模型路由
底层使用 NVIDIA 的推理模型做全局规划,配合一套**混合模型路由(Hybrid Model Routing)**机制。这是企业级 AI 系统中降低推理成本的关键技术——根据任务复杂度动态分配不同规模的模型:简单的信息检索任务交给小参数量模型处理,复杂的逻辑推理才调用大模型。这一策略在实践中可将 Token 消耗降低 40%-70%,同时保持整体输出质量。NVIDIA 的 NIM(NVIDIA Inference Microservices)微服务架构为这种动态路由提供了底层支撑,允许在本地 GPU 和云端算力之间无缝切换。对企业级 AI 应用来说,这一设计至关重要。
阶段四:闭环验证输出
所有结论必须 100% 可验证。报告里的每一句话,点击即可跳回原文件出处,AI 绝对不能"瞎编"。从数据抓取到最终验证,每一步都有审计记录,合规检查完全没压力。
快速接入:Claude Code、Codex 等工具的对接方式
想把 AI-Q 跑起来,首先确保 Python 版本在 3.10 以上。不同开发工具的接入方式各有特点:
- Claude Code:直接建个软链接,秒级识别
- Codex:把技能包直接拷进目录即可
- Open Code:走标准配置路径,搞多 Agent 协作很方便
敲一行命令,系统会自动识别环境,后台自动扫描文档并处理复杂逻辑,开发者可以直接专注于业务逻辑。
数据安全方案:MCP 协议与三种认证模式
AI-Q 接入数据靠的是内置的 MCP(Model Context Protocol)协议。MCP 是由 Anthropic 于 2024 年底提出并推动的开放标准协议,旨在解决 AI 模型与外部数据源、工具之间的标准化连接问题。在 MCP 出现之前,每个 AI 应用都需要为不同数据源单独开发适配层,维护成本极高。MCP 通过统一的协议规范,让 AI 模型能够以一致的方式访问文件系统、数据库、API 等各类资源,被业界视为 AI 应用集成领域的"USB 接口"。NVIDIA 在 AI-Q 中内置 MCP 支持,意味着开发者可以复用整个 MCP 生态中已有的数千个连接器。

开发时提供三种认证模式:
无认证模式: 适合跑公开文档或沙箱代码,即插即用,零配置成本。
服务账号模式: 适合跨部门自动化场景,系统级对接,不需要人工干预。
身份透传模式: 这是最核心的模式——AI 实时识别你的权限,你看不了的机密合同,AI 也读不到,权限完全同步。
底层跑的是 Nemo 工具包,能自动把服务器资源转成 AI 插件。不管数据在哪,AI-Q 都能安全地将其变成随手可调用的知识库。
数据主权:程序找数据,而非数据迁就程序
做企业级 AI 最卡脖子的往往不是算法,而是合规。AI-Q 的设计哲学很清晰:把 Agent 直接空投到你的数据环境里。
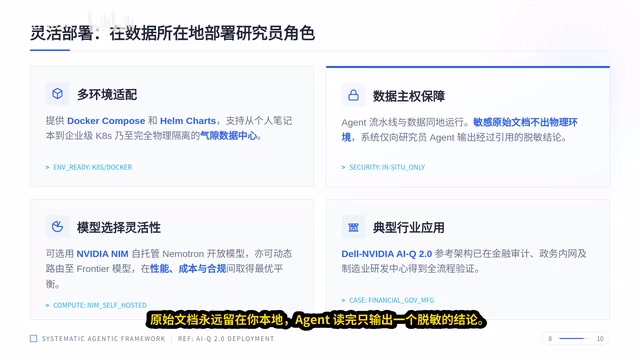
不管你是用笔记本开发,还是在 K8s 集群甚至完全断网的机房,这套工具都能像装个普通软件一样部署。核心逻辑是让程序主动去找数据,而不是搬动数据去迁就程序。原始文档永远留在本地,Agent 只输出一个脱敏的结论。
模型选型也很灵活:想保密就跑本地的 NVIDIA NIM(Inference Microservices)——这是 NVIDIA 推出的推理微服务平台,将优化后的 AI 模型封装为标准化的容器镜像,支持在企业本地 GPU 基础设施上一键部署。对于金融、政务等数据敏感行业,NIM 的意义在于彻底消除数据离境风险——模型权重和推理计算全部在本地完成,外部网络仅传输最终的脱敏结论,与传统云端 API 调用模式形成根本性区别。想冲性能就动态切到云端。据介绍,这套方案已经在金融和政务内网跑通,"数据出不去"的问题终于有了解法。
效果验证:Benchmark 准确率达 94%
在 Benchmark 测试中,AI-Q 处理复杂逻辑的准确率达到了 94%,比通用方案明显更稳。理解这一数字需要结合 AI 研究 Agent 的评估体系:业界常用的深度研究评估维度包括事实准确性(Factual Accuracy)、引用溯源率(Citation Coverage)、逻辑一致性(Logical Coherence)以及幻觉率(Hallucination Rate)。AI-Q 强调"100% 可验证
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。