O3 vs Gemini 2.5 Pro vs Claude 3.7:AI编程能力实测对比
O3、Gemini 2.5 Pro和Claude 3.7编程能力对比测试,各有所长无绝对赢家
通过贪吃蛇、强化学习管道、太阳系模拟器和足球游戏四项递进难度任务,对比测试了O3、Gemini 2.5 Pro、Claude 3.7等顶级AI模型的编程能力。结果显示三大模型各有优势:O3代码稳定可靠,Claude 3.7在强化学习任务中一次性完美实现,Gemini 2.5 Pro在复杂系统设计上表现惊艳,而Mini系列模型在复杂任务中差距明显。
测试背景与方法
随着OpenAI O3、Gemini 2.5 Pro和Claude 3.7等顶级AI模型相继发布,一个核心问题浮出水面:谁才是最强的编程AI? 本次测试通过多个递进难度的Python游戏开发任务,对这些模型进行了全面对比评估。
测试涵盖的模型包括:O3、O4 Mini、O3 Mini、Gemini 2.5 Pro以及Claude 3.7。所有模型接收相同的提示词,在相同条件下进行比较。测试任务从简单的自主游戏开发,逐步升级到强化学习训练管道、太阳系模拟器,最终到复杂的足球游戏系统。
模型架构背景:当前顶级AI编程模型的技术路线差异显著。OpenAI的O系列模型(O3、O4 Mini)采用了「思维链推理」(Chain-of-Thought Reasoning)机制,在生成代码前会进行内部多步推理,这使其在逻辑严密性上具有天然优势。Gemini 2.5 Pro基于Google DeepMind的多模态架构,拥有高达100万token的超长上下文窗口,能够在单次对话中处理极为复杂的代码结构。Claude 3.7来自Anthropic,其训练过程强调「宪法AI」原则,在代码安全性和一次性任务完成率上表现突出。三家公司代表了当前AI领域最前沿的技术路线,其模型能力的差异折射出不同的训练哲学与架构选择。
第一轮:自主贪吃蛇对战游戏
任务要求
第一个任务看似简单实则不易:在一个Python脚本中创建完全自主的贪吃蛇游戏,让两条蛇相互竞争,并实现完整的计分系统——每秒存活加1分,吃苹果加10分,吃掉对方蛇加50分。
各模型表现
Claude 3.7 率先登场,两条蛇运行完美,得分系统正确,图形效果出色。唯一的小瑕疵是蓝色文字稍难辨认,但最终因类型错误而崩溃。
Gemini 2.5 Pro 表现堪称卓越——完美响应指令,显示每轮成绩和累计成绩,还在结尾附带了简要总结。整体稳定性极佳。
O4 Mini 设计风格不错,但蛇之间碰撞处理存在问题,算法未考虑蛇与蛇之间的碰撞检测。
O3 则展现了全尺寸模型的优势——它将蛇之间的碰撞逻辑写入了代码,蛇之间几乎不会发生意外碰撞,且全程无崩溃。测试者评价:"O3和Gemini 2.5 Pro大致相同的评分,这二者可能表现最好。"
第二轮:强化学习训练管道
难度升级
第二轮测试大幅提升了复杂度:要求模型创建一个支持多种运行模式的脚本——普通游戏模式、使用PyTorch的强化学习训练模式、以及使用训练好的模型进行对战的评估模式。还需要添加每秒增加两个的障碍物系统。
强化学习与PyTorch技术解析:强化学习(Reinforcement Learning, RL)是机器学习的核心范式之一,其核心思想是让智能体(Agent)通过与环境的交互,依据奖励信号不断优化决策策略。在贪吃蛇场景中,AI蛇作为智能体,游戏状态(蛇的位置、食物位置、障碍物)作为观测空间,移动方向作为动作空间,得分变化作为奖励信号。PyTorch是Facebook开发的深度学习框架,以动态计算图和Pythonic API著称,是学术界和工业界最主流的RL实现工具。完整的RL训练管道通常包含:环境封装(Gym接口)、神经网络策略网络(Policy Network)、经验回放缓冲区(Replay Buffer)、以及DQN或PPO等优化算法。能够一次性正确实现这整套系统,要求模型对RL工程实践有深度理解,而非仅停留在概念层面。
关键结果
O4 Mini和O3 Mini 均未能成功运行脚本,出现了默认值未定义等基础错误。
O3 同样遇到了问题,在多次尝试后仍无法正常工作。
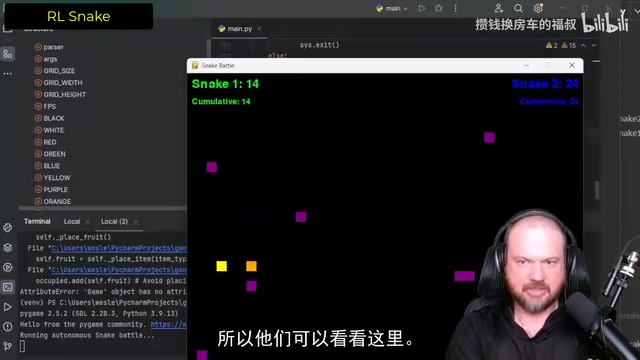
Claude 3.7 则一次性完美解决了所有问题。它成功实现了:
- 四种不同的运行模式(普通游戏、训练、蛇1用AI、蛇2用AI)
- 障碍物系统正常工作
- 强化学习训练管道完整运行
- 训练500个episode后,AI蛇的表现远超脚本蛇
实测数据令人印象深刻:经过训练的AI蛇得分超过3000点,而普通脚本蛇仅370点。切换角色后,AI蛇依然以压倒性优势获胜(80:30),证明神经网络训练确实有效。
这一轮Claude 3.7是明确的赢家,一次尝试就完美实现了所有功能。
第三轮:太阳系模拟器
任务描述
创建一个太阳系模拟器,允许玩家从银河系外发射探测器,利用行星引力实现弹射效应,击中两个固定靶标。
引力弹射的物理原理:引力弹射(Gravitational Slingshot),又称「引力助推」或「行星借力飞行」,是真实航天任务中广泛使用的轨道力学技术。其物理本质是探测器在飞越行星时,借助行星的引力场和公转动量,在不消耗燃料的情况下改变速度和方向——NASA的旅行者号探测器正是利用这一原理完成了太阳系外层行星的探索之旅。在代码实现层面,模拟引力弹射需要正确实现万有引力公式(F=GMm/r²),并使用数值积分方法(如Runge-Kutta四阶法或简化的欧拉积分)逐帧更新探测器的速度和位置向量。这对AI模型的物理建模能力提出了较高要求——不仅需要理解公式,还需要正确处理坐标系变换、时间步长选择等工程细节。
各模型对比
O3 表现不错,成功实现了基本的引力弹射机制,探测器能够受到行星引力影响改变轨迹。虽然不完美,但核心玩法可行。
Gemini 2.5 Pro 创建了一个视觉上很大的模拟器,但交互逻辑存在问题——点击发射功能无法正常工作,需要多次调试。
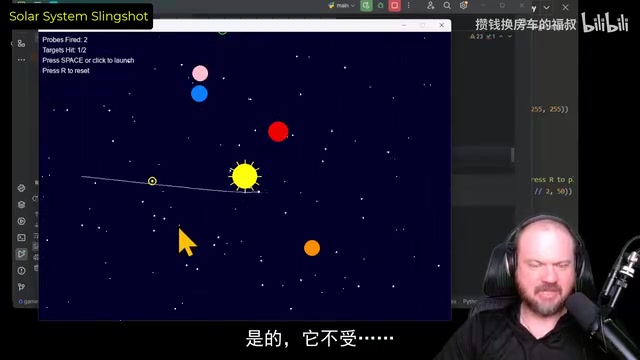
Claude 3.7 图形效果不错,但探测器不受任何引力场影响,核心物理模拟机制缺失。这一问题揭示了一个值得关注的现象:即便是顶级模型,在需要精确数值积分和物理公式协同工作的场景下,也可能出现「代码能跑但物理逻辑错误」的情况。
O3 Mini 出现多次崩溃。
这一轮O3表现最为出色,虽然不完美但正确实现了最多的核心功能。
第四轮:自主足球游戏系统
终极挑战
最后一个任务是创建一个三对三的自主足球游戏,包含:玩家统计数据、经验值系统、等级提升、抢断机制、雪球效应、进球动画(屏幕振动)、计分板等复杂系统。
最终评判
O3 实现了基本功能,包括等级系统和经验值,但玩家聚集在一起导致难以分辨,且红蓝两队的初始位置不公平。
Gemini 2.5 Pro 获得了额外加星评价——成功实现了力量、速度、准确性等属性系统,玩家等级提升后属性增强,游戏速度会随时间加快。测试者评价:"绝对值得一个加星,太棒了。"
Claude 3.7 在运行一段时间后因球距离相关的bug崩溃,但崩溃前运行流畅。
综合评价与最终结论
| 模型 | 贪吃蛇 | 强化学习 | 太阳系 | 足球 | 综合 |
|---|---|---|---|---|---|
| O3 | ★★★★★ | ★★☆ | ★★★★ | ★★★ | 优秀 |
| Gemini 2.5 Pro | ★★★★★ | ★★★ | ★★★ | ★★★★★+ | 优秀 |
| Claude 3.7 | ★★★★ | ★★★★★ | ★★★ | ★★★★ | 优秀 |
| O4 Mini | ★★★★ | ★☆ | - | - | 一般 |
| O3 Mini | ★★★★ | ★☆ | ★☆ | - | 一般 |
核心发现
-
没有绝对的赢家:每个模型在不同任务上各有优劣。O3在代码稳定性和碰撞逻辑上表现出色,Gemini在复杂系统设计上令人惊艳,Claude在一次性完成复杂任务上无与伦比。
-
Claude 3.7在强化学习任务上一骑绝尘,一次尝试就完美实现了包含PyTorch训练管道的完整系统,这对需要机器学习集成的开发者尤为重要。
-
Gemini 2.5 Pro在游戏机制设计上难以超越,尤其在需要复杂属性系统和动态平衡的任务中表现突出。
-
Mini模型差距明显:O4 Mini和O3 Mini在复杂任务上频繁失败,证明模型规模在编程任务中仍然至关重要。这一现象与AI领域的「规模定律」(Scaling Laws)高度吻合——该理论由OpenAI于2020年首次系统性提出,表明模型参数量的增加能够以可预测的方式提升性能,尤其在需要长程依赖推理、多模块协调和错误自检的复杂编程任务中,精简架构所能承载的推理上限往往不足以应对工程级挑战。
选择建议
- 需要稳定可靠的代码输出:选择O3
- 涉及机器学习和训练管道:选择Claude 3.7
- 复杂游戏系统和交互设计:选择Gemini 2.5 Pro
- 简单脚本和快速原型:Mini模型可以胜任
这场AI编程对决没有绝对的胜者,但每个模型都展示了各自的独特优势。开发者应根据具体项目需求,选择最适合的AI编程助手。
核心要点
- O3和Gemini 2.5 Pro在基础贪吃蛇游戏中表现最佳,稳定性和功能完整度领先
- Claude 3.7在强化学习训练管道任务中一次性完美实现所有功能,表现最为突出
- Gemini 2.5 Pro在复杂足球游戏系统设计中获得额外加星,系统设计能力出众
- Mini系列模型(O4 Mini、O3 Mini)在复杂任务中频繁失败,与全尺寸模型差距明显,印证了规模定律在工程编程场景中的有效性
- 三大顶级模型各有所长,没有绝对赢家,开发者应根据具体任务选择合适工具
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。