Obsidian + Claude Code:AI自动维护个人知识库实战指南
用Claude Code自动管理Obsidian知识库,解决笔记整理难题
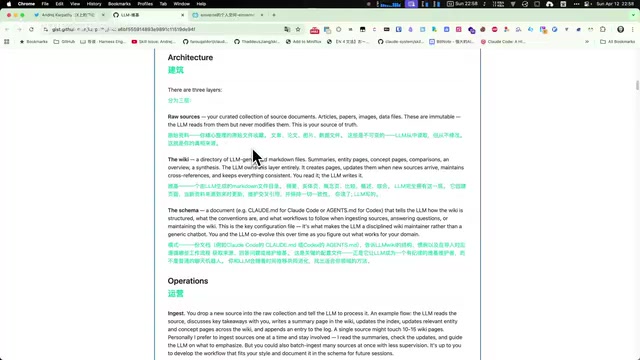
文章介绍了一套用Claude Code(Coding Agent)驱动Obsidian知识库管理的方法。核心设计采用三层架构:RAW文件夹存放原始素材(只读)、Wiki文件夹由AI自动生成和维护带交叉引用的知识网络、Schema文件定义系统规范。日常操作简化为三种工作流:Ingest(导入新素材并自动提炼)、Query(查询知识库)、Maintain(定期健康检查)。这套方法将人力从繁重的笔记整理中解放出来。
知识库管理的老问题
用 Obsidian 做笔记的人,大概都经历过这样的困境:摘录了大量笔记,但它们孤零零地躺在笔记库里,和其他内容没有任何连接;添加新笔记时,本应顺手关联已有内容,但这项工作繁复到让人几次尝试后就放弃;写文章时想引用笔记中的概念,却发现根本找不到。
Obsidian 是一款基于本地 Markdown 文件的知识管理工具,其核心理念来自「卡片盒笔记法」(Zettelkasten)——由德国社会学家尼克拉斯·卢曼发展的一套笔记方法论,强调通过双向链接将原子化的知识点编织成网络。Obsidian 的文件本质是纯文本 Markdown,存储在用户本地,这一特性使其天然适合被 AI 工具直接读写操作。然而,Zettelkasten 方法的精髓——持续维护节点之间的关联——恰恰是最耗费人力的部分。
这些问题的根源是一样的——维护知识库需要大量复杂、重复的整理工作,人是做不下去的。而这恰恰是大语言模型擅长处理的事情。
最近,Andrew Capazzi 发表了一篇文章介绍他如何使用 Obsidian 配合 Claude Code 等 Coding Agent 来管理知识库。这套工作流与许多 Obsidian 重度用户自行摸索出的方向高度吻合。本文将结合 Capazzi 的思路和实际使用经验,介绍这套 AI 驱动的知识库管理方法。
为什么选择 Claude Code 而非其他 AI 工具
此前有人尝试过用 Gemini CLI 在 Obsidian 中打造"第二大脑",Gemini CLI 的优势在于有较大的免费额度。但实际使用一段时间后,体验差强人意。切换到 Claude Code 后,差距非常明显——Claude Code 在上下文理解、工具调用、文本生成方面都比 Gemini CLI 强不少。
Claude Code 是 Anthropic 推出的命令行 AI 编程助手,属于「Coding Agent」范畴。与普通聊天式 AI 不同,Coding Agent 具备工具调用(Tool Use)能力,可以自主执行文件读写、终端命令、代码运行等操作,形成「感知-规划-执行」的 Agent 循环。这种架构使其能够在无人干预的情况下完成多步骤复杂任务,而不仅仅是生成文本回复。正因如此,Claude Code 作为一个 Coding Agent,天然具备读写本地文件的能力,这使得它可以直接操作 Obsidian 的 Markdown 文件,无需额外的插件或 API 对接。
三层架构:知识库的核心设计
Capazzi 的笔记库采用了清晰的三层架构,每一层各司其职。这套架构的设计思路是:原始素材与加工内容分离,系统规范独立管理,让 AI 在明确的边界内自主运作。
第一层:RAW 文件夹(原始素材)
RAW 文件夹遵循"只进不出"的原则。所有的研究论文、GitHub 仓库、网页文章、截图等原始素材都放入这个文件夹。大语言模型可以读取其中的内容,但绝不修改——原始资料永远保持原始状态。
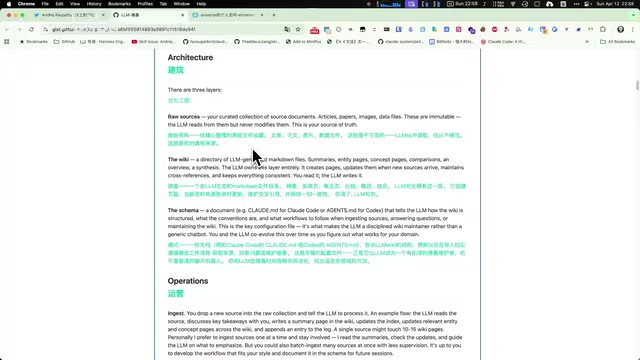
第二层:Wiki 文件夹(AI 生成与维护)
这是整个系统的核心,由大语言模型负责创建、更新和维护。其中包括摘要、概念解释、人物介绍、专题文章等,所有内容都带有交叉引用,将知识串联成网络。
交叉引用(Cross-reference)是知识管理中将孤立信息转化为结构化知识网络的核心机制。在图论视角下,每篇笔记是一个节点,交叉引用是边,最终形成知识图谱。研究表明,人类记忆的提取效率与记忆节点的连接密度正相关——这正是 Zettelkasten 方法的理论基础。AI 自动维护交叉引用,本质上是在模拟人类大脑建立联想的过程,但以机器的速度和一致性执行。
这一层有两个关键文件:
- index.md:整体索引文件,列出 Wiki 中所有文件及其摘要。大语言模型每次问答时先读取这个文件,找到相关条目,再深入读取对应文章。这一设计思路与检索增强生成(RAG,Retrieval-Augmented Generation)技术高度相似——RAG 的核心问题是在上下文窗口有限的情况下,如何让模型找到最相关的知识片段。传统 RAG 依赖向量数据库做语义检索,而 index.md 用结构化的 Markdown 索引替代了向量检索,在文件数量不过千的个人知识库场景下,这种轻量方案反而更稳定、可解释性更强。
- log.md:操作日志文件,记录每次修改、查询和维护操作。这个日志本身就记录了知识库的增长轨迹,方便追溯 AI 对笔记库的所有改动。
第三层:Schema 文件(系统规范)
类似于 claude.md 这样的配置文件,定义了整个系统的运行规范:如何处理新素材、文章用什么格式、摘要写多长、遇到矛盾怎么处理。这是人工投入最集中的地方——通过修改这个文件来调整 AI 的行为,而不是手动整理 Wiki 内容。
三种日常工作流:Ingest、Query、Maintain
在这套架构下,日常操作被简化为三种工作流:
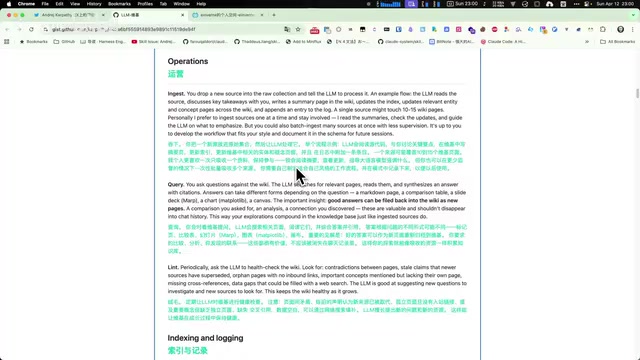
工作流一:Ingest(获取新内容)
将新资料放入 RAW 文件夹,触发一次处理流程。大语言模型会自动读取内容、提取核心摘要、创建或更新 Wiki 页面。通常一次新内容的添加会产生 10-15 个页面的交叉引用更新,最后在 log.md 中记录本次操作。
实际操作中,可以将处理指令保存为 Claude Code 的 slash command,每次只需执行斜杠命令并指定要分析的文章,即可自动完成内容添加。slash command 本质上是预存的提示词模板,允许用户将复杂的多步骤指令封装为单一命令——类似于 Shell 脚本或 Makefile,将重复性操作标准化。将 Ingest、Query、Maintain 三类操作各自封装为 slash command,实现了「一键触发、自动执行」的工作流,大幅降低了使用门槛和认知负担。
工作流二:Query(查询知识库)
想了解某个话题时,不用去 RAW 文件夹搜索原始文档,而是直接在 Wiki 中查找。因为 AI 已经将所有原始资料提炼成了带有交叉引用的知识结构,搜索结果比直接检索原文有用得多。如果某个回答特别有价值,还可以直接写回 Wiki,变成新的知识条目。
例如,在笔记库中查询"AI Agent 的记忆系统",Claude Code 不仅能找到直接相关的内容(如 Hermes Agent 的记忆系统、Memo Base 开源项目、Memo9 等),还能通过关联检索找到 OpenCloud 相关的插件和工具。更重要的是,它还能指出笔记中尚未深入覆盖的领域,比如记忆系统的分类框架、Context Engineering 的定义、记忆评测方法等。
工作流三:Maintain(定期维护)
定期让大语言模型对整个 Wiki 目录做一次"健康检查":找出矛盾的说法、过时的信息、没有被任何页面链接的孤立条目,以及明显的知识空白。同样可以将维护指令保存为 slash command,定期执行即可。
这个流程彻底替代了人工梳理笔记的苦差事,让知识库保持持续更新,而不是慢慢被遗忘。
实用工具与效率提升技巧
在实际使用中,有几个工具可以显著提升素材收集和知识库管理的效率:
- Obsidian Web Clipper:Chrome 插件,可以一键将网页转换为 Markdown 格式并保存到 Obsidian 中。点击插件按钮后,网页会自动转换为可预览的 Markdown 文件,再点击"添加到 Obsidian
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。