Obsidian+Claude Code三层记忆系统:彻底解决AI跨会话失忆
用Obsidian搭建三层记忆系统,解决AI跨会话失忆问题
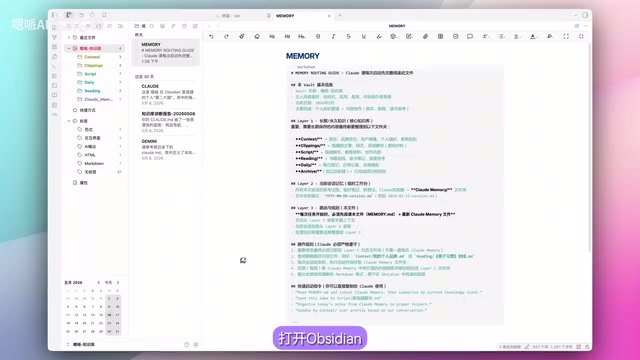
文章介绍了一套基于Obsidian和Claude Code的三层记忆系统,解决AI每次对话都从零开始的痛点。三层架构模拟人脑记忆机制:长期记忆层存放结构化知识底座,会话记忆层实时记录对话思路实现思考不中断,大脑目录层(Memory.md)作为导航文件告诉AI身份、数据位置和使用方式。该方案纯本地运行、零API成本。
AI工具最让人头疼的问题
AI工具最让人头疼的问题是什么?不是不够聪明,而是每次对话都从零开始。昨天和它深入讨论过的话题,今天打开新会话,它就像完全换了一个人。这个痛点困扰着每一个深度使用AI的人。
最近,一位创作者分享了他用Obsidian结合Claude Code搭建的「三层记忆系统」,把本地知识库变成AI的外置神经元,实现了跨会话的记忆延续。这套方案纯本地运行、零API成本,思路非常值得借鉴。
为什么AI需要「外置记忆」来解决失忆问题?
当前主流大语言模型的工作机制决定了它们天生「健忘」——每次会话都是独立的上下文窗口,会话结束即清空。即便是Claude、GPT这样的顶级模型,也没办法真正记住你上周的项目进展、你的写作风格偏好,或者你半个月前整理的读书笔记。
这种「健忘」的根源在于LLM的架构设计本身。每次对话本质上是一次独立的前向推理过程,模型只能处理当前输入的「上下文窗口」(Context Window)内的信息。即便是拥有200K token超长上下文窗口的Claude 3.5,也只能在单次会话中保持连贯性——一旦会话结束,所有中间状态都不会被持久化存储。这与人类大脑的记忆机制有根本区别:人脑通过海马体将短期记忆转化为长期记忆,而LLM的「记忆」仅存在于推理过程中,本质上是无状态的计算。目前业界的解决方案主要有三类:一是扩大上下文窗口(治标不治本);二是RAG(检索增强生成)技术,在推理时动态注入外部知识;三是本文介绍的外置记忆系统,本质上是一种轻量级的RAG实践。
这带来一个很现实的问题:你每次都要花大量时间重新交代背景、重复说明需求。AI始终是一个「每次都要重新教的新人」,而不是一个越用越懂你的合伙人。
这套三层记忆系统的核心思路是:不改变AI本身,而是在外部构建一套结构化的记忆体系,让AI每次启动时都能快速「回忆」起你是谁、你在做什么、上次聊到哪里。
Obsidian三层记忆架构详解
整套系统模拟人类大脑的记忆回路,将Obsidian知识库划分为三个功能明确的逻辑分区。
在深入架构之前,有必要理解为什么选择Obsidian作为载体。Obsidian是一款基于本地Markdown文件的双向链接笔记软件,其核心设计哲学是「你的数据永远属于你」。与Notion、Roam Research等云端工具不同,Obsidian将所有笔记存储为纯文本.md文件,这一特性使其天然适合作为AI的外置知识库——Claude Code可以直接读写文件系统,无需任何API中间层。Obsidian的Vault(仓库)本质上是一个普通文件夹,这种结构化的本地文件系统与LLM的文件读取能力完美契合,使得「AI读取知识库」这一操作可以零成本实现。

第一层:长期记忆层——AI的知识底座
对应人脑的大脑皮层,存放所有稳定、结构化、长期有价值的信息。物理上就是Obsidian里你已经整理好的笔记文件夹,但在这套系统中角色完全不同——它是Claude Code的知识底座。
以作者的仓库为例,长期记忆层包含五个核心文件夹:
- Context:个人身份、品牌定位、用户画像、核心偏好规则
- Clippings:从网络收藏的文章、网页等原始素材
- Script:所有视频脚本和教程资料
- Daily:日常记录和每日灵感捕捉
- Reading:读书笔记和深度思考
Claude Code所有输出的认知水平,都取决于这一层的质量。
第二层:会话记忆层——让AI的思考不中断
对应人脑的前额叶工作记忆,专门解决「AI一关就忘」的问题。这是一个名为Claude Memory的专用文件夹,Claude Code会在其中实时记录当前对话的思路、临时灵感、推理过程和决策路径。
它的核心作用只有一个:让思考不中断。
更关键的是,这些内容不会浪费。会话结束后,你可以把有价值的内容提炼、升级、迁移到第一层,形成知识的持续积累。这种「短期→长期」的迁移机制,正是模拟人脑海马体将工作记忆固化为长期记忆的过程。
第三层:大脑目录层——Memory.md导航文件
这是整个系统最隐形但最关键的一层——一个名为Memory.md的文件。它的作用是告诉Claude Code你是谁、你的数据在哪、你该怎么用。
从技术本质看,Memory.md是一种精心设计的「系统提示词」(System Prompt)工程实践。在LLM的交互架构中,系统提示词是在用户输入之前注入的指令层,用于定义模型的角色、行为规范和上下文背景。Memory.md通过结构化的模块设计,将原本需要用户每次手动重复的背景信息固化为可复用的提示词模板——它不仅告诉AI「你是谁」,还告诉AI「你的知识在哪里」,承担了知识路由的核心功能。
每次Claude Code启动,都会先读这个文件,然后瞬间完成三件事:
- 确认身份:你是谁、你在做什么
- 找到长期知识:第一层的记忆在哪里
- 接上上次的思路:第二层在哪里
如果说前两层是记忆本身,那这一层就是导航系统加操作系统。
Memory.md模板的六大核心模块
Memory.md作为整个系统的灵魂文件,编写质量直接决定了三层记忆系统的运行效果。作者将其分为六个核心部分:
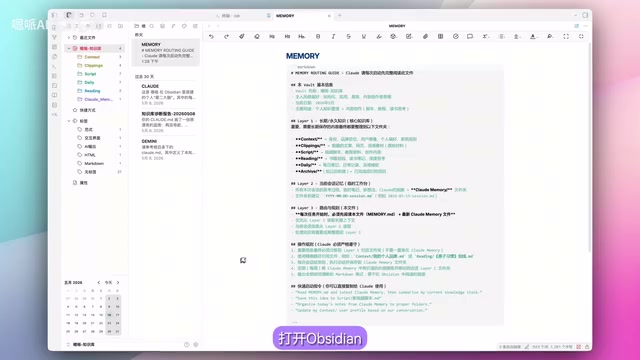
第一部分:文件头部基本信息——包括Vault名称、主人、风格偏好、当前日期,相当于给Claude Code做一次快速自我介绍。
第二部分:长期知识层说明——给Claude Code画一张详细的知识库地图,明确每个文件夹的定位,大幅减少AI的「猜测」行为。
第三部分:会话记忆层说明——明确临时内容的存放规则和迁移机制。
第四部分:路由与核心规则——这是灵魂部分,定义了Claude Code的工作流程、三层记忆的使用优先级和输出要求。
第五部分:操作规则与最佳实践——包括使用精确路径、重要内容必须迁移到长期记忆层、输出格式要求等。
第六部分:快速指令模板——常用快捷指令示例,方便日常使用中快速调用。
实操接入Claude Code的完整步骤与五大应用案例
理解Claude Code的能力边界,有助于更好地设计这套系统。Claude Code是Anthropic推出的命令行AI编程助手,其核心能力远超普通对话AI——它具备完整的「Agent」特性,能够自主执行文件读写、代码运行、目录遍历等操作。从技术
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。