Ollama本地部署大模型:三步完成安装到对话

Ollama是开源本地大模型管理平台,三步即可部署AI模型。
Ollama是一个开源免费的本地大语言模型管理平台,基于llama.cpp构建,支持离线运行且保护数据隐私。用户只需下载安装Ollama、选择模型、执行ollama run命令即可完成部署,支持通义千问、Llama等主流开源模型。通过4位量化技术大幅降低硬件门槛,还可搭配Open WebUI等前端获得图形化交互体验。
什么是Ollama?
Ollama是一个开源的大语言模型管理平台,它让普通用户也能在自己的电脑上轻松部署和运行各种AI大模型。用一个通俗的比喻来理解:我们平时看书可以通过浏览器在线阅读,但也可以用电子书管理软件把书下载到本地离线阅读。Ollama的作用就类似于后者——它是一个大语言模型的本地管理工具,让我们无需每次都通过网络来使用AI。
大语言模型(LLM)是什么?
大语言模型(Large Language Model, LLM)是基于深度学习中的Transformer架构构建的人工智能模型,通过在海量文本数据上进行预训练,学会了语言的统计规律和语义理解能力。从2022年底ChatGPT引爆全球关注以来,大模型技术经历了从云端专属到本地可用的快速演进。早期的大模型(如GPT-3)拥有1750亿参数,只能在大型数据中心运行;而如今通过模型压缩、量化等技术,数十亿参数级别的模型已经可以在消费级硬件上流畅运行,这正是Ollama等本地部署工具得以存在的技术基础。
Ollama的技术架构与生态定位
Ollama底层基于llama.cpp项目构建,后者是由Georgi Gerganov开发的C/C++推理引擎,专门针对CPU和Apple Silicon进行了深度优化。Ollama在此基础上封装了模型管理、版本控制、API服务等功能,提供了类似Docker管理容器镜像的体验——用户可以像拉取Docker镜像一样拉取AI模型。Ollama启动后会在本地11434端口开启REST API服务,这意味着任何支持HTTP请求的应用程序都可以调用本地模型,为开发者构建AI应用提供了极大便利。在整个开源LLM生态中,Ollama与vLLM、LocalAI、LM Studio等工具形成互补,但以其极简的使用体验脱颖而出。
Ollama有三个显著的优势:
- 完全开源免费:对预算有限的个人开发者和小型组织非常友好
- 支持离线运行:在没有网络的环境中也能正常工作
- 数据隐私安全:所有数据都在本地处理,不会上传到云端,无需担心隐私泄露
下载与安装Ollama
获取安装程序
安装Ollama的过程非常简单,只需要以下步骤:
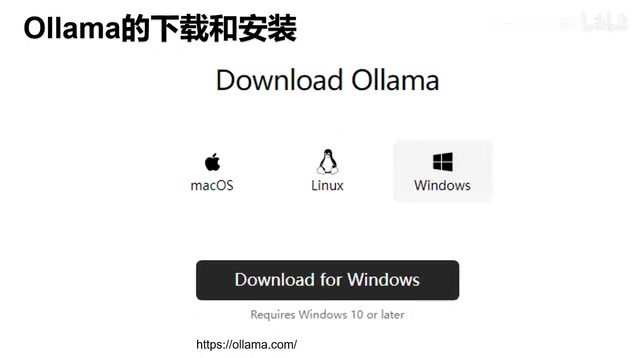
- 进入Ollama官方主页(ollama.com),页面设计非常简洁,最醒目的就是下载按钮
- 点击下载按钮后,根据自己的操作系统选择对应版本(Windows/macOS/Linux)
- 下载完成后,双击安装程序启动安装
安装注意事项
与其他Windows软件不同,Ollama的安装程序非常精简——没有安装目录选择、没有各种参数配置,唯一需要做的就是点击"Install"按钮。由于软件体积较大,安装过程需要耐心等待几分钟。
验证安装是否成功
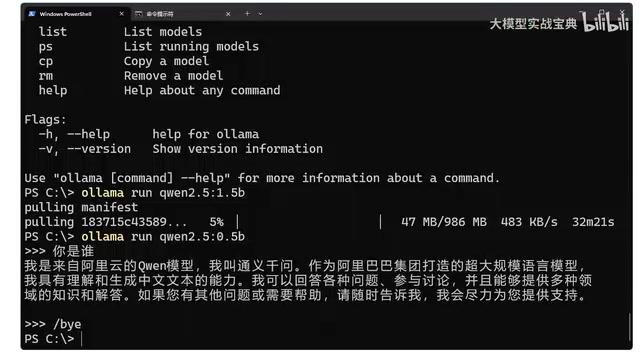
安装完成后,打开命令提示符(CMD),输入ollama命令。如果安装成功,系统会显示Ollama的相关信息和可用命令列表,包括:
ollama list:查看已部署的大模型ollama ps:查看正在运行中的大模型ollama run:部署或运行一个大模型
部署第一个大模型
选择合适的模型
进入Ollama官网,点击"Models"菜单,可以看到平台支持的所有大模型列表。目前支持的模型包括Meta(Facebook)的Llama系列、Google的Gemma、阿里的通义千问等众多主流开源模型。
主流开源模型一览
当前Ollama支持的开源模型各有特色:Meta的Llama系列(最新为Llama 3.1)是开源社区最具影响力的基座模型,在英文任务上表现优异;Google的Gemma系列轻量高效,适合资源受限场景;阿里的通义千问(Qwen2.5)在中文理解和生成方面表现突出,对中文用户尤为友好;Mistral AI的模型以小参数量实现了超越预期的性能。此外还有专注代码生成的DeepSeek Coder、CodeLlama等。这些模型采用不同的开源许可证,部分允许商用(如Llama 3.1、Qwen2.5),用户在选择时需注意许可条款。
以阿里的通义千问2.5(Qwen2.5)为例,点击进入后可以看到多个版本可供选择:0.5B、1.5B、3B、4B等。这里的"B"代表模型参数量(十亿),参数越多模型能力越强,但同时对硬件资源的要求也越高。
理解模型参数量与量化技术
模型参数量中的"B"是Billion(十亿)的缩写,代表模型中可训练权重的数量。参数越多,模型能够捕捉的语言模式和知识就越丰富,但相应地需要更多的内存(RAM/VRAM)来加载。例如,一个7B模型在FP16精度下需要约14GB显存。为了让大模型能在普通硬件上运行,业界广泛采用量化(Quantization)技术——将模型权重从32位或16位浮点数压缩为8位、4位甚至更低精度的整数表示。Ollama默认使用4位量化(Q4),这使得7B模型仅需约4-5GB内存即可运行,大幅降低了硬件门槛,虽然会有轻微的精度损失,但对日常使用影响甚微。
选择建议:如果只是学习和体验,建议从参数较小的版本(如0.5B或1.5B)开始,对硬件要求较低,下载也更快。
一键部署模型
选定模型版本后,页面右侧会显示对应的部署命令,例如:
ollama run qwen2.5:0.5b
将这条命令复制到命令提示符中执行即可。首次运行时,Ollama会先下载模型文件(0.5B版本约400多MB),下载完成后会显示成功提示,并自动进入对话模式。
开始与大模型对话
进入对话模式后,就可以直接与大模型进行交互了。比如输入"你是谁",模型会回复自我介绍。这与我们平时在网上使用ChatGPT等产品的体验基本一致,只不过所有计算都在本地完成。
进阶:为Ollama添加可视化界面
命令行的交互方式虽然功能完整,但对大多数用户来说并不友好。实际使用中,我们更希望有一个美观、易操作的图形化界面。目前社区有多个开源的Ollama前端项目可供选择,如Open WebUI等,可以为Ollama提供类似ChatGPT的网页交互体验。
Open WebUI与可视化前端生态
Open WebUI(原名Ollama WebUI)是目前最成熟的Ollama图形化前端,它提供了与ChatGPT几乎一致的网页交互界面,支持多轮对话、对话历史管理、模型切换、文件上传、RAG(检索增强生成)等高级功能。安装通常通过Docker一键部署,命令为:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
除Open WebUI外,社区还有Chatbox(桌面客户端)、LobeChat(支持插件扩展)、Jan(注重隐私)等多种选择,用户可根据自身需求挑选合适的前端工具。
总结
从零开始使用Ollama部署本地大模型,核心只需三步:
- 下载安装Ollama客户端
- 在官网选择合适的模型
- 执行
ollama run命令完成部署
整个过程对新手非常友好,无需任何编程基础。对于想要在本地体验AI大模型、保护数据隐私、或者进行离线开发的用户来说,Ollama是目前最简单易用的解决方案之一。
核心要点
- Ollama是开源免费的本地大模型管理平台,支持离线运行且保护数据隐私
- 安装过程极简,只需下载安装包并点击Install即可完成
- 通过ollama run命令即可一键下载并部署模型,支持通义千问、Llama等主流开源模型
- 模型参数量(B)越大能力越强但资源消耗越高,初学者建议从小参数版本开始
- Ollama底层基于llama.cpp,默认采用4位量化技术大幅降低硬件门槛
- 可搭配Open WebUI等可视化前端获得更友好的交互体验
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。