Ollama本地部署大模型完全指南:断网也能用的AI
使用Ollama工具本地部署开源大模型的完整指南
文章介绍了本地部署大模型的必要性(成本、稳定性、隐私),重点推荐Ollama作为最稳定的本地大模型管理工具。Ollama基于llama.cpp构建,采用模型管理与UI分离架构,支持Llama 3、通义千问等主流开源模型。部署只需三步:安装Ollama、下载运行模型、配置跨域访问。通过量化技术,7B模型仅需约6GB显存即可运行,适合零成本批量内容生成和自动化场景。
为什么需要本地部署大模型?
ChatGPT虽然强大,但在实际使用中面临几个现实问题:需要科学上网、账户付费、服务偶尔不稳定。就在录制这期内容的当天下午,ChatGPT官方就出了故障,导致一个多小时无法使用。如果你的工作流高度依赖AI,这种中断是难以接受的。
更重要的是,如果你需要大量生成内容——比如批量生成文案、自动化处理文本——每次调用ChatGPT API都意味着真金白银的支出。而本地部署的开源大模型,一次配置,永久免费使用,断网也能独立运行。
**开源大模型(Open Source LLM)**是指权重文件和推理代码对外公开的大型语言模型。与ChatGPT这类闭源模型不同,开源模型允许用户下载完整的模型参数文件到本地运行,无需通过API调用远程服务器。Meta的Llama系列和阿里的通义千问(Qwen)系列是目前最具代表性的开源大模型,它们在多项基准测试中已接近甚至超越同等规模的闭源模型。
本文将介绍目前最稳定的本地大模型管理工具——Ollama,以及如何用它在本地跑起Llama 3、通义千问等主流开源模型。
Ollama vs 其他方案:为什么选它?
之前社区里比较流行的本地大模型方案是Jan(一款集成式的大模型管理应用),但在实际使用中暴露出不少问题:
- 跑Llama 3不稳定,经常失败
- 聊几轮之后就无法继续对话
- 不支持国内的开源模型(如通义千问系列)
Ollama则完美解决了这些痛点。它采用模型管理与UI分离的架构思路——Ollama专注于模型的下载、加载和运行,保证服务的稳定性;而聊天界面可以交给LobeChat等更专业的前端工具。这种解耦设计让整个系统更加稳定可靠。
在底层,Ollama基于 llama.cpp 构建,后者是一个高度优化的C++推理引擎,专门针对CPU和GPU混合推理场景做了深度优化,支持Apple Silicon的Metal加速、NVIDIA的CUDA加速以及AMD的ROCm加速。Ollama在此基础上封装了类似Docker的模型管理体验——每个模型都有独立的Modelfile描述文件,通过统一的CLI和REST API对外提供服务,使得模型的拉取、运行、切换变得像管理容器镜像一样简单直观。
Ollama安装部署:三步搞定
第一步:下载安装Ollama
访问Ollama官网(ollama.com),直接下载对应系统的安装包。支持macOS、Linux、Windows三大平台。
安装过程极其简单:打开安装包,点击"Install",一键完成。没有复杂的配置,没有环境依赖,开箱即用。
第二步:下载并运行模型
安装完成后,打开终端,使用以下命令即可下载并运行模型:
# 运行Llama 3(8B版本),首次会自动下载
ollama run llama3
# 运行通义千问2(默认7B版本)
ollama run qwen2
# 运行通义千问2的0.5B小模型
ollama run qwen2:0.5b
# 仅下载模型不运行
ollama pull qwen2
# 查看本地已下载的模型
ollama list
Ollama支持断点续传,下载大模型时如果网络中断,下次会接着上次的进度继续下载。如果配置了代理,下载速度可以达到二三十MB/s。
值得注意的是,Ollama默认使用量化(Quantization)技术压缩模型体积。量化是将模型权重从32位浮点数(FP32)压缩为4位或8位整数的过程,可将显存占用降低至原来的1/4到1/8,同时保留大部分模型能力。这也是为什么参数量高达70亿的7B模型只需约6GB显存即可流畅运行的核心原因。
第三步:配置跨域访问(关键)
Ollama运行后默认监听 http://127.0.0.1:11434 端口,可以通过API进行交互。但如果你想通过网页端的聊天界面(如LobeChat)调用这个接口,会遇到跨域安全限制(CORS)。
CORS(Cross-Origin Resource Sharing,跨域资源共享)是浏览器的一项安全机制。当网页(如LobeChat运行在localhost:3000)尝试向不同端口的服务(如Ollama运行在localhost:11434)发起请求时,浏览器会先发送一个预检请求(Preflight Request),只有服务端明确允许该来源,浏览器才会放行真正的数据请求。
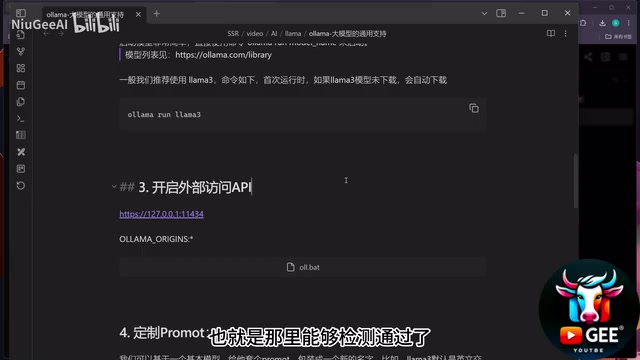
解决方法是设置系统环境变量:
OLLAMA_ORIGINS=*
这条环境变量告知Ollama在响应头中添加 Access-Control-Allow-Origin: *,允许任意来源的跨域访问,从而解除浏览器的安全拦截。设置方式有两种:
- 永久生效:在系统环境变量中添加(Windows通过"系统属性-环境变量"设置)
- 临时生效:通过批处理脚本(.bat文件)在启动Ollama前自动注入环境变量
模型选择与显存要求
Ollama支持的模型非常丰富,在其Models页面可以看到完整列表。大模型的参数规模(如7B、14B中的B代表Billion,即十亿)直接决定了模型的能力上限和硬件需求。下面是几款常用模型的对比:
| 模型 | 参数规模 | 显存需求(约) | 特点 |
|---|---|---|---|
| Llama 3 8B | 80亿 | ~7GB | Meta开源,综合能力强 |
| Qwen2 7B | 70亿 | ~6GB | 阿里开源,中文优秀 |
| Qwen2 0.5B | 5亿 | ~352MB | 极轻量,速度极快 |
| Qwen2 14B | 140亿 | ~10GB | 精度更高,需要更多显存 |
核心原则:模型参数越大,精度越高,但显存需求也越大。 以视频作者的显卡为例,跑Llama 3 8B大约占用7GB显存,理论上12-14B的模型也能跑,但16B就吃不消了。
实际效果对比:Llama 3 vs 通义千问
Llama 3 8B
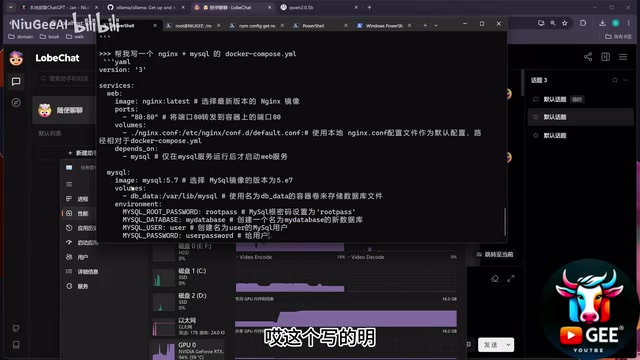
让它生成一个Nginx + MySQL的Docker Compose配置文件,能够正确生成基本结构,MySQL 3306端口通过volume方式挂载,还附带了相关配置说明。整体可用,但细节上偶有瑕疵。
通义千问2 14B
同样的Docker Compose任务,千问14B的表现明显更靠谱:直接返回了正确的Docker Compose V3版本配置,环境变量设置完整,端口映射正确(3306暴露),还贴心地加了大量注释说明。
值得一提的是,通义千问系列在响应速度上明显优于Llama 3,尤其是对中文的支持更加自然流畅。这背后有深层的技术原因:通义千问的预训练语料库中包含了大量高质量中文文本,中文token的覆盖比例远高于以英文为主的Llama系列。此外,Qwen系列采用了针对中文优化的分词器(Tokenizer),能更高效地编码中文字符,减少同等文本所需的token数量,直接带来更快的推理速度和更低的上下文占用。
本地部署大模型的实际价值
有人可能会问:既然ChatGPT那么好用,为什么还要折腾本地部署?核心价值在于以下几点:
- 成本控制:大量内容生成场景(如批量文案、自动化脚本)下,本地模型零边际成本
- 稳定可靠:不依赖网络,不受第三方服务故障影响,断网也能工作
- 隐私安全:敏感数据不出本地,适合企业内部使用
- 差异化输出:不同模型有不同的"风格",可以产生与ChatGPT不同的内容效果
- 自动化集成:通过API接口,可以轻松接入各种自动化工作流
对于专用领域的任务,只要把Prompt模板调教好,本地开源模型完全能够满足需求。Ollama负责稳定运行模型,前端交互可以搭配LobeChat等工具,打造一套完全属于自己的AI工作站。
核心要点
- Ollama是目前最稳定的本地大模型管理工具,底层基于llama.cpp构建,支持Llama 3、通义千问等主流开源模型,可断网独立运行
- 安装部署极其简单:一键安装Ollama,通过命令行下载运行模型,支持断点续传;Ollama默认使用量化技术大幅降低显存需求
- 需要设置OLLAMA_ORIGINS=*环境变量解决浏览器CORS跨域限制,才能配合网页端聊天界面使用
- 模型选择取决于显存大小:8B模型约需7GB显存,14B模型效果更好但需要更多资源
- 本地部署的核心价值在于零成本批量使用、断网可用、数据隐私安全,适合自动化内容生成等场景
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。