Ollama+Gemma 4本地运行Codex:零成本AI编程完整指南
通过Ollama本地运行Gemma 4模型,实现零成本使用Codex编程功能
文章介绍了如何用Ollama+Gemma 4替代付费的OpenAI Codex服务。Ollama通过兼容OpenAI API格式在本地运行开源模型,Gemma 4是谷歌最强开源模型(Apache 2.0许可证,支持2B到31B四种尺寸,128K上下文窗口)。只需安装Ollama、下载模型、运行一行命令即可集成到Codex,将每月20-200美元的支出转化为零成本本地使用。
Codex的崛起与付费困境
OpenAI Codex已悄然成为最热门的编码工具之一。截至今年4月,每周有300万人使用Codex,短短三个月内增长了5倍。Sam Altman甚至发文谈论过重置Codex的使用限制,产品每周新增用户数不断突破百万级别。
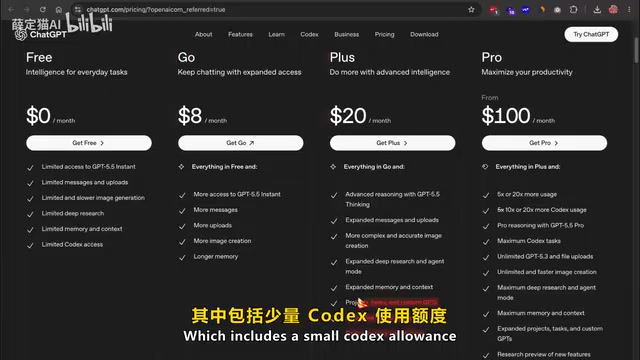
然而,强大的功能伴随着不菲的价格。Codex目前主要通过付费服务提供:最便宜的入门选项是每月20美元的ChatGPT Plus(包含少量Codex使用额度),接着是每月100美元的专业版套餐(使用量是Plus版的5倍),重头戏则是每月200美元的高级套餐(使用量是Plus版的20倍)。
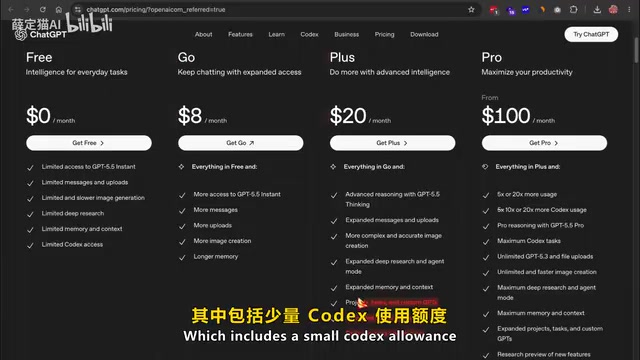
对于独立开发者和业余爱好者来说,大多数硬核用户一周内就会消耗殆尽免费额度。那么,有没有一种方式能够零成本使用Codex的完整功能?答案是:Ollama + Gemma 4。
Ollama是什么:开源模型的本地运行环境
Ollama是一个开源模型的本地运行环境。安装后,它会从模型库下载模型并在本地电脑上暴露一个兼容OpenAI的API地址(本地11434端口)。这正是它的妙处——因为Ollama模仿了OpenAI的API格式,Codex就能和它对话,就像在和OpenAI服务器通信一样,只不过所有数据都不会离开你的本地硬件。
OpenAI API兼容性的技术原理
Ollama之所以能够无缝替代OpenAI的云端服务,关键在于它实现了与OpenAI Chat Completions API完全兼容的HTTP接口。OpenAI的API规范已经成为LLM领域的事实标准——几乎所有主流工具和框架(包括LangChain、LlamaIndex、Continue等)都以此为基础进行集成。Ollama在本地启动后,会在localhost:11434端口暴露一个REST API,接受与OpenAI格式相同的JSON请求体(包括model、messages、temperature等参数),并返回相同格式的响应。这意味着任何原本设计为调用OpenAI服务器的客户端,只需将API地址从api.openai.com改为localhost:11434,就能立即切换到本地推理,无需修改任何业务逻辑代码。这种"API兼容"的设计哲学,使得整个开源生态能够站在OpenAI建立的标准之上,快速实现工具链的互操作性。
Ollama的模型库里有成百上千种模型,包括Gemma 4、DeepSeek、Llama 4、Mistral等,你可以轻松切换模型,只需一条命令就能完成。Codex会使用你指定的模型,因此这套设置对所有模型都适用。
Gemma 4:谷歌最强开源编程模型
许可证的重大突破
Gemma 4是谷歌迄今最强大的开源版本。最大的改变在于其许可证——此前的Gemma版本采用谷歌自定义的有限制许可证,让企业法务团队有所顾虑。而Gemma 4采用Apache 2.0许可证,完全的商业自由,无任何使用限制,你可以基于它自由开发和发布。
Apache 2.0许可证是开源软件领域最宽松的许可证之一,由Apache软件基金会维护。与之前Gemma系列使用的Google自定义许可证相比,Apache 2.0的核心区别在于:它允许任何人在任何场景下自由使用、修改、分发和商业化模型,唯一的要求是保留原始版权声明和许可证文本。这意味着企业可以将Gemma 4直接嵌入商业产品中,无需担心用户数量限制、收入门槛限制或特定用途禁止条款。相比之下,Meta的Llama系列虽然也被称为"开源",但其社区许可证对月活超过7亿的企业有额外限制。Apache 2.0的采用消除了企业法务团队的顾虑,大幅降低了商业部署的合规成本,这也是为什么Kubernetes、TensorFlow等重要开源项目都选择了这一许可证。
四种尺寸满足不同硬件需求
该系列共有4种尺寸:
- 2B:最小款,约20亿有效参数,运行内存占用低于1.5G,专为手机和轻量级硬件打造
- 4B:约40亿有效参数,适用于边缘设备及笔记本电脑
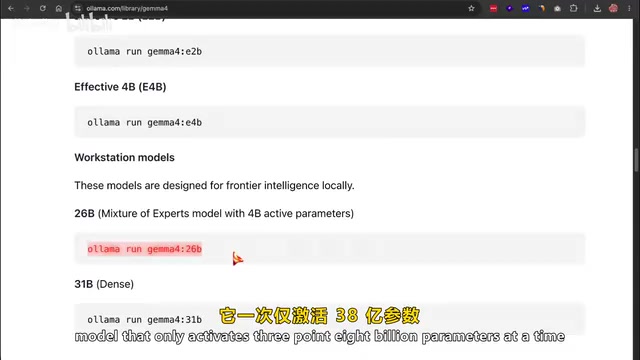
- 26B:混合专家模型(MoE),一次性激活38亿参数,对消费级GPU非常友好
- 31B:密集模型,在Erna AI排行榜上目前排名第三
混合专家模型(MoE)架构解析
Gemma 4的26B版本采用了混合专家模型(Mixture of Experts, MoE)架构,这是近年来大模型领域最重要的效率突破之一。传统的密集模型(Dense Model)在每次推理时会激活所有参数,而MoE架构将模型的前馈网络层拆分为多个"专家"子网络,每次推理时通过一个门控网络(Gating Network)只选择性地激活其中一小部分专家。例如26B模型虽然总参数量达260亿,但每次推理只激活38亿参数,这使得它的实际计算开销和显存占用远低于同等参数规模的密集模型。这一架构最早由Google在Switch Transformer论文中大规模验证,后来被Mixtral、DeepSeek-V2等模型广泛采用。MoE的核心优势在于:模型可以拥有更大的知识容量(因为总参数多),同时保持较低的推理成本(因为每次只用一小部分参数),这正是26B模型能在消费级GPU上流畅运行的关键原因。
核心技术亮点
谷歌使用一种叫"逐层嵌入"的技术,实际推理时计算量远少于理论参数量,因此这些小型模型的实际能力远超其参数规模。所有Gemma 4模型都原生支持多模态(文本、图像、最多30秒音频输入),上下文窗口高达128K Token,支持超过40种语言,并具备原生函数调用能力和结构化输出——这正是智能体式编码所需要的行为。
128K Token的上下文窗口意味着模型在单次对话中可以处理约10万个英文单词或约20万个中文字符的内容。在编程场景中,这大约相当于一次性读取一个中等规模项目的完整代码库(约3000-5000行代码加上相关文档)。上下文窗口的大小直接决定了AI编码助手的实用性——窗口太小,模型无法理解跨文件的依赖关系和项目整体架构;窗口足够大,模型就能在理解全局上下文的基础上进行精确的代码修改和重构。早期的GPT-3.5只有4K Token的上下文窗口,这严重限制了它处理复杂编程任务的能力。128K的窗口使得Gemma 4可以同时处理多个源文件、测试文件和配置文件,实现真正的项目级代码理解和生成。
31B模型在M2026评测中得分89.2%,代码模型的Elo评分约为2500,达到了专业竞赛级选手的水平。
Ollama+Codex完整安装与配置教程
第一步:安装Codex
首先安装Codex桌面应用,或者通过NPM使用Codex CLI(如果你只喜欢用终端)。两种方式都支持Ollama集成。
第二步:安装Ollama
去官网下载安装包或在终端里用Curl命令安装。确保版本是0.24或更新,因为Codex启动器集成需要最新版。安装完成后让Ollama在后台运行,你应该会在菜单栏/系统托盘看到一个图标。
第三步:下载Gemma 4模型
打开终端输入以下命令即可开始下载:
ollama pull gemma4:2b
2B模型文件很小,只有两三个GB。
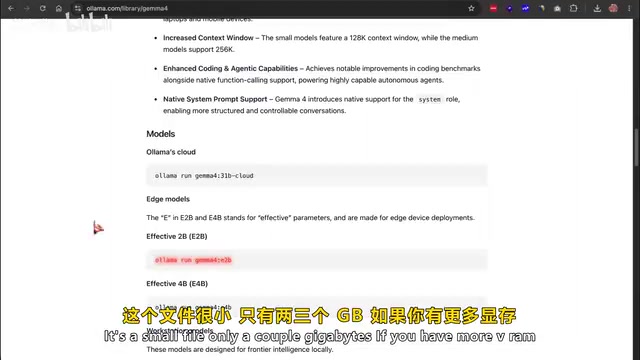
如果你有更多显存并想要更好的输出,可以选择:
- 14B:接近9G
- 26B/31B:需要16G到24G显存的独立显卡
如果不确定硬件能运行哪些模型,可以访问 "Can I Run It Locally" 网站,输入硬件配置即可获得建议。
第四步:将Ollama集成到Codex
最简洁的方法是使用Ollama在终端添加的单行启动器:
ollama run codex
这个命令会打开一个选择器,检测你本地安装的所有模型并列出。从列表中选择Gemma 4模型,回车后Codex应用就会启动并加载该模型。
Codex打开后你会看到一个Ollama的小标签,显示本地模式已激活。从这里开始,整个Codex的使用体验都一样——你可以让它执行生成式编码任务、编辑文件、使用内置浏览器、运行终端命令,所有功能都可用。
本地AI编程实际效果演示
在演示中,我用一个简单指令让Gemma 4(2B版本)构建一个SaaS落地页,包括页头、功能网格、定价卡片和行动号召。
处理速度大约每秒30到40个Token,对迭代编码来说足够快。
Token生成速度与开发者体验
每秒30-40个Token的生成速度在本地推理场景中是一个关键的体验指标。一个Token大约对应0.75个英文单词或0.5个中文字符,因此30-40 Token/s意味着每秒输出约22-30个英文单词,接近人类快速阅读的速度。在编程场景中,一行典型的代码大约包含10-15个Token,所以这个速度意味着每秒可以生成2-4行代码。对于交互式编码来说,这个速度已经足够流畅——开发者可以实时看到代码逐行生成,及时判断方向是否正确并随时中断。作为对比,OpenAI的云端GPT-4o通常能达到80-100 Token/s,但这需要依赖远程服务器的高端GPU集群。本地推理的速度主要受限于GPU的显存带宽和计算能力,使用量化技术(如Q4_K_M)可以在牺牲少量精度的前提下显著提升推理速度。
生成的页面包含:渐变背景的头部设计、三栏功能展示、简洁的定价卡片、带社交链接的页脚,CSS样式内联,响应式断点也已设置。
对于一个仅有20亿有效参数的模型,能在消费级硬件上本地离线运行并产出这样的结果,这是实实在在的成果。当然它比不上Claude Opus的质量,但对于免费的本地部署且无计费模式,这套工作流程完全能满足日常使用。
如何恢复云端Codex
如果你想取消本地集成、恢复使用普通的云端Codex,在终端里运行:
ollama codex restore
即可重置配置,回到原来的ChatGPT计划。
总结:零成本AI编程的最佳实践
像Gemma 4这样的开源模型,搭配Ollama,再加上Codex桌面应用,就能构建一个完全自主、在本地运行的编程栈——私密、免费、无速率限制,而且模型切换只需一个命令。等有更好的模型发布,直接换上就行,工作流程完全不受影响。
这套方案的核心价值在于:将每月20-200美元的持续支出,转化为一次性的硬件投入和零边际成本的使用体验。对于预算有限但需要高频使用AI编码工具的开发者来说,这是目前最务实的选择。
核心要点
- Ollama通过模仿OpenAI API格式,让Codex能够无缝对接本地运行的开源模型,实现零成本AI编程
- Gemma 4采用Apache 2.0许可证,提供2B到31B四种尺寸,31B模型在AI排行榜排名第三
- 完整配置仅需安装Ollama、下载模型、运行一行命令即可集成到Codex,所有功能均可正常使用
- 即使是最小的2B模型也能在消费级硬件上以每秒30-40 Token的速度产出可用的编码输出
- 这套方案将每月20-200美元的持续支出转化为零边际成本的本地使用体验,模型切换仅需一条命令
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。