ONNX模型部署实战:从PyTorch导出到跨框架推理完整指南
ONNX是神经网络的通用交换格式,实现模型训练与推理环境的解耦。
ONNX(Open Neural Network Exchange)是一种开放的神经网络通用交换格式,由Meta和Microsoft于2017年联合开发,旨在解决深度学习框架间模型无法互通的问题。它将模型训练环境与推理环境彻底解耦,支持从PyTorch、TensorFlow等框架导出模型,通过轻量级的ONNX Runtime在不同硬件上高效推理,还可结合HuggingFace生态和量化技术实现端侧部署。
什么是ONNX?神经网络的通用交换格式
如果你曾经在PyTorch中训练了一个模型,却需要在一个没有PyTorch的环境中部署它,你就会理解ONNX(Open Neural Network Exchange)的价值。ONNX本质上是神经网络的一种通用交换格式——就像PDF之于文档一样,无论你用什么软件创建,最终都能在任何PDF阅读器中打开。
ONNX诞生于2017年,彼时深度学习框架战国时代正值高峰——PyTorch、TensorFlow、Caffe2、MXNet各自为政,模型无法跨框架流通。ONNX最初由Facebook(Meta)和Microsoft联合开发,初衷正是打破这种碎片化困境。2019年,ONNX被移交给Linux基金会旗下的LF AI & Data基金会管理,标志着它从企业项目演变为真正的开放社区标准。目前ONNX已获得Amazon、Intel、NVIDIA、Qualcomm等数十家主流硬件和软件厂商的支持,现在已经是一个完全开放的标准。
它的核心理念非常简单:将模型的训练环境与推理环境彻底解耦。你可以在PyTorch中训练模型,在TensorFlow中训练模型,或者从HuggingFace下载模型,然后统一导出为ONNX格式,使用轻量级的ONNX Runtime进行推理,完全不需要原始框架的任何依赖。
PyTorch模型导出ONNX实战
最简示例:一个加一网络
为了演示ONNX的工作原理,我们从一个极简的例子开始——一个只做"输入加一"操作的神经网络:
import torch
class AddOne(torch.nn.Module):
def forward(self, x):
return x + 1
model = AddOne()
model.eval()
导出为ONNX格式只需要一个函数调用。不过在PyTorch中,导出时需要提供样本数据来推断计算图(这与TensorFlow不同)。这一差异源于PyTorch的动态计算图(Dynamic Computation Graph)机制——PyTorch采用"define-by-run"策略,计算图在每次前向传播时动态构建,框架本身并不预先知道图的结构。导出时,PyTorch通过追踪(tracing)一次真实的前向传播来捕获计算图的静态快照,因此必须提供dummy数据触发这次追踪:
x = torch.tensor([1.0, 2.0, 3.0])
torch.onnx.export(
model, (x,), "add_one.onnx",
input_names=["input"],
output_names=["output"],
dynamo=True
)
执行后,你会得到一个add_one.onnx文件,这就是你的模型——完全独立于PyTorch。
使用ONNX Runtime进行推理
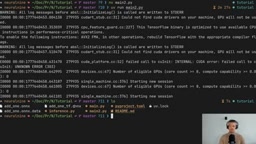
ONNX Runtime(ORT)并非简单的模型解释器,其核心架构是可插拔的执行提供程序(Execution Provider,EP)体系。ORT内置了针对不同硬件的EP:CPU EP使用Intel MKL-DNN/OpenBLAS加速矩阵运算,CUDA EP调用cuDNN和cuBLAS实现GPU加速,TensorRT EP进一步利用NVIDIA的推理优化编译器,DirectML EP面向Windows平台的GPU,CoreML EP则专为Apple Silicon设计。这种架构使得同一个ONNX模型文件无需修改即可在不同硬件上获得接近原生的性能。
推理代码完全不依赖PyTorch,只需要onnxruntime和numpy:
import numpy as np
import onnxruntime as ort
session = ort.InferenceSession("add_one.onnx")
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
x = np.array([10, 15, 23], dtype=np.float32)
output = session.run([output_name], {input_name: x})[0]
print(f"Input: {x}, Output: {output}")
运行结果:输入[10, 15, 23],输出[11, 16, 24]——每个值都加了一。整个过程没有任何PyTorch依赖,你可以把.onnx文件复制到任何机器上,只安装ONNX Runtime就能运行。
TensorFlow模型导出ONNX的差异
同样的功能用TensorFlow实现,导出后的ONNX文件可以用完全相同的推理代码运行:
import tensorflow as tf
import tf2onnx
class AddOne(tf.Module):
@tf.function(input_signature=[tf.TensorSpec([None], tf.float32, name="input")])
def __call__(self, x):
return x + 1
model = AddOne()
onnx_model, _ = tf2onnx.convert.from_function(
model.__call__,
input_signature=[tf.TensorSpec([None], tf.float32, name="input")],
output_path="add_one_tf.onnx"
)
有意思的是,TensorFlow导出时不需要提供dummy数据来推断计算图。这背后的原因在于两个框架的图构建机制根本不同:TensorFlow的tf.function通过AutoGraph将Python代码编译为静态图,input_signature装饰器提供的类型和形状信息足以在不运行任何数据的情况下完整描述计算图结构,因此导出器可以直接从图定义中提取所需的元数据信息。这是两个框架在ONNX导出流程上的一个有趣差异。
关键点在于:只要导出时保持相同的input_names和output_names,推理代码就是完全通用的,无论模型来自哪个框架。
真实场景:MNIST手写数字分类器的ONNX部署
简单的加一网络只是概念验证。在实际应用中,我们可以训练一个完整的MNIST分类器,然后导出为ONNX格式进行部署。模型结构包括:
- Flatten层(将28×28图像展平)
- Linear层 + ReLU激活函数
- 输出层(10个类别)
训练5个epoch后,导出时只需提供一个随机的28×28像素张量作为dummy数据:
dummy = torch.randn(1, 1, 28, 28)
torch.onnx.export(model, (dummy,), "mnist_mlp.onnx", ...)
推理时,加载MNIST测试集的真实图片,通过ONNX Runtime预测。实测结果显示,模型正确预测了数字"7"——整个推理过程中唯一的PyTorch依赖仅仅是用来加载测试数据集,模型推理本身完全由ONNX Runtime完成。
从HuggingFace直接拉取ONNX模型
ONNX的另一个强大应用场景是直接从HuggingFace下载已经转换好的ONNX格式模型。许多模型仓库已经提供了ONNX版本,特别是针对CPU和移动端优化的量化模型。
仓库命名中常见的"cpu-int4"涉及模型量化(Quantization)技术。标准神经网络权重通常以FP32(32位浮点)或FP16(16位浮点)存储,而INT4量化将权重压缩为4位整数表示,模型体积缩减约8倍,内存占用和计算量大幅降低。代价是精度的轻微损失,但现代量化算法(如GPTQ、AWQ)通过校准数据集补偿精度损失,使量化后模型在大多数任务上与原始模型性能相当。对于在CPU或移动端运行大语言模型而言,INT4量化几乎是必要条件而非可选优化。
下载流程非常简单:
hf download <model_path> --include <onnx_file> --local-dir ./model_onnx
下载完成后,使用onnxruntime-genai包可以直接进行生成式AI推理:
import onnxruntime_genai as og
model = og.Model("./model_onnx/cpu_and_mobile/cpu-int4-...\
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。