OpenAI Agents SDK追踪功能使用指南:零配置实现Agent可观测性
OpenAI Agents SDK内置追踪系统实现AI Agent全链路可观测性
文章介绍了AI Agent可观测性的重要性及OpenAI Agents SDK内置追踪系统的使用方法。由于Agent行为具有概率性,传统监控难以胜任,专用追踪系统成为必需。该SDK支持零配置自动追踪,可记录LLM推理、工具调用、耗时等完整信息。同时提供trace上下文管理器支持自定义工作流名称、分组ID和元数据,实现精细化监控与筛选,并对工具调用(如Web Search)提供全链路追踪支持。
为什么AI Agent需要可观测性
构建基于AI Agent的应用时,一个核心挑战是:你很难知道Agent内部到底发生了什么。它调用了哪些工具?每个步骤耗时多少?输入输出分别是什么?这些问题在调试和优化时至关重要。
**可观测性(Observability)**这一概念源自控制论,在软件工程领域指通过系统外部输出推断内部状态的能力。传统微服务架构中,可观测性通常由日志(Logs)、指标(Metrics)和追踪(Traces)三大支柱构成。AI Agent的出现让这一挑战显著升级:Agent不仅是确定性代码,还包含LLM推理、动态工具选择和多步骤规划,其行为本质上是概率性的,传统监控手段难以捕捉"模型为什么做出这个决策"。因此,专为Agent设计的追踪系统成为不可或缺的基础设施。
OpenAI Agents SDK内置了一套强大的追踪(Tracing)系统,几乎不需要额外配置,只需传入API Key并开启追踪功能,就能获得Agent运行的完整可视化信息。本文将详细介绍这套追踪系统的使用方法,包括基础配置、自定义追踪以及工具调用的追踪。
OpenAI Agents SDK追踪系统能看到什么
在OpenAI的Dashboard中,追踪系统会自动记录Agent运行的每一个步骤。以一个JFK文档助手的RAG管道为例,追踪面板可以清晰展示:
- LLM生成文本的过程:包括模型决定调用哪个工具(如JFK文件搜索工具)
- 工具调用的返回结果:搜索了什么内容、返回了哪些文档
- 每个步骤的耗时:初始工具调用约1秒,响应时间约100毫秒,最终响应因需要处理大量文档而耗时更长
- 完整的输入输出:包括传入的文档内容和最终生成的回答
RAG管道背景:RAG(Retrieval-Augmented Generation,检索增强生成)是当前主流的知识增强方案。其核心思路是:在LLM生成回答前,先从外部知识库检索相关文档片段,再将检索结果与用户问题一起送入模型。这解决了LLM知识截止日期和幻觉问题。JFK文档助手是一个典型RAG场景——需要从大量解密档案中精准检索,追踪系统在此类场景中尤为重要,因为检索质量直接决定最终答案的准确性,而追踪面板能清晰呈现每一次检索的输入与输出,帮助开发者快速判断检索环节是否存在问题。
这些信息对于理解Agent行为、定位性能瓶颈和调试问题都极为有价值。
基础配置:开启Agent追踪功能
权限设置
使用追踪功能前需要注意一个关键点:如果你属于某个OpenAI组织,追踪信息默认只有组织所有者可见。
OpenAI的组织(Organization)权限体系类似企业级SaaS的多租户模型。一个组织下可以有多个项目(Project)和多个成员,成员角色分为Owner和Member。追踪数据涉及用户输入、模型输出等敏感信息,因此默认仅Owner可见,这是出于数据安全和合规考量——在企业环境中,这些运行时数据可能包含业务敏感内容,需要结合数据治理策略谨慎配置访问权限。
普通工程师需要进行以下配置:
- 点击Dashboard右上角的设置图标
- 进入「Data Controls」
- 找到日志可见性设置,包括Response Logs和Stored Traces
- 将「Track Completions and Traces」设置为对所有人可见、对选定项目可见,或仅对自己可见
- 点击保存
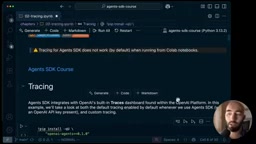
完成权限配置后,进入Dashboard的Traces页面即可查看所有追踪记录。
零配置自动追踪
最令人惊喜的是,基础追踪几乎不需要任何额外代码。只需正常创建Agent并运行,追踪信息就会自动收集:
from agents import Agent, Runner
agent = Agent(
name="tracing prompt agent",
instructions="speak like a pirate",
model="gpt-4.1-nano"
)
result = await Runner.run(agent, "write a one sentence poem")
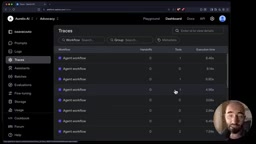
运行后在Dashboard中查看最新的追踪记录,可以看到Agent名称、Token使用量(如43 tokens)、使用的模型版本、指令内容、用户输入以及助手输出——所有这些信息都是自动采集的,无需编写任何追踪代码。
注意:截至目前,追踪功能在Google Colab中无法正常工作,需要在本地环境运行。
自定义追踪:实现更精细的Agent监控
使用trace上下文管理器
虽然默认追踪已经很强大,但有时我们需要更精细的控制。Agents SDK提供了trace函数作为上下文管理器,允许自定义追踪参数:
from agents import trace
with trace(
workflow_name="prompt agent workflow",
group_id="agents SDK course tracing"
):
result = await Runner.run(agent, "write a one sentence poem")
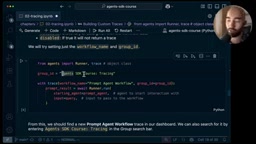
这里有两个关键参数:
- workflow_name:自定义工作流名称,替代默认的"agent workflow",便于在Dashboard中快速识别
- group_id:分组标识符,可以将相关的追踪记录归为一组,支持在Dashboard中按组筛选
group_id的设计借鉴了分布式追踪领域的Trace Context标准(如W3C TraceContext)。在复杂系统中,一个业务请求可能跨越多个服务、多次LLM调用,需要一个关联标识符将散落的追踪片段串联成完整链路。group_id在Agents SDK中扮演类似角色——它不是单次运行的唯一ID,而是一个逻辑分组标签,允许开发者将同一功能模块、同一测试批次或同一用户会话的所有追踪归为一组。在Dashboard中,可以通过搜索group_id来过滤特定分组的所有追踪记录,也可以按workflow_name进行筛选,这在管理大量追踪数据时非常实用。
添加元数据(metadata)
除了基本的命名和分组,还可以为追踪添加自定义元数据,用于更灵活的筛选和分析:
with trace(
workflow_name="web search agent",
group_id="agents SDK course tracing",
metadata={"tools": "web_search_tool"}
):
result = await Runner.run(agent, "world headlines")
在Dashboard中可以根据元数据进行过滤,例如筛选所有使用了web_search_tool的追踪记录。你可以在元数据中添加任意键值对,比如环境标识(env: production)、版本号(version: v2.1)、用户ID等,满足各种运维和分析需求。结构化的元数据设计让追踪系统不仅是调试工具,更能支撑A/B测试分析、用户行为研究等更复杂的数据分析场景。
工具调用追踪:监控Agent的外部交互
追踪系统对工具调用的支持尤为出色。以OpenAI内置的Web Search工具为例:
from agents import WebSearchTool
agent = Agent(
name="tracing tool agent",
instructions="You are a website agent that searches the web for information on user queries",
model="gpt-4.1-mini",
tools=[WebSearchTool()]
)
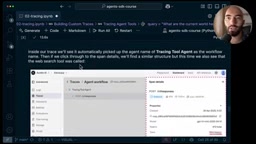
OpenAI的工具调用底层依赖Function Calling机制,该机制自GPT-4时代引入并持续演进。模型在生成回答时,若判断需要外部信息,会输出一个结构化的JSON调用请求而非直接生成文本,由宿主程序执行实际工具逻辑后将结果返回模型。WebSearchTool是对这一机制的高层封装——追踪系统能将"模型决策→发出调用请求→执行搜索→返回结果→模型整合
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。