OpenAI Codex免费额度实测:每周仅20次,Bug修复实战对比
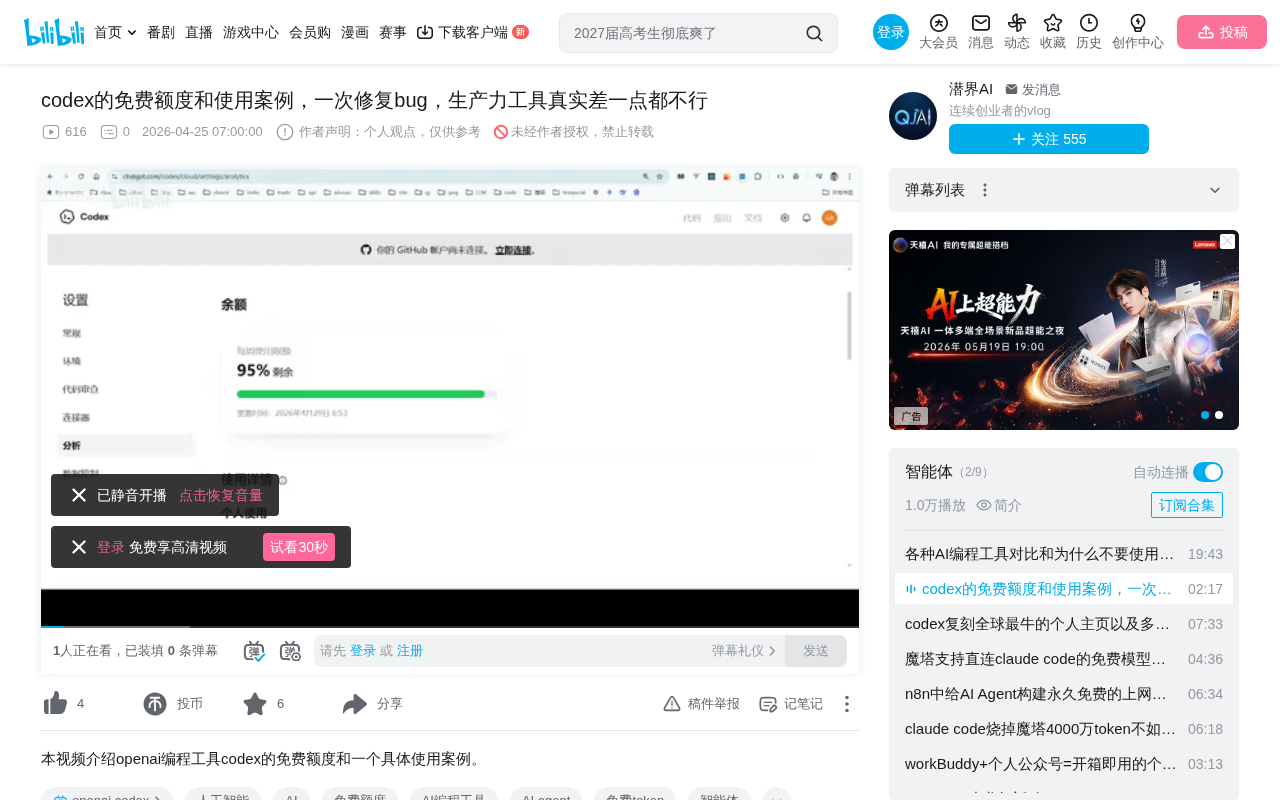
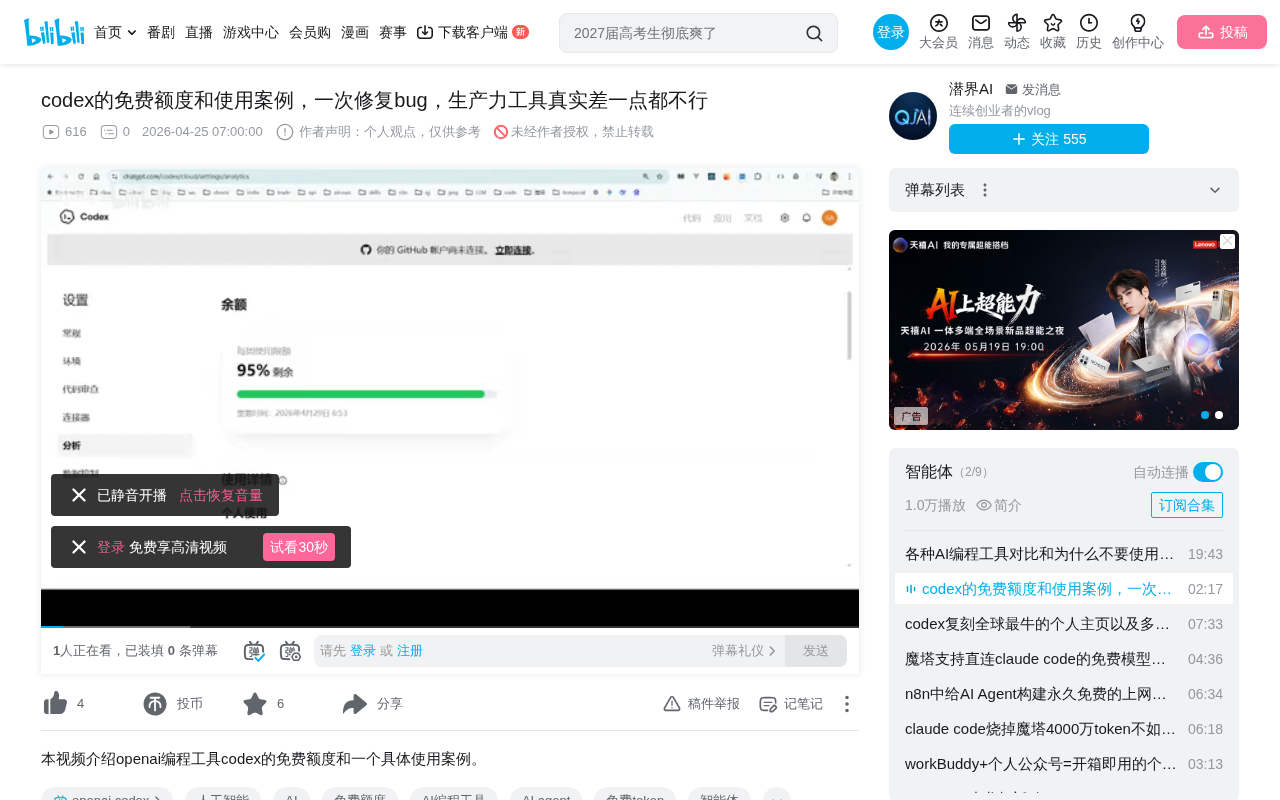
OpenAI Codex免费额度每周约20次,实测修复Bug能力显著优于其他AI编程工具。
OpenAI Codex基于o3架构的codex-1模型,免费用户每周约可调用20次(每次消耗约5%周额度)。通过一个文字转视频项目的黑屏Bug修复案例,Codex凭借云端沙箱异步代理模式和深层代码推演能力,一次性定位并修复了多款AI工具都未能解决的问题。这揭示了AI编程工具间微小的能力差距往往决定关键问题能否被解决,选择工具应重实际能力而非免费额度。
引言
OpenAI 近期推出的编程工具 Codex 在开发者圈子里掀起了不小的波澜。作为 GPT 系列模型在编程领域的最新落地产品,Codex 不仅具备出色的代码生成和修复能力,还为免费用户开放了一定的使用额度。
从技术背景来看,2025 年推出的最新版 Codex 运行在 codex-1 模型之上,该模型基于 o3 架构并通过强化学习进行了针对性的编程任务微调。与通用对话模型不同,Codex 在训练过程中大量使用了开源代码库、技术文档和编程问答数据,使其对代码结构、函数调用链和程序执行逻辑有更深层的理解。更重要的是,Codex 的核心设计理念是作为一个"异步编程代理"——它不仅仅是补全代码片段,而是能够在云端沙箱环境中独立阅读整个代码仓库、理解项目上下文、编写并运行测试,最终以 Pull Request 的形式交付完整的代码修改方案。这种端到端的工作模式使其与传统的代码补全工具(如 GitHub Copilot 的行内补全)形成了本质区别。
本文将通过实测数据揭示 Codex 免费额度的真实上限,并分享一个文字转视频项目中的 Bug 修复案例——同一个问题,多款 AI 工具束手无策,Codex 却一次搞定。这背后反映的,正是 AI 编程工具之间"差之毫厘,谬以千里"的能力鸿沟。
OpenAI Codex 免费额度到底有多少?
实测数据推算
根据实际测试,在 OpenAI 后台管理面板中可以看到,仅发送了一次请求后,本周的额度显示还剩余 95%。通过简单计算可以得出:
- 每次请求消耗约 5% 的周额度
- 免费账号每周大约可以调用 20 次
- 额度按周自动重置
换句话说,免费用户每周只有 20 次与 Codex 最新模型交互的机会。对于偶尔用一下的轻度用户,这个额度勉强够用;但对于需要频繁调试代码的开发者来说,20 次的限制确实有些紧张。
额度消耗背后的技术逻辑
AI 服务的免费额度通常通过 Token 配额或请求次数配额来实现。Token 是大语言模型处理文本的基本单位,一个英文单词通常对应 1-2 个 Token,而一个中文字符通常对应 1-3 个 Token。Codex 的额度消耗机制较为特殊:由于它在云端沙箱中执行完整的代码分析和修改流程,每次任务不仅涉及输入输出的 Token 消耗,还包括模型在沙箱中多轮推理、读取文件、运行测试等中间步骤的计算资源开销。这解释了为什么单次请求就会消耗约 5% 的周额度——每次调用背后实际上是一个复杂的多步骤代理工作流,而非简单的一问一答。OpenAI 采用按周重置的配额策略,既能防止资源被短时间内耗尽,也为免费用户提供了持续体验产品的机会。
与其他 AI 编程工具的额度对比
目前市面上的 AI 编程工具在免费额度方面差异较大。Codex 每周 20 次的调用限制处于中等水平。不过正如后面的案例所展示的,选择工具时不能只看免费次数——模型能力和实际解决问题的效率,往往比额度数字更重要。
实战案例:用 Codex 修复文字转视频黑屏 Bug
Bug 背景描述
这个案例来自一个文字转视频的项目。项目的核心功能是根据输入的文字内容自动生成视频,视频的背景图片应该与文字内容相关联。然而实际运行时出现了一个顽固的 Bug——生成的视频背景始终是纯黑色,完全没有图片显示。
要理解这个 Bug 的棘手之处,需要了解文字转视频项目的典型技术架构。这类项目通常涉及多个技术模块的协同工作,典型的流水线包括:文本解析与分段、关键词提取、图片素材生成或检索、音频合成(TTS,即文字转语音)、以及最终的视频合成与渲染。其中图片生成环节可能调用 Stable Diffusion、DALL·E 等 AI 图像生成模型,也可能通过搜索引擎 API 检索相关图片。视频合成通常使用 FFmpeg 或 MoviePy 等工具将图片序列、音频轨道和字幕叠加在一起。黑屏 Bug 的出现意味着在视频合成阶段,背景图层要么未被正确加载,要么图片生成环节本身就被跳过了。而这类 Bug 的隐蔽性在于:视频合成流程本身不会报错(FFmpeg 在缺少图片输入时会默认使用黑色画布),因此从错误日志上很难直接定位到问题根源。
这个 Bug 看上去不复杂,但在此前的尝试中,多款 AI 编程工具都没能真正修复它。这些工具分析代码后都信誓旦旦地表示"已修复",但实际运行时,生成视频的流程中压根没有"生成背景图片"这个环节——问题的根源被完全忽略了。
Codex 一次性修复的完整过程
将同样的 Bug 描述提交给 Codex 时,甚至使用了比之前更简洁的提示词。结果却出人意料:
- 精准定位问题根源——Codex 不仅理解了表面症状(黑屏),还找到了根本原因(缺少图片生成环节)
- 修复后运行日志中出现了图片生成步骤——这是之前其他工具修复后从未出现过的关键变化
- 最终生成的视频成功显示了与文字内容匹配的背景图片
从纯黑背景到有意义的背景图片,这个困扰已久的 Bug 被 Codex 一次性解决。
为什么其他工具未能定位根因
不同 AI 编程工具在代码理解上的差异,本质上源于模型架构、训练数据和推理策略的不同。表层理解是指模型能够识别代码语法、变量命名和函数签名,大多数现代 AI 编程工具都能做到这一点。深层理解则涉及对程序执行流程的推演——模型需要在"脑中"模拟代码的运行过程,追踪数据在不同模块之间的流转,识别出哪些关键步骤被遗漏或短路。在这个案例中,其他工具可能只关注了视频渲染模块的代码(因为黑屏是渲染结果),而 Codex 则追溯到了上游的图片生成环节。这种差异与模型的"推理链"(Chain of Thought)能力密切相关——o3 架构通过强化学习训练出的长链推理能力,使 Codex 能够在更长的逻辑链条上保持准确性,从而发现隐藏在调用链深处的根本原因。
AI 编程工具的"1% 差距"法则
为什么微小的模型能力差异至关重要
这个案例揭示了一个值得深思的现象:在 AI 编程工具领域,模型之间的能力差距可能只有 1%,但正是这 1% 决定了问题能否被解决。
当两个模型在 99% 的场景下表现相当时,开发者很难感知到差异。但当你遇到那个恰好落在 1% 差距区间内的问题时,一个工具能解决,另一个就是解决不了——没有中间地带,没有"差不多能用"。
提示词工程的局限性
提示词工程(Prompt Engineering)是指通过精心设计输入文本来引导 AI 模型产生更好输出的技术。常见策略包括:提供详细的上下文信息、使用少样本示例(Few-shot)、要求模型分步思考(Chain of Thought)等。然而这个案例揭示了提示词工程的一个重要局限:当模型本身缺乏对特定问题的理解能力时,再精巧的提示词也无法弥补这一缺陷。这就好比向一个不懂微积分的人用各种方式描述一道微积分题目——无论描述多么清晰,他都无法给出正确答案。反之,当模型具备足够的理解力时,即使是简洁甚至不够完美的提示词,也能触发正确的推理路径。这提醒开发者:提示词优化固然重要,但选择具备足够基础能力的模型才是前提条件。
对开发者选择 AI 工具的启示
从这个案例中,可以提炼出几条实用建议:
- 不要只依赖单一工具:当一个 AI 编程工具卡住时,换一个试试,可能会有意想不到的突破
- 提示词并非万能:这个案例中更简洁的提示词反而效果更好,说明模型本身的理解力才是核心变量
- "已修复"不等于真的修好了:一定要验证输出结果,检查运行日志中是否包含了预期的处理步骤
- 看实际效果而非免费额度:免费次数多不代表好用,能在关键时刻解决问题的工具才值得长期使用
总结
OpenAI Codex 虽然免费额度有限(每周约 20 次),但在实际的代码修复能力上展现出了明显优势。通过这个文字转视频项目的黑屏 Bug 修复案例,我们直观地看到了不同 AI 编程工具之间看似微小、实则关键的能力差异。
对于开发者而言,与其追求更多的免费调用次数,不如关注工具在棘手问题上的解决能力。毕竟在实际开发中,能解决问题的那一次调用,胜过一百次无效的尝试。
核心要点
- OpenAI Codex免费账号每周约可调用20次,每次消耗约5%的周额度
- Codex 基于 o3 架构的 codex-1 模型,采用云端沙箱异步代理模式,单次调用涉及多步骤推理和测试执行
- Codex成功一次性修复了多款AI编程工具都未能解决的视频背景生成Bug
- 其他工具未能修复的根因在于缺乏对程序执行流程的深层推演能力,仅关注了表层的渲染模块
- AI编程工具之间可能只有1%的能力差距,但这1%往往决定了关键问题能否被解决
- 提示词工程存在局限性,模型本身的基础理解能力才是解决复杂问题的前提
- 选择AI编程工具应关注实际问题解决能力,而非仅看免费额度数量
- 使用AI工具修复代码后务必验证运行日志,确认问题真正被解决
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。