OpenAI Codex深度解析:核心能力与工程化实战指南
Codex是什么?远不止AI编程助手
Codex是OpenAI官方推出的AI编程工具,但如今它的能力已经远远超越了"编程助手"的范畴。它可以通过三种方式使用:App桌面端、CLI命令行以及IDE插件(支持VS Code和Cursor)。
对于习惯在IDE中工作的开发者,推荐直接安装Codex插件,这样可以在编码过程中无缝调用AI能力,省去窗口切换的麻烦。而CLI模式则更适合喜欢命令行操作的高级用户,它允许开发者通过脚本化的方式批量调度AI任务,与现有的Shell工作流无缝衔接。
Codex的核心应用场景包括:
- 代码生成:通过对话式交互从零搭建项目
- 代码阅读:分析开源项目结构,快速理解遗留代码
- 代码审查:内置review命令,自动分析PR中的潜在问题
- Bug排查:输入线上日志,快速定位问题并给出修复方案
- 自动化开发:从需求分析到测试调试的全流程开发
核心能力全景:多任务并行与环境交互
多线程任务处理
Codex采用多线程机制,可以同时处理多个任务。比如你可以让它并行分析三个项目的代码结构,最终合并输出一份对比报告。这种跨项目的多任务处理能力,让它在复杂工程场景中表现出色。
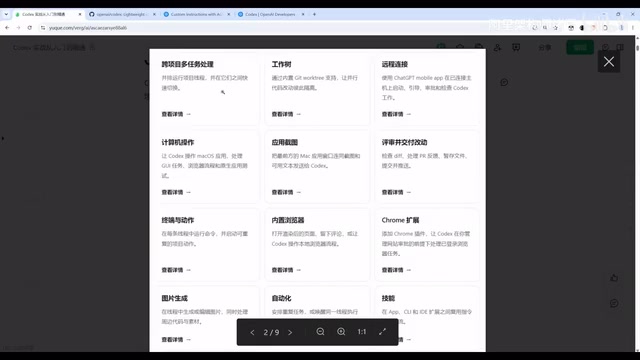
更值得关注的是它内置的Git Worktree机制。Git Worktree是Git 2.5版本引入的一项功能,允许在同一个仓库下创建多个独立的工作目录,每个目录可以检出不同的分支或提交,同时共享同一个.git目录以节省磁盘空间。传统开发中,多人协作需要创建多个分支再合并,或者频繁使用git stash暂存修改来切换上下文。而Codex通过Worktree实现了在单一仓库下的并行开发——每个AI Agent在独立的worktree中工作,代码相互隔离,互不干扰,省去了频繁建分支、合分支的操作成本,最终再通过智能合并策略整合各个Agent的产出。
Git Worktree在大型项目中的价值远超表面的便利性。在传统的多分支开发模式中,开发者切换分支时需要重新编译项目、重建索引、重启开发服务器,这些隐性成本在大型代码库中可能耗费数分钟甚至更长时间。Worktree通过维护独立的工作目录彻底消除了这一痛点。在AI Agent场景下,这一优势被进一步放大——多个Agent可以真正并行执行编译、测试等I/O密集型操作,而非排队等待单一工作目录的释放。
远程连接与跨设备操控
Codex支持远程连接,你可以在手机端远程操控电脑上的Codex执行任务。此外它还能:
- 操作浏览器、管理Chrome插件
- 执行终端命令
- 截图识别与图片生成编辑(集成DALL·E 3等模型)
- 调用macOS系统应用完成自动化任务
这种跨设备操控能力意味着开发者不再被绑定在工位上。你可以在通勤途中用手机启动一个代码重构任务,到公司时Codex已经在你的电脑上完成了修改并等待审查。
工程化设计思想:三大核心理念
规范工程取代提示词工程
Codex最显著的设计理念转变是——从提示词驱动转向规范驱动(SDD,Specification-Driven Development)。
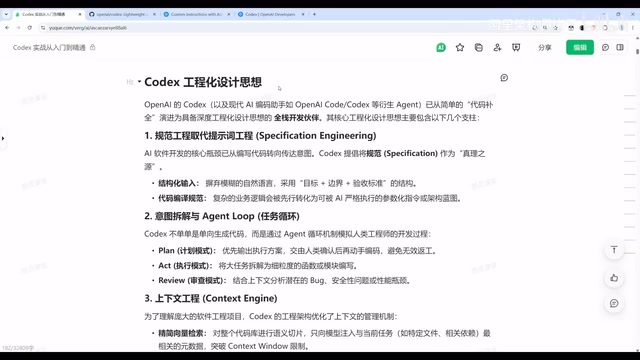
这一理念的提出有其深刻的工程背景。早期的AI编程工具依赖用户用自然语言即兴描述需求(即提示词工程),这种方式存在歧义性高、可复现性差、难以验证等固有缺陷。SDD借鉴了软件工程中TDD(测试驱动开发)和DDD(领域驱动设计)的成熟思想,要求在编码前先用结构化文档明确定义系统行为、接口契约和验收标准。
SDD的出现标志着软件工程方法论进入了第四个重要阶段。从瀑布模型强调的前期设计文档,到敏捷开发强调的快速迭代,再到DevOps强调的持续交付,每一次方法论变革都是对开发效率瓶颈的回应。SDD的核心洞察在于:当代码生成的边际成本趋近于零时,工程师的核心价值不再是编写代码本身,而是精确定义"什么是正确的代码"。这与形式化方法(Formal Methods)领域数十年来追求的目标不谋而合,只不过AI的能力终于让这一愿景变得实用化。
具体来说,Codex要求开发者先编写好agents.md和Rules等规范文件,定义清楚目标、边界和验收标准,然后AI再基于这些规范生成代码。agents.md文件本质上是一份面向AI Agent的行为规范,它告诉AI"你是谁、你能做什么、你的边界在哪里",类似于传统软件开发中的需求规格说明书(SRS),但更加面向机器可读和可执行。这与之前随意用自然语言描述需求的方式有本质区别。
OpenAI内部也在实践这一理念。据其公开文章披露,三个人借助Harness Engineering方法论,在五到六个月内用AI生成了超过100万行代码,人工不写一行代码就完成了大型项目的上线。Harness Engineering是OpenAI内部实践并逐步对外推广的一套AI辅助工程方法论,其核心思想是将人类工程师的角色从"代码编写者"转变为"AI驾驭者"——工程师的主要职责变成了定义清晰的规范文档、设计验证策略、审查AI生成的代码质量,以及管理AI Agent的工作流程。按照这一数据推算,平均每人每天产出约3000行有效代码,远超传统开发中人均每天50-100行的行业平均水平,充分证明了规范工程的威力。
Agent循环机制模拟人类开发流程
Codex不再是简单的"输入需求→输出代码",而是通过Agent循环机制模拟人类工程师的完整开发过程。Agent循环(Agentic Loop)是当前AI Agent架构中的核心设计模式,区别于传统的单次推理(Single-shot Inference)。在单次推理模式下,用户输入一个提示,模型返回一个结果,交互就此结束。而Agent循环引入了"观察-思考-行动-反馈"的迭代闭环,这一思想的理论基础是Google和Princeton大学在2022年提出的ReAct(Reasoning + Acting)框架,如今已成为主流AI Agent的标准架构范式。
ReAct框架之所以成为AI Agent的标准范式,关键在于它解决了纯推理链(Chain-of-Thought)的两个致命缺陷:幻觉累积和信息封闭。纯推理链中,模型每一步都基于前一步的输出继续推理,错误会像滚雪球一样放大。而ReAct在推理链中插入了"行动"步骤——模型可以调用外部工具验证中间结论,获取实时信息来校正推理方向。在Codex的工程实践中,这意味着AI不会凭空"想象"一个API的参数签名,而是会实际查阅文档或执行类型检查来确认。
Codex的Agent循环具体分为四个阶段:
- 计划阶段:先制定详细的开发计划,包括任务分解、技术选型和实现路径
- 确认阶段:由人类工程师确认方案(支持确认模式和全自动模式,开发者可根据任务风险等级灵活选择)
- 执行阶段:将任务细化拆解到每个函数、每个模块,逐步生成代码并自动执行
- 审查阶段:结合上下文分析潜在bug、安全性问题和性能瓶颈,如果发现问题则自动回到执行阶段修正
正因为内部已经完成了完整的循环验证——AI生成代码后会自动运行、观察结果、分析错误、修正代码,如此迭代直到通过所有验证——用户最终看到的生成代码基本可以直接运行,不再像早期AI工具那样频繁报错。
上下文工程的深度优化
Codex在上下文管理上做了三项关键优化:
精简向量检索:不会把整个项目一股脑加载到模型中,而是根据当前任务语义匹配相关的代码片段和元数据,避免上下文溢出。这一设计背后的技术原理是RAG(检索增强生成):先将项目代码分块并转化为向量嵌入存储在向量数据库中,当用户提出任务时,系统通过语义相似度检索出最相关的代码片段,只将这些片段注入模型的上下文窗口。这样既保证了模型获得足够的信息,又避免了因上下文过长导致的注意力稀释和token浪费。
将RAG应用于代码检索比应用于自然语言文档面临更大的挑战。代码的语义高度依赖上下文:同一个变量名在不同文件中可能有完全不同的含义,一个函数的行为可能取决于数层调用栈之外的配置。因此,Codex的向量检索不能简单地将代码按固定长度分块,而需要感知语义边界——以函数、类或模块为单位进行分块,并在元数据中保留文件路径、命名空间、导入关系等结构化信息。此外,代码检索还需要处理多语言混合的情况,例如一个Web项目中TypeScript、Python和SQL可能存在跨语言的调用关系。
AST(抽象语法树)感知:抽象语法树是编译原理中的核心概念,它将源代码解析为一种树状数据结构,其中每个节点代表代码中的一个语法构造(如函数声明、条件语句、变量赋值等)。与简单的文本匹配不同,AST能够捕捉代码的语义结构——它知道哪个函数调用了哪个模块,哪个变量在哪个作用域中被引用。Codex通过AST感知分析模块间的依赖引用关系,在生成代码时自动追踪依赖图谱,确保import语句完整、函数签名匹配、类型系统一致,而非简单拼接代码文本。这从根本上解决了早期AI工具常见的编译报错、模块缺失等问题。
外部工具协同:Codex具备强大的环境交互能力,可以直接调用编译器、调试器、包管理器等工具。当代码报错时,它会自动读取日志、定位原因并完成修复,实现全自动的问题闭环处理。这种能力的实现依赖于MCP(Model Context Protocol,模型上下文协议)等标准化协议的支持。MCP是Anthropic于2024年底提出并开源的通信标准,为AI模型与外部工具之间建立了统一的JSON-RPC通信接口。Codex对MCP协议的支持意味着开发者可以通过编写MCP Server来扩展Codex的能力边界,例如连接企业内部的知识库、CI/CD流水线或监控系统,实现更深度的工程化集成。
MCP协议的出现解决了AI工具生态中长期存在的碎片化问题。在MCP之前,每个AI工具都需要为每个外部服务编写专用的集成代码,导致N个AI工具对接M个服务需要N×M个适配器。MCP将这一复杂度降低为N+M:工具侧只需实现MCP Client,服务侧只需实现MCP Server。这类似于USB协议对硬件生态的统一作用。目前MCP已获得包括OpenAI、Google、Microsoft在内的主要AI厂商支持,正在成为AI Agent与外部世界交互的事实标准。对企业开发者而言,这意味着投资MCP Server的开发将获得跨工具的复用价值。
学习资源与进阶路径
对于想深入学习Codex的开发者,推荐两个官方资源:
- OpenAI开发者文档:包含完整的API指南、概念解析和最佳实践
- Codex开源仓库:CLI源码、agents.md模板等核心文件都可以在这里找到
掌握Codex的关键不在于记住每个单独功能,而是要有全局整合思维——将多任务处理、规范工程、Agent循环、MCP协议等能力串联成完整的工作流,才能真正发挥它的最大价值。建议开发者从编写高质量的agents.md规范文件入手,这是驾驭Codex最核心的技能,也是从"提示词工程师"进阶为"AI工程架构师"的关键一步。
核心要点
核心要点
相关推荐
Claude Code实战指南:从安装配置到商业项目落地
详解Claude Code + Opus模型的完整配置流程,通过CCSwitch统一管理模型,实战演示4小时零手写代码完成支付系统二开,涵盖安装步骤、Prompt工程技巧与模型选择建议。

吴恩达联合Anthropic推出Claude Code权威教程深度解析
吴恩达与Anthropic工程师联合推出Claude Code系统课程,涵盖上下文管理、并行会话编排、MCP服务器集成等核心实践,通过RAG聊天机器人、数据分析、Figma设计转代码三大实战项目,全面提升AI辅助编程生产力。
T3 Stack创始人Theo自述:全栈类型安全工具诞生背后的懒人哲学
T3 Stack创始人Theo回顾频道起源,揭示Create T3 App诞生的真实动机:用最简抽象实现全栈类型安全,解决前后端类型断裂痛点。深度解读程序员三大美德如何驱动优秀开发工具的创新。