Whisper本地部署教程:手把手搭建免费语音转文字工具

OpenAI Whisper本地部署完整教程,从环境搭建到语音转文字实战。
本文详细介绍了OpenAI开源语音识别工具Whisper的本地部署全流程,包括安装Miniconda环境管理工具、创建独立Python环境、安装PyTorch和FFmpeg等核心依赖、选择合适的语音模型(推荐Turbo模型兼顾速度与精度),以及实际转录操作和批处理脚本简化使用。文章还涵盖了常见问题排查和卸载方法。
OpenAI Whisper 是目前最强大的开源语音识别工具之一,支持近百种语言的语音转文字,还能自动翻译成英文。不过由于它依赖 Python 环境且通过命令行操作,不少人在安装过程中频频踩坑。这篇教程将从环境搭建到实际使用,手把手带你完成 Whisper 的本地部署。
为什么选择 Whisper 做语音转文字?
Whistper 是 OpenAI 开源的自动语音识别(ASR)系统,基于大规模多语言数据训练而成。自动语音识别技术的发展经历了从基于规则的方法、隐马尔可夫模型(HMM)、深度神经网络到如今基于 Transformer 架构的端到端模型的演进。Whisper 采用的正是 Transformer 编码器-解码器架构,通过在 68 万小时的多语言标注音频数据上进行弱监督训练,使其具备了极强的泛化能力。与传统 ASR 系统需要针对特定语言或口音单独训练不同,Whisper 的多任务训练策略让它能够同时处理语音识别、语言检测、时间戳对齐和语音翻译等多项任务。
相比市面上的同类语音识别工具,它有几个显著优势:
- 支持近百种语言:包括普通话、广东话、日语、韩语等
- 识别精度极高:在多个基准测试中表现优异,实测几乎一字不差
- 内置翻译功能:可将其他语言自动翻译成英文
- 完全免费开源:无需付费,无调用次数限制
- 多格式输出:自动生成 SRT、VTT、TSV 等字幕文件及纯文本
不过,Whisper 的安装过程对新手并不友好——官方文档默认你已经具备 Python 环境配置经验,而这恰恰是大多数人卡住的地方。
第一步:安装 Conda 环境管理工具
为什么需要 Conda?
很多开源软件都依赖 Python 环境,但它们对 Python 版本和依赖包的要求各不相同。如果直接在系统中安装,不同软件之间很容易因为环境冲突而报错。
Conda 就是解决这个问题的利器——它能为每个软件创建独立的运行环境,类似于"虚拟机"的概念,让不同软件各自使用独立的 Python 版本和依赖包,互不干扰。Conda 是一个跨平台的包管理和环境管理系统,最初由 Anaconda 公司为 Python 数据科学生态开发。它的核心机制是通过创建彼此隔离的目录结构,每个环境拥有独立的 Python 解释器、标准库和第三方包。与 Python 自带的 venv 虚拟环境不同,Conda 不仅能管理 Python 包,还能管理 C/C++ 编译的二进制依赖(如 CUDA 工具包、MKL 数学库等),这对于深度学习项目尤为重要。环境之间的切换本质上是修改系统 PATH 变量的指向,使得命令行调用的 Python 和 pip 指向不同目录下的可执行文件。
下载与安装 Miniconda
Conda 有两个版本:Anaconda(体积庞大,包含大量科学计算包)和 Miniconda(轻量版,按需安装)。部署 Whisper 的话,Miniconda 完全够用。
前往 Miniconda 官网下载 Windows 版本安装包,双击运行后按以下步骤操作:
- 点击"下一步" → "我同意" → "下一步"
- 安装路径建议使用默认位置(约占 400MB 磁盘空间)
- 关键步骤:勾选"将 Conda 路径加入系统路径"选项,这样以后运行 Conda 时不受路径限制
- 点击"安装",等待完成即可
第二步:创建 Whisper 专属 Python 环境
Whistper 及其依赖项需要 5-6GB 磁盘空间,建议预留 10GB 以上,最好使用 SSD 以加快启动速度。
创建工作目录
在目标磁盘上新建一个名为 Whisper 的文件夹,打开后在地址栏输入 cmd 并回车,即可在当前目录打开命令窗口。
执行环境创建命令
依次执行以下操作:
# 将路径加入 Conda 配置(根据实际路径修改)
conda config --add envs_dirs D:\\\\Whisper
# 创建名为 whisper-env 的环境,安装 Python 3.11
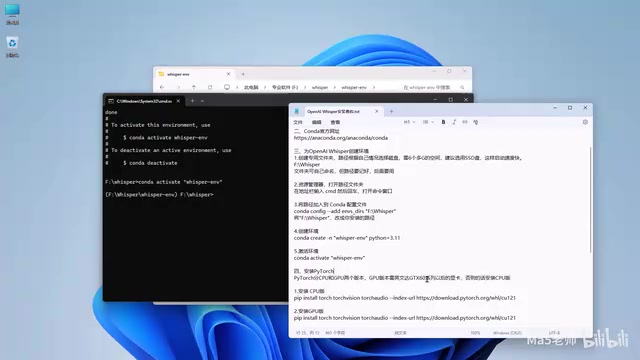
conda create -n whisper-env python=3.11
系统会列出需要安装的程序包,输入 Y 确认后开始下载安装。完成后,在 Whisper 文件夹内会出现 whisper-env 目录,里面就是独立的 Python 环境。
激活环境
conda activate whisper-env
激活成功后,命令行前面会出现 (whisper-env) 标识,表示后续所有操作都在这个隔离环境中进行。
第三步:安装 Whisper 核心依赖
安装 PyTorch 深度学习框架
PyTorch 是 Meta(原 Facebook)AI 研究院开发的开源机器学习框架,是目前学术界和工业界最主流的深度学习框架之一,与 Google 的 TensorFlow 并列。Whisper 的语音识别能力正是基于它构建的深度学习模型。
Whistper 的语音识别模型本质上是一个包含数百万到数十亿参数的神经网络,推理时需要进行大量的矩阵乘法和张量运算。PyTorch 分为 CPU 版和 GPU 版,GPU(图形处理器)拥有数千个计算核心,天然适合这类大规模并行计算任务,处理速度通常是 CPU 的 10-50 倍。GPU 版需要英伟达 GTX 6 系列及以后的显卡(如 GTX 650、RTX 3080 等)。如果显卡不支持,只能使用 CPU 版本,处理速度会慢不少。
NVIDIA 的 CUDA(Compute Unified Device Architecture)平台提供了 GPU 通用计算的编程接口,PyTorch 通过调用 CUDA 和 cuDNN 库来实现 GPU 加速。这也是为什么 GPU 版 PyTorch 要求必须使用 NVIDIA 显卡——AMD 和 Intel 显卡使用不同的计算架构,目前 PyTorch 对它们的支持仍处于实验阶段。
根据自己的硬件配置,从 PyTorch 官网获取对应的安装命令并执行。
安装 FFmpeg 多媒体处理工具
FFmpeg 是一个诞生于 2000 年的开源多媒体框架,几乎支持所有已知的音频和视频编解码格式,被广泛集成在 VLC、Chrome 浏览器、YouTube 后端等众多软件中。Whisper 之所以依赖 FFmpeg,是因为语音识别模型只能处理特定格式的原始音频波形数据(16kHz 采样率的单声道 PCM 浮点数据)。当用户输入 MP3、AAC、FLAC 等压缩音频或 MP4、MKV 等视频文件时,FFmpeg 负责将其解码、重采样并转换为模型可接受的格式。这个预处理过程对用户完全透明,使得 Whisper 能够直接处理几乎任何常见的音视频文件。
安装命令如下:
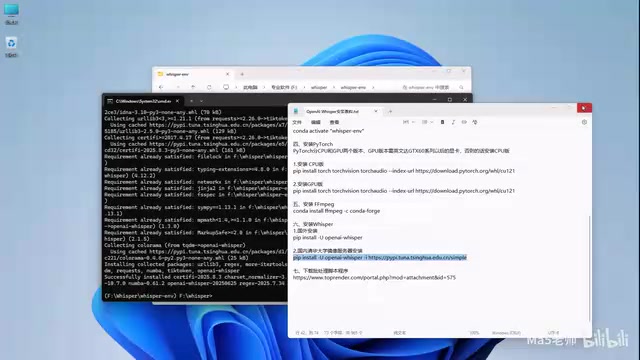
conda install ffmpeg
输入 Y 确认安装即可。
安装 OpenAI Whisper
国内用户建议使用清华大学镜像源来提高下载速度:
pip install openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
至此,Whisper 的所有组件安装完毕。
第四步:Whisper 模型选择指南
Whistper 提供了六种语言模型,选择合适的模型直接影响识别效果和处理速度。在深度学习中,模型的参数量直接决定了其"记忆容量"和表达能力——参数量越大,模型能够学习到的语音特征和语言规律就越丰富,对口音、噪音、专业术语的处理能力也越强,但代价是推理时需要更多的计算资源和显存。
| 模型 | 参数量 | 相对速度 | 显存需求 | 适用场景 |
|---|---|---|---|---|
| tiny(极小) | 3900万 | ~10x | ~1GB | 快速预览 |
| base(基本) | 7400万 | ~7x | ~1GB | 简单任务 |
| small(小) | 2.44亿 | ~4x | ~2GB | 日常使用 |
| medium(中) | 7.69亿 | ~2x | ~5GB | 高精度需求 |
| large(大) | 15.5亿 | 1x | ~10GB | 最高精度 |
| turbo(极速) | 8.09亿 | ~8x | ~6GB | 推荐首选 |
Turbo 模型比较特殊:它是 OpenAI 在 large-v3 基础上通过知识蒸馏技术优化而来——保留了大模型的解码器前两层,将剩余层数从 32 层压缩到 4 层,在几乎不损失识别精度的前提下将推理速度提升了约 8 倍,是工程优化的典型案例。不过 Turbo 模型不支持翻译功能。如果你只需要语音转文字而不需要翻译,强烈建议使用 Turbo。需要翻译功能时,选择 medium 或 large 模型。
注意:选择模型时,务必确认其显存需求不超过你显卡的显存容量。首次使用某个模型时,Whisper 会自动下载对应的模型文件(如 medium 模型约 1.42GB),需要耐心等待。
第五步:Whisper 语音转录实战操作
命令行基本用法
打开音频/视频所在文件夹的命令窗口,激活环境后执行:
# 基本转录(自动检测语言)
whisper 11.mp3 --model turbo
# 指定中文语言转录
whisper 11.mp3 --model turbo --language zh
# 翻译成英文(需使用 medium 或 large 模型)
whisper 11.mp3 --model medium --task translate
小贴士:手动指定语言(
--language参数)通常能提升识别准确率。这是因为 Whisper 在自动检测语言时,会先用音频的前 30 秒进行语言判断,如果这段音频恰好包含静音、背景音乐或多语言混杂的内容,可能导致语言检测错误,进而影响后续的识别效果。
转录完成后,Whisper 会在音频文件所在目录自动生成五个文件:
- SRT:最常用的字幕格式,包含时间轴。SRT(SubRip Subtitle)是全球最通用的字幕文件格式,由序号、时间码和文本三部分组成。Whisper 生成 SRT 文件的能力源于其模型架构中内置的时间戳预测机制——模型在解码文本的同时,会预测每个语音片段的起止时间,这种端到端的时间对齐方式比传统的先转文字再强制对齐的两步法更加自然准确。生成的 SRT 文件可以直接导入 Premiere Pro、DaVinci Resolve、剪映等视频编辑软件作为字幕轨道使用,也可以上传到 YouTube、Bilibili 等平台作为外挂字幕。
- VTT:Web 端常用字幕格式,HTML5 的
<video>标签原生支持 - TSV:制表符分隔的文本格式,方便导入 Excel 等表格工具进行分析
- TXT:纯文本内容,不含时间信息
- JSON:结构化数据格式,包含每个片段的详细置信度分数等元数据,适合程序化处理
用批处理脚本简化日常操作
每次都要手动激活环境、输入命令确实繁琐。可以用批处理脚本(.bat 文件)来简化流程——只需将音频文件拖放到脚本窗口,按提示选择模型和任务类型即可。
脚本的使用流程非常直观:
- 双击运行
whisper.bat - 将音频/视频文件拖入窗口并回车
- 选择语言模型(默认 Turbo)
- 选择任务类型:转录(原语言)或翻译(英文)
- 等待处理完成,结果自动保存到原文件目录
提示:如果从网上下载的 .bat 文件运行时提示"无法验证发布者",可以用记事本打开原文件,复制全部内容,新建文本文件粘贴后以 ANSI 编码另存为 .bat 文件即可解决。
卸载方法与常见问题排查
如果需要卸载 Whisper,操作非常简单:直接删除安装文件夹,再卸载 Conda 程序即可,不会在系统中留下残余文件。
常见问题及解决方案:
- 安装失败:检查网络连接,国内用户务必使用清华镜像源。如果 pip 安装过程中出现超时错误,可以尝试添加
--timeout 120参数延长超时时间 - 显存不足报错(常见错误信息:
CUDA out of memory):换用参数量更小的模型,或改用 CPU 版 PyTorch。也可以尝试在命令中添加--fp16 False参数,使用 32 位浮点精度代替 16 位,虽然会更慢但有时能绕过显存限制 - 识别不准确:尝试使用更大的模型,或通过
--language参数手动指定语言。如果音频中背景噪音较大,建议先用 Adobe Podcast 或 Audacity 等工具进行降噪预处理 - 处理速度太慢:确认是否正确安装了 GPU 版 PyTorch,可用
nvidia-smi命令检查显卡状态。如果该命令返回显卡信息但 Whisper 仍在使用 CPU,可能是 PyTorch 的 CUDA 版本与系统驱动不匹配,需要重新安装对应版本
Whistper 作为 OpenAI 开源的语音识别工具,在准确度和多语言支持方面确实是目前的天花板级别。虽然安装过程稍显复杂,但一次配置好之后就能长期使用,无需联网、无需付费,是内容创作者和字幕制作者的必备利器。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。