GPT-OSS开源模型本地部署教程:实测效果与显存占用分析
OpenAI开源GPT-OSS模型,MoE架构实现低成本本地部署与强推理能力。
OpenAI开源了基于MoE架构的GPT-OSS模型,提供20B和120B两个版本,分别接近O3-mini和O4-mini性能。20B版本推理仅激活3.6B参数,16GB显存即可本地运行。实测显示其在中文语义理解、逻辑推理等方面表现扎实,支持工具调用和结构化输出,通过Ollama可快速部署,适合企业私有化和AI Agent开发等场景。
OpenAI深夜突然开源了GPT-OSS模型,消息一出便在开发者社区引发了不小的震动。这款模型采用MoE(混合专家)架构,在保持强大能力的同时大幅压低了推理成本。本文将从部署到实测,完整记录GPT-OSS 20B版本在本地运行的真实表现。
模型架构与硬件需求
GPT-OSS模型目前提供两个版本,分别面向不同的硬件条件和性能需求:
- GPT-OSS 120B版本:采用MoE架构,推理时仅激活5.1B参数,性能接近O4-mini
- GPT-OSS 20B版本:同样采用MoE架构,推理时仅激活3.6B参数,性能接近O3-mini
MoE架构的核心原理
MoE(Mixture of Experts)架构是一种稀疏激活的神经网络设计范式,最早由Jacobs等人在1991年提出,近年来被Google的Switch Transformer和Mixtral等模型重新带入主流视野。其核心思想是将模型的前馈网络层(FFN层)拆分为多个独立的"专家"子网络,每次推理时通过一个门控网络(Gating Network)动态选择少量专家参与计算。
具体到GPT-OSS 20B,虽然模型拥有20B总参数分布在多个专家网络中,但每个token的推理只激活3.6B参数对应的专家组合。这意味着实际计算量(FLOPs)仅相当于一个3.6B稠密模型,而模型的知识容量和表达能力却远超同等计算量的稠密架构。这种"大容量、低计算"的特性正是MoE架构在推理效率上的根本优势——你获得了一个20B模型的知识储备,却只需要支付3.6B模型的计算成本。
GPT-OSS 20B版本只需要16GB显存即可在本地运行,一张消费级的RTX 4060 Ti 16GB就能胜任。120B版本自然需要更多显存,但考虑到其接近O4-mini的表现,整体性价比依然相当可观。
性能基准参考:O3-mini与O4-mini
O3-mini和O4-mini是OpenAI推出的推理优化系列模型,属于其"o系列"(reasoning系列)产品线。O3-mini以较低的计算成本提供了接近GPT-4级别的推理能力,特别擅长数学、编程和逻辑推理任务;O4-mini则是其迭代升级版本,在多步推理和复杂任务规划方面有进一步提升。将GPT-OSS与这两个模型对标,意味着开源社区首次获得了在本地硬件上运行接近OpenAI商业推理模型水平的能力,这对于需要数据隐私保护或离线运行的场景具有重大意义。
本地部署全流程
本次测试使用AutoDL平台租用了一张RTX 4090(24GB显存),整个部署过程非常简洁。
AutoDL是国内主流的GPU算力租赁平台之一,为开发者提供按需计费的GPU服务器实例。平台支持从RTX 3090到A100等多种GPU型号选择,用户可以按小时租用,避免了购买昂贵硬件的前期投入。对于大模型开发者而言,这类平台的价值在于可以快速验证模型部署方案——先在云端确认模型能正常运行并满足需求,再决定是否投资本地硬件。RTX 4090拥有24GB GDDR6X显存和超过80 TFLOPS的FP16算力,是当前消费级显卡中运行大模型的最佳选择之一。
第一步:安装Ollama
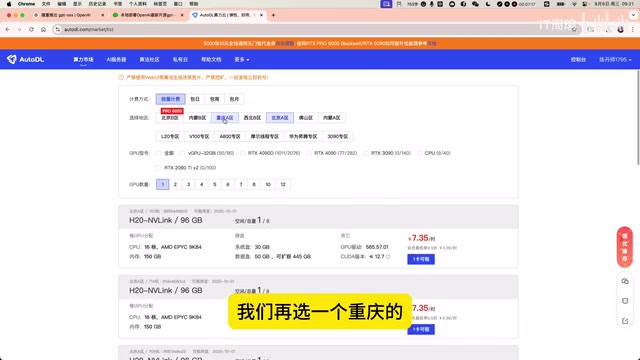
首先安装Ollama作为模型运行框架。Ollama是一个专为本地运行大语言模型设计的开源推理框架,它封装了llama.cpp等底层推理引擎,提供了类似Docker的模型管理体验。用户无需手动处理模型量化、内存映射、KV Cache管理等复杂细节,只需简单的pull和run命令即可完成模型部署。
Ollama支持GGUF格式的量化模型,内置了自动显存/内存分配策略,能够根据硬件条件自动选择GPU offload层数。其架构采用客户端-服务端模式,ollama serve启动的服务端提供REST API接口,兼容OpenAI API格式,这使得现有基于OpenAI SDK开发的应用可以几乎零成本迁移到本地模型。
进入GPU服务器终端后,执行Ollama的安装命令即可完成。安装过程中可能会出现一些Warning提示,只要不是Error就不影响正常使用。
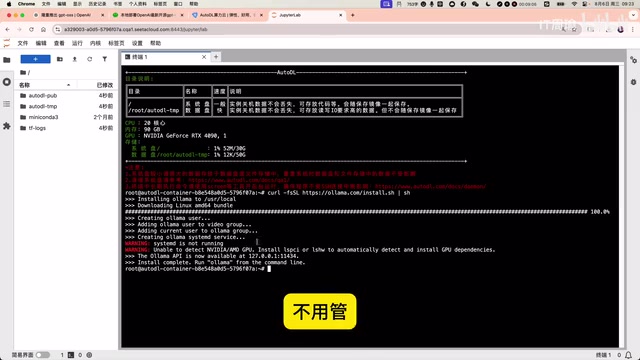
第二步:启动服务与下载模型
Ollama安装完成后,运行ollama serve命令启动服务端。然后新开一个终端窗口,使用命令直接拉取GPT-OSS 20B模型。模型文件大约13GB,下载需要等待一段时间。
整个GPT-OSS本地部署流程总结下来就三步:
- 安装Ollama
- 启动Ollama服务
- 拉取GPT-OSS模型
有Linux基础的开发者,整个过程不超过10分钟(不含模型下载时间)。
实际效果测试
模型部署完成后,分别从基础问答、中文语义理解、逻辑推理和创意生成四个维度进行了测试。
基础问答能力
首先测试了一个简单的时间感知问题——"今天是几月几号"。GPT-OSS的响应速度非常快,几乎是一闪而过,并且给出了正确的日期。基础知识和时间感知能力没有问题。
中文语义理解
接下来测试了一道有深度的中文理解题:"他背着老板做的这件事情"中的"背"是什么意思?
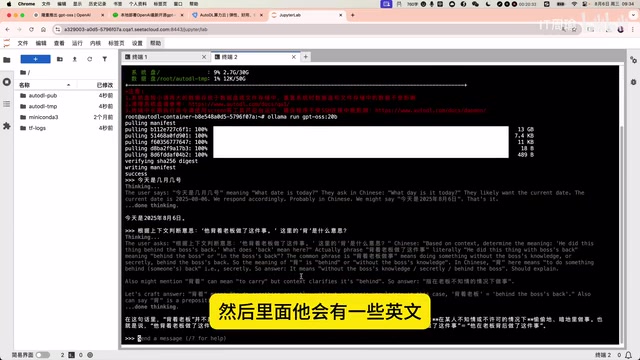
模型展现出了完整的推理过程(推理链中夹杂了一些英文),最终准确判断出这里的"背"并非字面意义上的"背负",而是指在老板不知情的情况下完成了某件事。GPT-OSS在中文多义词理解和语境推断方面的表现相当扎实。
逻辑推理能力
逻辑推理测试选用了经典的三段论变体:"如果所有A都是B,有些B是C,那么有些A一定是C吗?"
模型启动了推理过程,最终给出了正确答案——不一定,并附带了详细的解释和反例说明。这道题很容易让人掉入直觉陷阱(直觉会认为"有些A是C"成立,但实际上B中属于C的部分可能完全不与A重叠),GPT-OSS能够正确回答,说明其逻辑推理能力经过了充分训练。
思维链推理机制解析
上述测试中模型展示的推理过程,体现的正是思维链推理(Chain-of-Thought)机制。这一概念由Google Brain团队在2022年的论文中系统化提出,已被证明能显著提升模型在数学推理、逻辑判断和多步问题求解中的准确率。GPT-OSS内置的推理链机制意味着模型会在内部生成一系列思考步骤(有时对用户可见),然后基于这些中间推理得出最终结论。值得注意的是,推理链会增加输出token数量,但由于MoE架构的高效推理特性,整体延迟依然保持在可接受范围内。
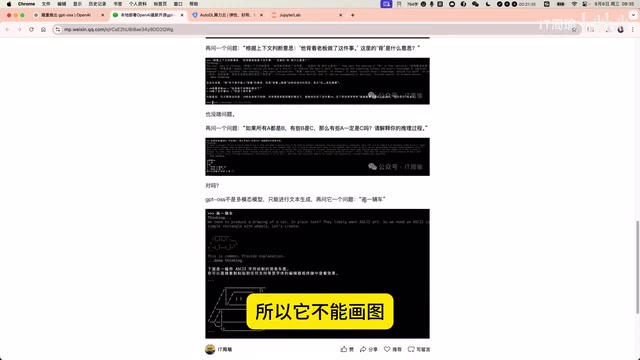
ASCII艺术生成
GPT-OSS并非多模态模型,不支持真正的图像生成。但当要求它"画一辆车"时,模型通过ASCII字符艺术的方式"画"出了一辆车,效果还挺有意思。
资源占用与性能分析
实测过程中,GPT-OSS 20B模型运行时的显存占用大约在15GB左右,没有超过16GB的门槛。这得益于Ollama框架本身的优化(包括高效的KV Cache管理和自动量化策略)以及MoE架构在推理时只激活部分参数的特性。
具体来看:
- 16GB显存的消费级显卡(如RTX 4060 Ti 16GB)确实可以流畅运行GPT-OSS 20B
- 推理速度极快,响应几乎是即时的
- 实际显存占用甚至略低于官方标称的16GB需求
对于手头没有高端显卡的开发者,这个显存门槛已经相当友好了。作为对比,同等能力的稠密模型(如Llama 3 8B的完整精度版本)往往需要更多显存才能达到类似的推理质量。
功能特性与应用场景
除了基础的对话能力,GPT-OSS还支持以下实用特性:
- 工具调用(Tool Use):支持函数调用,可以集成外部API和工具
- 结构化输出:能够按照指定格式输出JSON等结构化数据
- 思维链推理:内置推理过程,适合复杂问题求解
- 少样本学习:支持few-shot prompting,快速适应特定任务
工具调用与AI Agent生态
工具调用(Tool Use/Function Calling)是指大语言模型能够识别用户意图后,自主决定调用外部工具或API来完成任务的能力。这是构建AI Agent(智能体)的核心技术基础。一个典型的AI Agent工作流程是:接收用户指令→分析需要哪些工具→生成工具调用参数→执行工具→整合结果→返回给用户。
GPT-OSS支持这一能力意味着开发者可以基于它构建能够查询数据库、调用搜索引擎、执行代码、操作文件系统等复杂任务的自主智能体,而这一切都可以在本地私有环境中完成,无需将敏感数据发送到外部API。结合Ollama兼容OpenAI API格式的特性,现有的LangChain、CrewAI等Agent框架可以几乎无缝对接GPT-OSS。
这些能力让GPT-OSS在以下场景中具有很高的实用价值:
- 边缘设备部署:低显存需求使其可以在边缘计算设备上运行,适合工业物联网、智能零售终端等需要本地AI推理的场景
- AI Agent开发:工具调用和结构化输出能力非常适合构建AI智能体,可实现自动化工作流编排
- 企业私有化部署:开源许可让企业可以在内网环境中自主部署,数据不出域,满足金融、医疗、政务等行业的合规要求
- 快速原型验证:部署简单、推理快速,适合快速验证AI应用想法,降低从概念到原型的时间成本
总结
OpenAI此次开源的GPT-OSS模型,借助MoE架构实现了性能与效率的良好平衡。20B版本接近O3-mini的水平,120B版本则接近O4-mini,而硬件门槛却大幅降低。从实测结果来看,中文理解、逻辑推理、工具调用等核心能力都表现扎实,通过Ollama部署的流程也足够简便。
这一开源举措也标志着大模型领域的竞争格局正在发生变化——当OpenAI开始将接近其商业模型水平的能力以开源形式释放,整个行业的技术门槛将进一步降低,更多中小团队和独立开发者将有机会基于高质量模型构建创新应用。
如果你正在寻找一款可以在本地或私有环境中运行的高质量开源大模型,GPT-OSS值得一试。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。