GPT-OSS 120B本地部署实测:代码生成、推理能力全面对比O4 Mini
OpenAI发布GPT-OSS开放权重推理模型,实测表现中规中矩,与O4 Mini基本持平。
OpenAI正式发布GPT-OSS系列开放权重推理模型,提供120B和20B两个版本,主打Agent场景和工具调用能力。通过Ollama本地部署实测,120B版本在代码生成和逻辑推理方面与O4 Mini基本持平甚至略优,但联网搜索功能存在严重幻觉问题。模型采用"开放权重"而非真正开源,整体表现中规中矩,可能是为GPT-5发布预热的过渡产品。
OpenAI终于兑现了开源承诺,正式发布了GPT-OSS系列开放权重推理模型。官方宣称其性能可与O4 Mini相媲美,甚至能在手机上运行。但实际表现究竟如何?本文通过Ollama本地部署、代码生成、逻辑推理等多维度实测,带你看看GPT-OSS 120B的真实水平。
GPT-OSS模型概览:两个尺寸,主打Agent场景
GPT-OSS系列目前提供两个版本:120B(1200亿参数)和20B(200亿参数)。作为参考,GPT-3.5的参数量大约为1750亿,所以120B版本在参数规模上略小于GPT-3.5,但OpenAI声称通过更先进的训练方法实现了更强的性能。
值得注意的是,OpenAI此次采用的是"开放权重"(Open Weights)模式,而非严格意义上的"开源"。真正的开源要求公开训练数据、训练代码和完整的复现流程,而开放权重仅公开了训练好的模型参数文件,用户可以下载、部署和微调,但无法完整复现训练过程。Meta的LLaMA系列、Mistral等模型同样采用这种模式。开源倡议组织(OSI)在2024年发布的"开源AI"正式定义中明确要求公开训练数据和完整方法论,按此标准,目前绝大多数所谓的"开源模型"实际上只是"开放权重模型"。
20B版本专为移动设备设计,据称只需16GB运存即可运行。这呼应了今年3月OpenAI发起的一次社区投票——当时大量用户投票希望获得一个能在移动设备上运行的开源模型,GPT-OSS 20B正是这一需求的产物。
说个细节,OpenAI强调这个模型专为Agent场景准备,支持联网搜索和代码执行等工具调用能力。Agent(智能体)是2024-2025年AI领域最核心的发展方向之一,与传统的问答式AI不同,Agent能够自主规划任务、调用外部工具、执行多步骤操作。所谓"工具调用"(Tool Calling / Function Calling),是指模型能够识别用户意图后,生成结构化的函数调用指令,与外部API、搜索引擎、代码解释器等工具交互,再将结果整合后返回给用户。这要求模型在训练阶段就针对工具调用格式进行专门优化,能够准确判断何时需要调用工具、调用哪个工具、以及如何解析工具返回的结果。同时,模型经过了完整的安全训练和评估,即便部署在本地,对于危险请求(如制造武器等)仍会拒绝回答。
Ollama本地部署GPT-OSS 120B:一键搞定但有坑
本次测试使用的硬件是Mac Studio,配备96GB内存和M2 Max芯片。部署工具选择了目前最便捷的Ollama。
Ollama是目前最流行的本地大模型部署工具之一,它将模型下载、量化、推理引擎等复杂环节封装成了类似Docker的简洁命令行体验。用户只需一条命令(如 ollama run model_name)即可自动完成模型下载和启动。Ollama底层基于llama.cpp推理引擎,支持CPU和GPU混合推理,对Apple Silicon(M系列芯片)有良好的优化,能充分利用统一内存架构(Unified Memory)。文中使用的Mac Studio配备96GB统一内存,意味着CPU和GPU共享同一块内存池,60.8GB的模型可以完整加载到内存中,无需像传统PC那样受限于独立显卡的显存容量。这也是为什么Apple Silicon设备成为本地部署大模型的热门选择。
部署过程非常简单:下载安装Ollama后,选择想要部署的模型,发送一条消息即可自动开始下载和部署。GPT-OSS 120B版本的模型文件大小约为60.8GB,使用千兆宽带大约6-7分钟即可下载完毕。
关于这个文件大小,有一个技术细节值得说明:120B(1200亿参数)模型如果以全精度(FP32)存储,文件大小约为480GB;以半精度(FP16/BF16)存储也需要约240GB。而实际下载的60.8GB说明模型经过了量化处理——很可能是4-bit量化(Q4),即将每个参数从16位压缩到4位,体积缩小约4倍。量化是一种模型压缩技术,通过降低参数的数值精度来减少存储和计算需求,代价是可能带来轻微的性能损失。对于大多数应用场景,4-bit量化的性能损失在可接受范围内,这也是本地部署大模型的关键技术基础。
不过部署过程中有一个小坑:下载到90%以上时速度可能会急剧下降,看起来像是卡住了。这时建议停止下载,退出Ollama后重新启动再试。实测中尝试了四五次才最终完成部署。
如果你不想折腾本地部署,也可以使用OpenAI提供的云端版本,开启云端按钮后直接聊天即可,但需要付费使用。
代码生成能力实测:GPT-OSS 120B vs O4 Mini
贪吃蛇游戏生成对比
我们用经典的"写一个贪吃蛇小游戏"来测试代码生成能力。120B模型的生成速度比较流畅,与ChatGPT的体验接近。
GPT-OSS 120B生成的贪吃蛇:
- 支持上下左右控制
- 四面无墙壁设计
- 吃食物后速度递增
- 撞到身体后游戏结束
- 整体逻辑完整,可玩性尚可
O4 Mini生成的贪吃蛇:
- 同样支持基本操控
- 但视觉效果"晃眼",体验反而不如开源模型
单从这个测试来看,GPT-OSS 120B的代码生成质量与O4 Mini基本持平,甚至在某些细节上表现更好。
玻璃拟态落地页UI生成测试
接下来测试UI设计能力,要求模型生成一个玻璃拟态风格(Glassmorphism)的落地页。玻璃拟态是2020年前后兴起的一种UI设计风格,其核心特征包括半透明的磨砂玻璃效果(通过CSS的backdrop-filter: blur()实现)、多层叠加的透明度层次、鲜明的边框高光以及色彩丰富的背景。这种风格最早在苹果的macOS Big Sur和Windows 11的设计语言中被大规模采用。要在代码中实现玻璃拟态效果,需要综合运用CSS的background透明度、blur滤镜、border渐变、box-shadow等属性,对模型的前端代码生成能力是一个较好的综合测试。
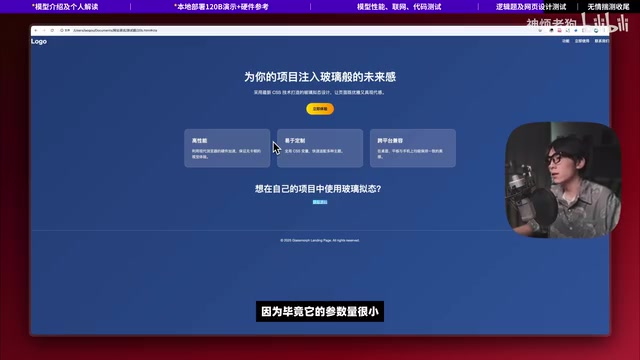
**GPT-OSS 20B的表现:**页面非常简单草率,生成时省略了大量代码,需要用户自行补充。考虑到其参数量小、上下文窗口短,这个结果勉强可以理解。
**GPT-OSS 120B的表现:**确实生成了玻璃拟态效果,包含核心功能区块、图标、动画效果,甚至还有邮箱输入框等交互元素。不过文字颜色选择有些奇怪(白色文字在浅色背景上),改成黑色会更合理。整体来说,120B版本展现了明显更强的UI理解和代码生成能力。
逻辑推理能力测试:经典水商人问题
我们用一道经典推理题来测试模型的思维链能力:
沙漠里一个卖水的商人有25公升水。一个人想买19公升,另一个人想买12公升。水不够同时卖给两人,只能选一个。卖水商只想赶快回家,而从皮囊里倒出一公斤水需要10秒。他应该卖给谁?
GPT-OSS 120B给出了正确答案:卖给要12公升的人。因为倒出12公升水只需120秒,而倒出19公升需要190秒,卖水商想尽快回家,自然应该选择耗时更短的交易。模型完整展示了推理过程,思维链清晰。
GPT-OSS作为"推理模型"(Reasoning Model),与普通的语言模型有本质区别。普通语言模型直接生成答案,而推理模型会先进行一段内部的"思考过程"(Chain-of-Thought),将复杂问题分解为多个推理步骤,逐步推导出最终答案。OpenAI的O系列模型(O1、O3、O4 Mini等)是这一技术路线的代表。推理模型通常通过强化学习(特别是基于过程奖励的强化学习)进行训练,让模型学会在回答前进行深度思考。这种方法在数学、编程、逻辑推理等需要多步骤思考的任务上效果显著,但代价是推理速度更慢、计算成本更高,因为模型需要生成额外的思考token。
不过推理过程是全英文输出的,这对中文用户来说不太友好。而O4 Mini在同一问题上出现了明显的质量下降,表现不如预期。
联网搜索功能:GPT-OSS的明显短板
测试中发现一个明显问题:当开启联网搜索功能时,模型会陷入长时间的搜索过程而迟迟不给出回复。更严重的是,即便搜索到了信息,模型仍然会"编造"内容。
例如,当被问及GPT-OSS模型本身的信息时,模型编造了"1.3B、7B、34B、70B"等根本不存在的版本号,还声称发布时间是"2024年年底"——截至2025年7月,这显然是错误的。
这种现象在AI领域被称为"幻觉"(Hallucination),是大语言模型的一个核心缺陷。幻觉是指模型生成看似合理但实际上不正确的信息,其根本原因在于语言模型的本质是基于概率的文本生成器——它预测的是"最可能出现的下一个token",而非"最正确的下一个token"。即便通过检索增强生成(RAG)技术引入外部知识源,模型仍可能忽略检索到的正确信息,转而依赖训练数据中的错误记忆或直接编造内容。这在模型被问及自身信息时尤为明显,因为训练数据截止日期之后发布的信息,模型只能依赖检索结果,而检索结果的整合质量高度依赖于适配层的实现质量。
说一下,联网搜索功能并非模型自带,而是Ollama平台提供的,因此这个问题更多是适配层面的,不能完全归咎于GPT-OSS模型本身。
总结:GPT-OSS 120B值得部署吗?
GPT-OSS 120B的整体表现可以用"中规中矩"来形容:
| 测试维度 | GPT-OSS 120B表现 | 与O4 Mini对比 |
|---|---|---|
| 代码生成 | 质量不错,逻辑完整 | 基本持平 |
| 逻辑推理 | 思维链清晰,答案正确 | 略优 |
| UI设计 | 120B有一定水准 | 各有千秋 |
| 联网搜索 | 适配问题多,易产生幻觉 | 明显不足 |
有一个有趣的猜测:这个开源模型是否是基于GPT-3.5和GPT-4融合而来的"开胃菜",为即将发布的GPT-5预热?毕竟有传言称GPT-5可能在近期发布,而OpenAI不太可能将真正的核心技术开源——GPT-5是他们的"底牌",开源出来的必然是有所保留的版本。
**部署建议:**如果你有足够的硬件配置(96GB以上内存),可以通过Ollama本地部署GPT-OSS 120B版本;配置一般的用户可以尝试20B版本或使用网上公开的云端服务。这个模型虽然没有达到"颠覆性"的水平,但作为OpenAI的首个开源推理模型,确实值得一试。
核心要点
- GPT-OSS提供120B和20B两个版本,20B可在手机上运行,仅需16GB运存
- 通过Ollama可一键本地部署,120B模型文件约60.8GB(经4-bit量化压缩),千兆宽带6-7分钟下载完成
- 代码生成能力与O4 Mini基本持平,贪吃蛇游戏测试中甚至表现更优
- 逻辑推理能力表现良好,思维链清晰,但联网搜索功能存在严重幻觉问题
- 模型采用"开放权重"而非严格意义上的开源,经过完整安全训练,即便本地部署也会拒绝危险请求,整体水平中规中矩
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。