GPT-OSS本地部署教程:Ollama一键运行OpenAI开源模型
OpenAI发布开放权重模型GPT-OSS,可通过Ollama在本地部署运行。
OpenAI发布了GPT-OSS开放权重模型系列,包含120B和20B两个版本。20B版本面向普通用户,16GB显存即可运行,性能接近O4 Mini。文章详细介绍了通过Ollama框架在本地部署的完整流程,实测显示模型在知识问答和代码生成方面表现良好,但复杂逻辑推理仍有不足。本地部署的核心优势在于数据隐私保护和离线使用能力。
OpenAI正式迈出了开源的重要一步,发布了名为GPT-OSS的开放权重模型系列。这意味着你可以在自己的电脑上运行接近ChatGPT水平的AI模型,无需依赖云端API,所有数据完全留在本地。
需要特别说明的是,这里的"开放权重"(Open Weights)与传统意义上的"开源"(Open Source)有所不同。传统开源要求公开源代码、训练数据、训练流程等全部内容,允许任何人自由修改和再分发。而"开放权重"仅公开模型训练完成后的参数权重文件,用户可以下载和运行模型,但通常不包含训练数据集和完整的训练代码。Meta的LLaMA系列、Mistral等模型也采用了类似策略。这种方式让OpenAI在保护核心训练技术和数据资产的同时,仍能让社区受益于模型本身的能力。
本文将详细介绍GPT-OSS模型的特点,并手把手教你通过Ollama在本地快速完成部署。
GPT-OSS模型介绍:两个版本怎么选
GPT-OSS系列是OpenAI推出的开放权重模型,专为推理、代理任务和多功能开发场景设计。该系列包含两个版本:
- GPT-OSS 120B:参数量1200亿,性能与OpenAI O4 Mini相当,但硬件要求极高,需要数据中心级算力支持,显存需大于80GB(如H100 GPU)
- GPT-OSS 20B:参数量200亿,面向普通用户,家用电脑即可运行,显存大于16GB即可部署
这里提到的O4 Mini是OpenAI于2025年推出的推理优化模型,属于O系列——一个专注于"思考"和推理的模型家族。与GPT-4o等通用模型不同,O系列模型在回答问题前会进行内部"思维链"推理,花费更多计算时间来分解和验证答案,因此在数学、编程和逻辑推理等任务上表现尤为突出。O4 Mini是该系列中的轻量版本,在保持较强推理能力的同时降低了计算成本。GPT-OSS能达到接近O4 Mini的水平,意味着开源社区首次获得了具备深度推理能力的可本地部署模型,这在此前是闭源模型的专属优势。
对于大多数个人用户来说,20B版本是更现实的选择。它在保持不错推理能力的同时,将硬件门槛降到了消费级显卡可以承受的范围。实测数据显示,20B模型运行时内存占用约10GB,显存占用约14.5GB,一张16GB显存的显卡即可流畅运行。
关于参数量与实际资源占用的关系,这里值得做一些解释。参数量(Parameters)是衡量神经网络复杂度的核心指标,每个参数本质上是一个浮点数权重值,参与模型的推理计算。一般来说,参数量越大,模型能够学习和表达的知识模式就越丰富,但同时对计算资源的需求也呈线性甚至超线性增长。以20B模型为例,若使用FP16(半精度浮点数)存储,每个参数占2字节,200亿参数约需40GB存储空间;但通过量化技术(如INT4量化,将每个参数压缩到4位),可以将模型体积缩小到约10GB左右,这也解释了为什么20B模型能在16GB显存的消费级显卡上运行。
部署前的准备工作
软件环境要求
本地部署GPT-OSS需要准备两个软件:
- Ollama:开源的本地大模型运行框架,支持Windows、macOS和Linux三大平台。前往Ollama官网下载对应系统的安装包即可。
- Python 3.12:部分扩展功能依赖Python环境,建议下载64位Windows版本。
Ollama是当前最流行的本地大模型运行框架之一,它的核心价值在于极大简化了大语言模型的部署流程。在Ollama出现之前,本地运行大模型需要手动配置CUDA驱动、安装PyTorch、下载模型权重、编写推理脚本等一系列复杂步骤。Ollama将这些流程封装成类似Docker的体验——用户只需一条命令即可完成模型的下载、量化适配和推理服务启动。底层上,Ollama基于llama.cpp项目构建,后者是由Georgi Gerganov开发的纯C/C++大模型推理引擎,支持CPU和GPU混合推理,并内置了多种量化方案(GGUF格式)。Ollama在此基础上增加了模型仓库管理、API服务、多模型切换等功能,形成了完整的本地AI运行平台。
Ollama与Python安装步骤
安装过程非常简单,几分钟就能搞定:
- 安装Python:运行安装程序时,务必勾选「Add Python to PATH」和「Install for all users」两个选项,然后点击安装
- 安装Ollama:双击安装包,点击安装按钮,等待完成即可
安装完成后,打开命令提示符(CMD),输入 ollama 命令验证是否安装成功。如果出现帮助信息,说明Ollama已正确安装。
GPT-OSS模型下载与运行
下载GPT-OSS模型
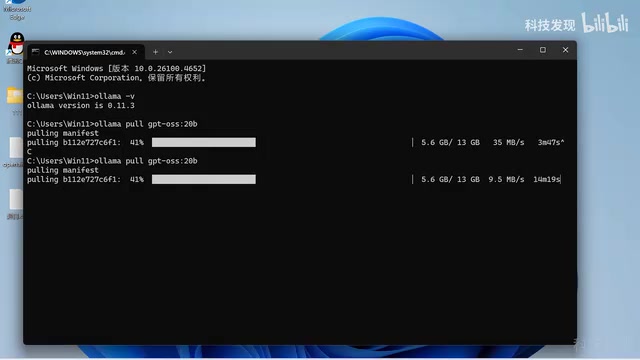
在命令提示符中,根据自己的硬件配置选择对应的下载命令:
- 20B版本(显存≥16GB):使用对应的
ollama pull命令 - 120B版本(显存≥80GB):使用对应的
ollama pull命令
模型文件较大,下载需要一定时间。这里分享一个实用技巧:下载过程中如果速度变慢,可以按 Ctrl+C 终止,然后重新执行下载命令。Ollama支持断点续传,不会从头开始下载,重新连接后速度通常会恢复正常。
启动并运行模型
模型下载完成后,通过 ollama run 命令即可启动。启动成功后,你可以直接在命令行中输入问题进行对话。
Ollama也提供了图形化界面,可以在界面中选择已下载的模型进行交互,操作体验更加友好。
GPT-OSS 20B实际效果测试
知识问答测试
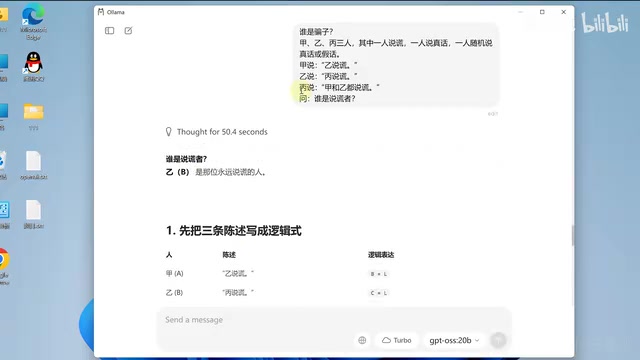
实测中,GPT-OSS 20B在多个问答场景下表现良好。对于常识性问题和逻辑推理题,模型大部分能给出正确答案。
不过在一道经典的逻辑推理题(判断谁在说谎)中,模型给出了错误答案——正确答案应该是「丙说谎」。这说明20B版本在复杂逻辑推理上仍有提升空间。
代码生成测试
让模型编写一个小游戏的代码,GPT-OSS 20B成功生成了可运行的游戏程序。将生成的代码保存为对应格式的文件后,游戏可以正常运行,按空格键即可重新开始。这表明该模型在代码生成方面具备实用价值。
联网功能说明
默认情况下,GPT-OSS通过Ollama运行是完全本地化的,不需要联网。如果需要联网获取实时信息,可以在Ollama界面中登录账号开启联网功能。没有账号的用户可以免费注册。
硬件配置建议与适用场景
硬件配置推荐
| 配置等级 | 显卡要求 | 适用模型 |
|---|---|---|
| 最低配置 | 16GB显存(如RTX 4060 Ti 16GB、RTX 4080) | GPT-OSS 20B |
| 推荐配置 | 24GB显存(如RTX 4090) | GPT-OSS 20B(更流畅) |
| 专业场景 | 80GB+显存(如H100) | GPT-OSS 120B |
理解这张配置表背后的逻辑有助于做出更明智的选择。大模型推理时,显存(VRAM)的占用主要来自三部分:模型权重本身、KV Cache(键值缓存,用于存储注意力机制的中间状态)以及激活值。其中KV Cache的大小与上下文长度成正比——对话越长,显存占用越高。这就是为什么即使模型权重只占14.5GB,仍建议使用16GB甚至24GB显存的显卡,因为需要为KV Cache预留空间。此外,如果显存不足,Ollama会自动将部分层卸载到系统内存(RAM)中进行CPU计算,这就是所谓的"CPU offloading",虽然模型仍能运行,但推理速度会显著下降。RTX 4090的24GB显存之所以被列为"推荐配置",正是因为它能将整个模型完全加载到GPU中,避免CPU offloading带来的性能损失。
适用场景
- 数据隐私保护:不希望数据上传云端的用户
- 离线AI使用:无网络环境下仍需AI能力的场景
- 开发测试:开发者进行本地原型验证和调试
- 学习体验:AI爱好者学习和体验大模型运行原理
在数据隐私保护方面,本地部署的优势在当前数据安全法规日趋严格的背景下尤为重要。使用云端API(如OpenAI API、Claude API)时,用户的输入数据需要通过网络传输到服务商的服务器进行处理,尽管主流服务商承诺不会使用API数据进行训练,但数据在传输和处理过程中仍存在被截获或泄露的理论风险。对于涉及医疗记录、法律文件、商业机密等敏感信息的场景,许多企业的合规要求明确禁止将数据传输到第三方服务器。本地部署则完全消除了这一顾虑——所有数据的处理都在用户自己的硬件上完成,不经过任何外部网络,这也是金融、医疗、政府等行业对本地AI部署需求持续增长的核心驱动力。
总结
OpenAI此次开源GPT-OSS系列,标志着顶级AI实验室在开源路线上的重要突破。虽然20B版本在复杂推理上与闭源模型仍有差距,但对于日常使用和开发测试来说已经足够实用。
通过Ollama部署的方式极大降低了使用门槛,即使没有技术背景的用户也能在几分钟内完成部署。随着开源生态的持续发展,本地AI的能力和易用性还将不断提升。如果你手头有一张16GB以上显存的显卡,不妨现在就试试。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。