OpenCode实战:零代码搭建YOLOv8目标检测全自动流水线
借助OpenCode Skill,用自然语言即可跑通YOLOv8全流程目标检测。
文章介绍了通过OpenCode的Skill机制,以自然语言指令驱动YOLOv8目标检测全流程的实战案例。整个流水线涵盖摄像头录制30秒视频、利用VLM和FastSAM自动抽帧标注、基于迁移学习微调YOLOv8模型、以及实时检测验证四个步骤,全程零代码,总耗时约两小时,最终识别置信度可达0.99以上。该方案体现了"人定目标、AI做执行"的协作理念,大幅降低了目标检测的技术门槛。
让AI帮你跑通YOLO全流程,到底有多简单?
想入门目标检测的同学大概都经历过这样的痛苦:YOLOv8的完整流程——数据采集、标注、训练、推理——每一步都要写不少代码,踩不少坑。光是手动标注几百张图片,就能劝退一大批人。
现在有了一种更省力的方式:借助OpenCode的Skill模型,用自然语言下指令,就能跑通从摄像头录制视频到模型训练再到实时检测的完整闭环,全程不用手写一行代码。
本文记录的就是这样一个实战案例——用OpenCode构建一个YOLO Skill,实现"录制30秒视频→自动抽帧标注→模型训练→实时识别"的全自动流水线。
YOLO技术背景:YOLO(You Only Look Once)是目标检测领域最具影响力的算法家族之一,由Joseph Redmon于2015年首次提出。与传统的两阶段检测器(如R-CNN系列)不同,YOLO将目标检测视为单一回归问题,在一次前向传播中同时预测边界框和类别概率,因此得名"只看一次"。YOLOv8是由Ultralytics于2023年发布的最新主干版本,在架构上引入了无锚点(Anchor-Free)检测头、C2f模块等创新,在速度与精度之间取得了更好的平衡,成为当前工业界和研究界最广泛使用的目标检测框架之一。
核心思路:你定方向,AI负责执行
YOLO Skill是什么?
Skill(技能)是OpenCode里的一个核心概念,简单说就是把一系列复杂操作封装成可复用的技能模块。OpenCode的Skill机制本质上是AI Agent(智能体)架构的一种实现形式——AI Agent是能够感知环境、规划步骤、调用工具并执行任务的自主AI系统,与传统的单次问答式AI有本质区别。Skill将多步骤操作封装为可复用的原子能力单元,Agent在接收到自然语言指令后,会自动编排这些Skill的调用顺序,处理中间状态和异常情况。
在这个案例中,YOLO Skill把以下四个步骤打包成了一条自动化流水线:
- 视频录制:调用摄像头录制30秒目标视频
- 自动抽帧与标注:用视觉语言模型(VL模型)对视频帧进行自动标注
- YOLOv8模型训练:基于标注数据自动完成模型微调
- 实时检测验证:加载训练好的模型,对摄像头画面做实时目标识别
一个关键理念
这里有一条很重要的思维逻辑:不是让AI左右我们,而是以我们为主导。AI并不知道你要做什么产品、识别什么目标,你需要自己想清楚方向,然后让AI去搞定具体的技术实现。这种"人定目标,AI做执行"的协作模式,才是当前AI工具的正确打开方式。
YOLOv8全自动流水线实战步骤
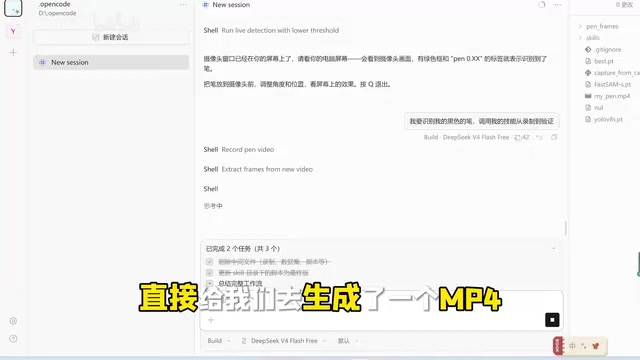
第一步:环境准备与视频录制
打开OpenCode,用自然语言发一条指令,系统就会自动调用摄像头开始录制。演示中生成了一个mypain.mp4文件,这就是后续所有处理的原始数据。
你需要准备的东西非常简单:
- 一台带摄像头的电脑
- 安装好的OpenCode环境
- 需要识别的目标物体(演示中用的是一支笔)
录制时间只要30秒,数据采集的门槛被压到了极低。
第二步:自动抽帧与智能标注
这一步是整个流程中省时间最多的环节。传统做法里,手动标注几百张图片动辄几小时甚至几天;而OpenCode会自动把视频拆成帧图片,再调用视觉语言模型对每一帧做自动标注,整个过程压缩到几分钟。
视觉语言模型(VLM)与自动标注的原理:视觉语言模型是能够同时理解图像和文本的多模态大模型,代表性产品包括GPT-4V、LLaVA、Qwen-VL等。在自动标注场景中,VLM可以根据文字描述(如"笔")在图像中定位目标区域,生成边界框坐标,从而替代人工标注。FastSAM(Fast Segment Anything Model)则是Meta SAM模型的轻量化版本,能够在毫秒级时间内完成图像中任意目标的分割掩码生成。两者结合,构成了"VLM定位+FastSAM精割"的自动标注流水线,将原本需要数小时的人工标注压缩至分钟级别。
系统用到的关键技术包括:
- FastSAM:负责快速图像分割和目标标注
- YOLOv8预训练模型(yolov8.pt):作为基础模型进行微调训练
第三步:自动训练YOLOv8模型
标注数据准备好后,系统自动启动YOLOv8的训练流程。这里的训练本质上是**迁移学习(Transfer Learning)**的应用:预训练的yolov8.pt模型已在COCO等大规模数据集上学习了丰富的视觉特征,微调(Fine-tuning)时只需在此基础上用少量领域数据调整模型参数,即可快速适配新的检测目标。这也是为什么仅凭30秒视频抽取的有限帧数,就能训练出高置信度模型的原因——预训练权重提供了强大的特征提取能力,微调阶段只需教会模型识别新目标的外观特征。
训练完成后会生成best.pt模型文件。根据作者实测,从录制视频到训练结束,整个过程大约耗时两小时。
第四步:实时目标检测验证
加载训练好的best.pt模型,系统就能对摄像头画面做实时检测。演示中对笔的识别置信度达到了0.99到1.0,效果相当扎实。
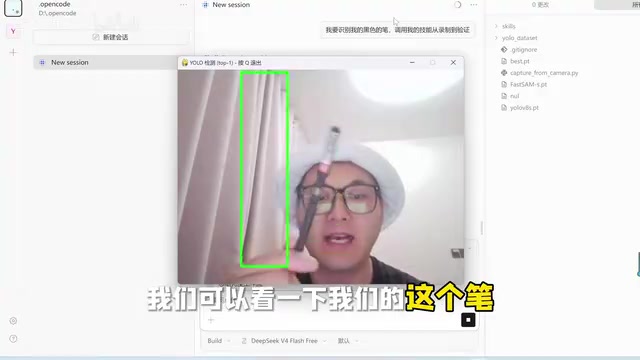
这套方案的技术亮点在哪?
真正的零代码目标检测
整个流程完全由自然语言驱动,不需要写任何代码。哪怕完全不懂编程的用户,也能独立完成一个完整的YOLOv8目标检测项目。
Skill封装带来的高复用性
作者把整套流程封装成了一个Skill,后续可以一键调用、反复使用。想换一个识别目标?重新录30秒视频就行,剩下的流程全部自动跑完。这种架构使得复杂的机器学习工程流程得以被抽象为高层语义指令,是当前LLM落地工程实践的重要范式之一。
从手动配置到自然语言指令的演进
回想YOLOv8刚发布的时候,开发者要自己搞定数据集整理、YAML配置文件编写、训练脚本调试等一堆琐碎工作。而现在通过Skill模型的封装,这些操作被抽象成了一条自然语言指令。这不只是效率提升,更代表了AI工具链的一个重要演进方向。
总结:AI正在成为帮我们训练AI的工具
这个案例揭示了一个值得关注的趋势:AI不仅是被训练的对象,它本身也在成为帮助我们训练AI的工具。通过OpenCode的Skill机制,原本复杂的机器学习流水线被简化为自然语言交互,技术门槛大幅降低。
如果你想动手试试,这里有几条建议:
- 先搞清楚整个流程的逻辑,理解每一步在做什么
- 从简单的单目标识别开始练手
- 熟悉之后再逐步挑战多目标、复杂场景的应用
未来,这种"自然语言驱动的AI开发"模式很可能会成为主流,让更多没有技术背景的人也能构建属于自己的AI应用。
核心要点
- 通过OpenCode的Skill模型,可以用自然语言实现YOLOv8从数据采集到实时检测的全自动闭环
- 整个流程仅需录制30秒视频,系统自动完成抽帧、标注、训练和验证,总耗时约两小时
- 利用FastSAM和VL模型实现自动标注,大幅降低了传统手动标注的时间成本
- YOLOv8训练本质是迁移学习,预训练权重使少量数据即可达到高精度
- 训练后的模型对目标物体识别置信度可达0.99-1.0,效果优秀
- 核心理念是以人为主导确定方向,让AI执行具体技术实现,而非被AI左右
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。