OpenHuman深度评测:15000星桌面AI助手的创新亮点与隐私隐患
一个迪拜独立开发者的爆款开源项目
一个来自迪拜的独立开发者,三个月内提交了800多次代码,做出了一款名为OpenHuman的桌面AI助手。这个项目在GitHub上迅速积累了15000颗星,还冲上了Product Hunt日榜冠军。但有趣的是,创始人在Hacker News上自己发的两条帖子加起来只有五分,几乎无人讨论。
Product Hunt和Hacker News代表了科技生态中两种截然不同的评价体系。Product Hunt的用户群体以产品经理、创业者和早期采用者为主,他们更关注产品的视觉呈现、用户体验和商业潜力,投票行为也更容易受到社交传播的影响。Hacker News则由工程师和技术决策者主导,社区文化强调技术深度和批判性思维,对营销包装有天然的抵触情绪。一个产品在Product Hunt爆火但在Hacker News遇冷,通常意味着它在"感知价值"上做得很好,但在"技术可信度"上还未获得认可。历史上类似的案例不少——许多在Product Hunt上获得数千票的产品最终未能存活,而一些在Hacker News上引发深度讨论的项目(如SQLite、Redis)反而成为了基础设施级别的存在。
这种"墙外开花墙内香"的反差,恰恰反映了当前AI产品赛道的一个现实:技术社区的冷静与大众市场的热情之间,存在着巨大的温差。



OpenHuman核心设计:给AI安一张脸
拟人化交互体验
OpenHuman最显眼的设计是给AI安了一张脸——桌面上有个黄色生物,会动、会说话、能开口跟你聊天。更激进的是,它能作为"真人参会者"加入你的Google Meet会议,全程旁听并记笔记。这是同类桌面AI助手里第一个这么干的。
合成语音加口型同步(Lip Sync)的技术方案,让这个黄色生物不再是冷冰冰的对话框,而是一个有"存在感"的桌面伙伴。这项技术近年来因深度学习的进步而日趋成熟——传统方案依赖音素到视素(Viseme)的映射表,即将语音中的基本发音单元(如/p/、/a/)对应到嘴型的基本形状(如闭唇、张嘴),这种方法规则明确但效果生硬。而现代方案如Wav2Lip等模型可以直接从音频波形预测面部关键点运动,通过在大量真人说话视频上训练,学会了音频与面部肌肉运动之间的复杂映射关系。MIT媒体实验室的研究表明,具有面部表情的AI代理能显著提升用户的情感投入度和信息留存率——相比纯文本交互,具身化AI的用户留存率可提升40%以上。这也是为什么越来越多的AI产品开始从纯文本界面转向具身化交互。OpenHuman选择在桌面端实现这一效果,意味着需要在本地进行实时推理或使用预渲染动画帧的折中方案——前者对GPU有要求,后者则牺牲了表情的自然度。从实际体验来看,OpenHuman更可能采用的是有限动画帧集合加规则触发的轻量方案,而非完整的实时面部生成。
数据整合与透明记忆树
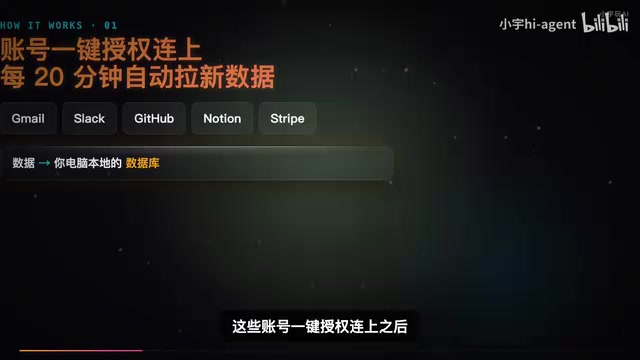
OpenHuman的运行机制分三层:
- 数据接入:Gmail、Slack、GitHub、Notion等账号一键授权,每隔20分钟自动拉取新数据到本地数据库
- 数据处理:所有数据压缩成纯文本片段,每段不超过3000 Token,按数据源、人物项目、日期建立三种层级摘要
- 透明记忆:记忆树不是黑盒,所有数据切碎后落到本地Markdown文件夹,用户可以直接打开查看AI到底知道你什么,能改能删
这里需要解释一下Token的概念及其重要性。Token是大语言模型处理文本的基本单位,它既不完全等同于单词,也不等同于字符——英文中大约每个单词对应1-1.5个Token(常见词如"the"是1个Token,而"indistinguishable"可能被拆成3-4个Token),中文每个字约1.5-2个Token。当前主流模型如GPT-4o的上下文窗口为128K Token,Claude的为200K Token,但更长的上下文意味着更高的API调用成本和更慢的响应速度。以GPT-4o为例,输入Token的价格约为每百万Token 2.5美元,如果每次调用都填满128K窗口,单次成本就接近0.32美元——对于一个每20分钟同步一次数据的助手来说,这个成本会迅速累积。因此,将每段数据控制在3000 Token以内,配合分层摘要的检索策略(即RAG——检索增强生成),是在成本和效果之间取得平衡的工程选择。分层摘要的核心思想是:日常对话只需加载最相关的几个片段(可能总共不超过1万Token),只有在用户明确追问细节时才逐层展开更多上下文。
这个"可打开、可编辑"的记忆设计,比一般AI助手的记忆栏透明很多,模仿成本不高,但确实是杀手锏级的用户体验设计。
必须戳破的宣传泡沫
"本地优先"隐私承诺名不副实
OpenHuman主推"本地优先"和"隐私可控",但真正本地的只有数据库和Markdown文件夹。关键问题在于:
- 授权令牌存储在他们的后端
- 所有大模型调用走他们的后端
- 连网页搜索都走他们的后端代理
这里的核心风险在于OAuth令牌的存储位置。OAuth 2.0是当前互联网服务间授权的标准协议,几乎所有主流SaaS产品都支持它。当用户授权OpenHuman访问Gmail时,Google会颁发一个Access Token(短期有效,通常1小时过期)和一个Refresh Token(长期有效,可能数月甚至永久有效)。Access Token就像一张临时门禁卡,过期就失效;而Refresh Token则像一把能无限复制门禁卡的母钥匙。持有Refresh Token的一方可以在用户不知情的情况下持续获取新的Access Token,从而长期访问用户数据。如果令牌存在用户本地,即使开发团队的服务器被攻破,用户数据也不会泄露;但如果令牌存在开发者的后端——正如OpenHuman目前的做法——那么一次数据泄露事件就可能影响所有用户。这不是理论风险:2023年微软就曾因一个工程师的失误导致内部OAuth密钥泄露,引发了严重的安全事件。对于一个需要同时持有用户Gmail、Slack、GitHub、Stripe等多个服务Refresh Token的应用来说,其后端数据库本质上就是一个高价值攻击目标。
换句话说,你连接的Gmail、Slack、GitHub、Stripe的权限钥匙,全部掌握在一个成立仅三个月的创业团队手里。对于注重数据安全的用户来说,这是一个不可忽视的风险点。
技术实现的"借力"痕迹
深入代码和文档后,还能发现几个不大不小的瑕疵:
- 号称118个集成,实际基于Composio这个第三方平台,源码注释里直接写明
- 所谓"压缩功能能省80% Token",文档里自己承认是从别人的GitHub项目搬过来的,第三方实测最多省70%
- 五天实测中出现了两次同步失败
关于Composio,这是一个专门为AI Agent提供第三方工具集成的开源平台,由印度团队开发并获得了数百万美元融资。它将Gmail、Slack、GitHub、Notion等数百个SaaS服务的API封装成标准化的工具调用接口,让开发者无需逐一对接各平台的OAuth认证流程和API规范。传统做法中,对接一个第三方服务可能需要1-2周的开发时间(阅读文档、处理认证、适配数据格式、处理错误),而通过Composio只需几行代码即可完成。这种"集成即服务"的模式大幅降低了开发门槛,但也引入了额外的依赖层——如果Composio服务中断或变更API,依赖它的应用也会受到影响。更重要的是,这意味着OpenHuman的"118个集成"并非自研能力,而是站在Composio的肩膀上。这本身不是问题——现代软件开发本就建立在层层抽象之上——但宣传时不提这一点,就有误导之嫌。OpenHuman的核心竞争力不在于集成能力本身,而在于上层的交互设计和记忆管理。
至于Token压缩技术,常见方案包括摘要压缩(将长文本先用小模型如GPT-3.5生成摘要,再将摘要而非原文送入主模型)、语义去重(通过向量相似度检测删除重复或高度相似的信息片段)、以及分层检索(建立摘要索引树,只在需要时加载相关的原始片段)。更前沿的方案还包括LLMLingua等专门的Prompt压缩模型,它们通过计算每个Token的困惑度(Perplexity)来判断哪些Token可以安全删除而不影响语义。声称的80%压缩率如果属实,意味着原本需要10万Token的上下文可以压缩到2万Token以内,这将大幅降低API成本——以GPT-4o的定价计算,每次调用可节省约0.2美元。但第三方实测最多70%的结果,说明在真实场景中信息密度较高的文本(如代码、数据表格、法律条款)很难达到理想压缩比,因为这类文本中几乎每个Token都承载着不可省略的语义信息。
这些并不是致命缺陷,但与宣传口径之间的差距值得警惕。
对AI从业者的启示
技术架构值得学习
对于工程师而言,OpenHuman采用的Tauri + Rust + 内嵌核心这套架构,是做桌面AI产品的一个优秀参考方案。
Tauri是2022年发布1.0版本的新一代跨平台桌面应用框架,它是Electron的直接竞争者。Electron由GitHub开发(现归属微软),VS Code、Slack桌面版、Discord、Figma桌面版等知名应用都基于它构建,它的优势在于让Web开发者可以直接用HTML/CSS/JavaScript构建桌面应用,但其致命缺点是资源占用——每个Electron应用都内嵌一个完整的Chromium浏览器引擎和Node.js运行时,导致一个简单应用也可能占用200MB以上内存,安装包动辄100MB起步。Tauri则使用操作系统自带的WebView(macOS上是WebKit,Windows上是WebView2/Edge)渲染前端界面,后端逻辑用Rust编写,使得应用的安装包通常只有Electron的1/10大小(一个基础应用可以做到3-5MB),内存占用也大幅降低。对于需要常驻后台的桌面AI助手来说,轻量化尤为重要——用户不会接受一个"助手"占用1GB内存,尤其当它需要7×24小时运行并每20分钟执行一次数据同步时。Rust则在保证接近C/C++性能的同时,通过所有权(Ownership)系统和借用检查器(Borrow Checker)从编译期杜绝内存安全问题(如空指针、数据竞争、缓冲区溢出),非常适合处理敏感数据的场景。值得注意的是,Tauri 2.0已于2024年发布,新增了对iOS和Android的支持,这意味着基于Tauri构建的应用未来可以相对容易地扩展到移动端。
产品设计值得借鉴
对于AI产品创业者,"把记忆做成能打开看"这个设计思路极具价值。在用户对AI信任度普遍不高的当下,透明化是建立信任的最短路径。这一设计理念与"可解释AI"(Explainable AI, XAI)的学术方向不谋而合——当用户能够理解AI为什么做出某个决策、它基于什么信息得出结论时,用户的信任度和使用意愿都会显著提升。OpenHuman将这一理念落地为极其朴素的形式——本地Markdown文件夹——反而比复杂的可视化仪表盘更有说服力,因为Markdown文件是用户完全可控的:可以用任何文本编辑器打开、搜索、修改、删除,甚至可以用Git进行版本管理。
但现在不是上车的时候
综合来看,OpenHuman是一个值得跟踪的样本,而非值得现在投入使用的生产工具。权限集中风险、同步稳定性问题、以及团队的早期阶段,都意味着它还需要时间证明自己。
桌面AI助手赛道展望
桌面AI助手这个赛道,接下来一年是关键期。从OpenHuman的案例中可以看到几个趋势:
- 拟人化交互将成为差异化竞争的重要维度
- 本地数据主权是用户的核心诉求,但真正做到很难
- 透明化记忆可能成为行业标配
- 独立开发者依然有机会用极致的产品设计撬动市场
这个赛道目前的主要玩家包括:微软的Copilot(深度集成Windows生态)、苹果即将推出的Apple Intelligence(主打设备端推理和隐私)、以及一批创业公司如Rewind(现更名为Limitless,主打全量屏幕录制和回忆检索)、Granola(专注会议笔记)等。大厂的优势在于系统级权限和生态整合,但劣势在于船大难掉头、难以做出激进的交互创新。独立开发者和小团队的机会窗口在于:在大厂尚未覆盖的细分场景中,用极致的产品设计和快速迭代建立用户心智。但这个窗口期可能只有12-18个月——一旦操作系统层面原生集成了AI助手能力,第三方应用的生存空间将被大幅压缩。
但OpenHuman自己未必是最终赢家。在这个快速迭代的赛道上,三个月的先发优势可能转瞬即逝。真正的胜负手,在于谁能在隐私安全和功能丰富之间找到最佳平衡点。
核心要点
核心要点
相关推荐
Claude Code Skills详解:AI自动生成测试用例实战指南
深入解析Claude Code Skills技能文件的四大核心优势:篇幅扩展、复用传播、版本控制与渐进式加载,详解如何利用Skills实现AI自动生成测试用例的工程化落地流程。

独立开发者晒账单:花2366元做的小程序,零收入
一位独立开发者花半年时间、2366元开发英语阅读小程序,上线一个月仅10个用户零收入。逐笔拆解API调用、云服务、小程序认证等成本明细,复盘市场验证缺失、Azure隐藏扣费等典型教训。
Trae自定义模型与智能体配置完全指南
详解Trae自定义模型配置的两种方式:直接添加模型服务商API和中转API配置,以及如何创建个性化智能体打造专属AI助手,附完整操作流程与实用建议。