OpenLLMVTuber:开源AI虚拟人框架深度解析

从聊天框到能说会动的AI角色
大多数AI应用的交互形态,至今仍停留在文字聊天框里——你输入一段话,模型返回一段文字,交互到此为止。但如果AI不只是能打字回复,而是拥有一个可视化的形象,能听你说话、能开口回答、还能配合表情和动作把回复"演"出来呢?
OpenLLMVTuber 正是这样一个开源项目。它在GitHub上已经收获超过10K星标,本质上是一套完整的AI虚拟人框架,将语音识别(ASR)、大语言模型(LLM)、语音合成(TTS)和Live2D角色前端串联成一条完整的互动链路。用户对着麦克风说话,系统识别语音转为文字,交给大模型处理后生成回复,再由TTS将文字转为语音,最终前端的Live2D角色跟着说话、配合表情动作,呈现出一个能听能说能动的AI角色。
这里提到的Live2D,是一种由日本Cybernoids公司开发的2D动画技术,它能够在保持原始2D插画风格的前提下,通过网格变形和参数驱动实现类3D的动态效果。与传统3D建模不同,Live2D不需要构建完整的三维模型,而是将一张平面插画拆分为多个图层(如眼睛、嘴巴、头发、身体等),再通过物理模拟和参数映射实现自然的运动效果。这项技术最初广泛应用于日本的视觉小说游戏和手游角色展示,后来成为VTuber行业的核心技术之一。在OpenLLMVTuber中,Live2D承担的正是最终表现层的角色——将AI生成的语音和情感信息映射为角色的口型同步、表情变化和肢体动作。具体而言,Live2D的口型同步(lip-sync)实现通常有两种路径:一种是基于音频波形的实时分析,通过提取音频的音量包络和元音特征来驱动嘴部参数;另一种是基于音素时间戳的精确映射,TTS引擎在生成语音时同步输出每个音素的起止时间,前端据此精确控制嘴型变化。后者的效果更为自然,但要求TTS引擎支持音素级时间戳输出。此外,Live2D模型的表情系统通过参数组合实现丰富的情感表达,如将眉毛角度、眼睛开合度、嘴角弧度等参数与LLM输出的情感标签关联,就能让角色在说话时展现出喜怒哀乐等情绪变化。

两种使用模式:浏览器调试与桌面陪伴
OpenLLMVTuber提供了两种主要的使用方式,适配不同场景需求:
Web模式
在浏览器中直接打开,适合开发调试和功能演示。你可以快速验证各模块的配置是否正确,观察整条链路的运行效果,也方便在团队内部做展示。
桌面模式
这是更具实用性的模式——角色以透明背景的形式悬浮在桌面上,本质上就是一个"桌面宠物"。你可以把AI角色放在屏幕边角,一边写代码、一边看文档,随时和它聊天互动。这种形态让AI从工具变成了某种意义上的"陪伴",体验感完全不同于传统的聊天窗口。
模块化架构设计:OpenLLMVTuber的核心竞争力
这个项目最值得关注的地方,不在于Live2D角色有多好看——Live2D只是最终的表现层。真正的技术难点在于如何将语音识别、大模型推理、语音合成、角色前端这四大模块无缝衔接,并且保持足够的灵活性。
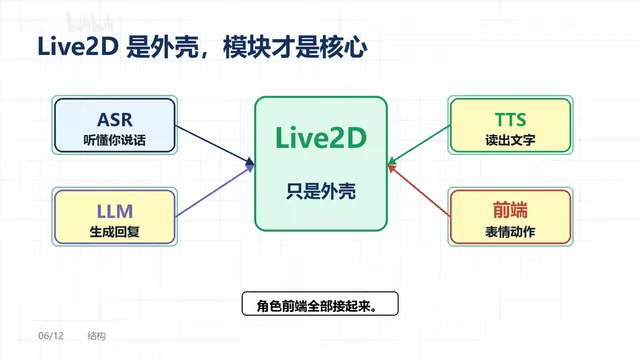
OpenLLMVTuber在架构上做了清晰的模块拆分:
- 大模型层(LLM):支持接入Ollama本地模型、OpenAI兼容接口,也能对接Claude、Gemini、DeepSeek等云端服务
- 语音识别层(ASR):可替换不同的语音识别方案,本地或云端均可
- 语音合成层(TTS):同样支持多种TTS引擎切换
- 前端表现层:Live2D角色渲染,支持表情和动作联动
其中,ASR(Automatic Speech Recognition,自动语音识别)是将人类语音信号转换为文本的关键技术。传统ASR系统采用流水线架构,包含声学模型、语言模型和解码器等独立组件,调优复杂且各组件的误差会逐级累积。而现代ASR系统通常基于端到端的深度学习架构,将整个识别过程统一为一个神经网络,直接从音频波形映射到文本序列,大幅简化了系统复杂度并提升了鲁棒性。OpenAI的Whisper模型就是一个典型的端到端语音识别方案,它在68万小时的多语言数据上训练,支持近百种语言的识别和翻译,其突破在于海量多语言训练数据和多任务学习策略,使其在噪声环境和口音变化下仍保持较高的识别准确率。在本地部署场景中,常见的ASR方案包括Whisper的各种量化版本(如faster-whisper)、FunASR等;云端方案则有Google Speech-to-Text、Azure Speech Services等。ASR的延迟和准确率直接影响整个对话链路的流畅度,因此选择合适的ASR方案是系统调优的关键环节之一。
TTS(Text-to-Speech,文本转语音)方面同样有丰富的选择。近年来,随着深度学习的发展,TTS技术经历了从拼接合成、参数合成到端到端神经网络合成的演进。当前主流的开源TTS方案包括GPT-SoVITS(支持少量样本声音克隆)、VITS系列、Bark、CosyVoice等,它们能够生成接近真人的自然语音,并支持情感控制和语速调节。云端TTS服务如ElevenLabs、Azure TTS等则在音质和延迟方面表现更优。在AI虚拟人场景中,TTS不仅要生成高质量的语音,还需要输出时间戳信息以实现口型同步(lip-sync),这对技术方案的选择提出了额外要求。
在大模型层面,Ollama是一个值得特别说明的工具。它是一个专为本地运行大语言模型设计的开源项目,极大地简化了在个人电脑上部署和运行LLM的流程。用户只需一条命令即可下载并运行Llama、Qwen、Gemma、Mistral等主流开源模型,Ollama会自动处理模型量化、GPU加速、内存管理等底层细节。更重要的是,它提供了与OpenAI兼容的API接口,这意味着任何支持OpenAI API格式的应用都可以无缝切换到Ollama本地模型。对于OpenLLMVTuber而言,使用Ollama意味着整个对话链路可以完全在本地运行,无需将任何数据发送到云端,这在隐私保护和离线使用场景中具有重要价值。
这种设计的好处显而易见:想要完全本地化部署,就用Ollama跑本地模型配合本地ASR/TTS;追求效果和速度,就接云端API。 每一层都可以独立替换,不会因为换了一个大模型就要重写整个系统。
值得补充的是,在整条对话链路中,端到端延迟(从用户说完话到AI角色开始回复的时间)是影响体验的关键指标。理想的对话延迟应控制在1-2秒以内。为此,系统通常采用流式处理策略:LLM以流式方式逐token输出文本,TTS在接收到第一个完整句子时就开始合成语音,前端在收到第一段音频时就开始播放和驱动口型动画。这种流水线并行的设计将原本需要串行等待的各阶段重叠执行,显著降低了用户感知到的响应延迟。这也是OpenLLMVTuber在工程实现上需要重点优化的方向。
亮点功能:语音打断与视觉感知能力
除了基础的语音对话链路,OpenLLMVTuber还有几个颇具实用价值的功能:
语音打断
当AI角色正在说话时,你可以直接插话打断,不需要等它把整段回复念完。这个功能看似简单,但在实际交互中极为重要——它让对话节奏更接近真实的人际交流,而不是僵硬的"你说完我再说"。
从技术实现角度看,语音打断涉及多个并行处理的挑战。系统需要在AI角色播放语音的同时,持续监听麦克风输入并进行语音活动检测(VAD, Voice Activity Detection)。VAD是语音处理流水线中的前置环节,负责判断音频流中哪些片段包含人类语音、哪些是静音或背景噪声。经典的VAD算法基于能量阈值和过零率等声学特征,而现代方案如Silero VAD则采用轻量级神经网络,能够在极低延迟(约30ms)下完成高精度的语音段检测。当检测到用户开始说话时,系统必须立即停止当前的TTS音频播放、中断正在进行的流式文本生成、清空音频缓冲区,然后无缝切换到新一轮的语音识别流程。这要求整个系统采用异步架构设计,各模块之间通过事件驱动机制协调。实现不好的打断机制会导致回声问题(AI的声音被麦克风重新采集)或状态混乱,因此这个看似简单的功能实际上是衡量AI对话系统工程质量的重要指标。
视觉感知能力
项目支持接入摄像头、屏幕录制或截图功能,让AI角色能够"看到"你或者当前屏幕内容。
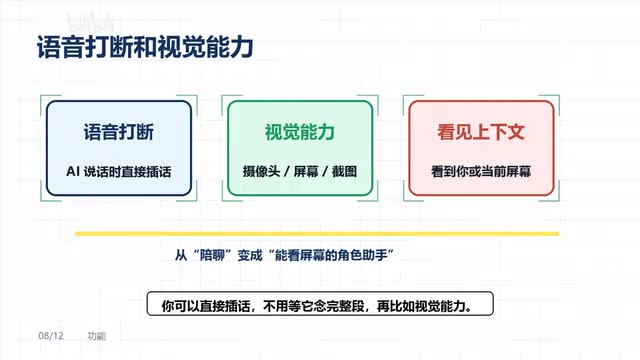
这个能力大幅拓展了应用场景。角色不再只是被动地听你说话然后回复,它还能主动感知视觉信息并做出反应。比如你正在写代码,它可以看到屏幕上的内容并提供建议;或者在直播场景中,它可以看到弹幕画面并做出互动。
这一能力的实现依赖于多模态大模型(如GPT-4o、Gemini Pro Vision等)对图像的理解能力。多模态大模型处理图像的核心机制是将视觉信息编码为与文本token兼容的表示形式——通过视觉编码器(通常基于Vision Transformer架构)将输入图像分割为若干patch并编码为向量序列,这些视觉token与文本token在同一个Transformer架构中进行联合注意力计算,从而实现跨模态的理解和推理。系统将捕获的画面以图片形式传入多模态模型,模型结合视觉信息和对话上下文生成更具情境感知的回复。在屏幕感知场景中,模型需要理解UI布局、代码语法、文字内容等多层次信息,这对模型的视觉-语言对齐能力提出了较高要求。
部署上手:理解全链路比记命令更重要
OpenLLMVTuber并不是那种"下载即用"的小工具。部署过程需要准备Python环境、安装依赖、配置大模型接口、配置语音服务、选择Live2D角色前端,整个流程有一定的技术门槛。
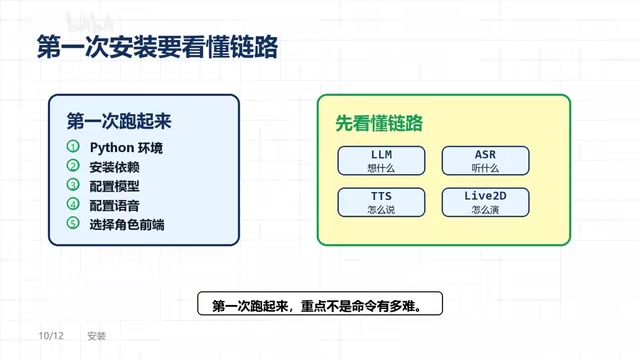
但正如项目介绍中强调的:第一次跑起来的重点不是命令有多难,而是你要理解LLM、ASR、TTS、Live2D各自负责哪一段。 把这条从"声音输入→文字→模型推理→文字→语音输出→角色表演"的完整链路看明白,整个项目的逻辑就清晰了。
对于有一定开发基础的用户来说,这反而是一个很好的学习机会——通过这个项目,你可以完整理解一个AI虚拟人系统的全链路架构。每个模块的选型、延迟优化、模块间的数据流转方式,都是实际工程中非常有价值的知识。
应用场景与价值判断
从实际应用角度看,OpenLLMVTuber至少覆盖了以下几个方向:
- 虚拟主播/VTuber:为AI驱动的虚拟主播提供完整技术栈
- 桌面AI助手:带形象的桌面陪伴助手,比纯文字交互更有温度
- AI角色/数字人:游戏、教育、客服等场景中的交互式AI角色
- Agent可视化外壳:为已有的AI Agent加上能说话、有表情的前端形象
值得一提的是VTuber行业的背景。VTuber(Virtual YouTuber)是指使用虚拟形象进行直播和视频创作的内容创作者,这一概念起源于2016年日本的绊爱(Kizuna AI),随后迅速发展为一个庞大的产业。Hololive、Nijisanji等VTuber经纪公司的年营收已达数亿美元。传统VTuber依赖真人演员通过面部捕捉设备驱动虚拟形象,而AI驱动的VTuber则完全由AI系统控制,无需真人实时操控。这种模式的优势在于可以7×24小时不间断运行,且运营成本大幅降低。OpenLLMVTuber所代表的AI VTuber技术栈,正在成为这个行业的新趋势,尤其是在AI陪伴、自动化直播等新兴场景中展现出巨大潜力。
关于Agent可视化外壳这一方向,值得进一步展开。AI Agent是指具备自主规划、工具调用和环境交互能力的智能体系统,如AutoGPT、LangChain Agent等。这些Agent通常以API或命令行形式运行,缺乏直观的交互界面。将OpenLLMVTuber作为Agent的可视化外壳,意味着Agent的思考过程、工具调用结果和最终回复都可以通过虚拟角色的语音和表情呈现出来。这不仅提升了用户体验,还为Agent的调试和监控提供了更直观的方式——你可以通过角色的表情变化感知Agent当前的处理状态,而不是盯着日志输出。
10K星标的社区认可度说明这个项目确实解决了一个真实需求:在大模型能力已经足够强的今天,如何让AI的交互形态从冰冷的文字框进化到更自然、更有表现力的虚拟角色。 如果你正在探索AI角色、虚拟主播或桌面陪伴方向,OpenLLMVTuber是一个值得深入研究的开源方案。
核心要点
相关推荐
Claude Code安装配置教程:搭配国产模型低成本开启氛围编程
详细讲解Claude Code的安装步骤与配置方法,包括Node.js环境搭建、CCSwitcher模型管理工具使用,以及搭配DeepSeek等国产模型实现低成本氛围编程的完整流程。
Keyroll:一款主打稳定的Claude续杯工具深度体验
深度体验Claude续杯工具Keyroll,分析其稳定性、响应速度等核心优势,探讨续杯工具的安全性与合规性问题,帮助开发者在用量限制下做出理性选择。
1700+顶级开发者个人网站合集,前端设计灵感宝库
GitHub上24000+星标的宝藏仓库,收录1700多个全球顶尖程序员和设计师的个人网站。涵盖极简、赛博朋克、3D特效等多种风格,适合前端开发者、设计师和求职者寻找灵感与参考。