GPT 5.4 vs Opus 4.7 vs Kimi K2.6 Code编程实测对比
GPT 5.4全能稳定,Kimi K2.6性价比最优,Claude Opus 4.7定位尴尬。
本文从后端开发、前端开发、性价比和工具生态四个维度对比了Claude Opus 4.7、GPT 5.4和Kimi K2.6 Code三大AI编程模型。GPT 5.4综合实力最强,在后端开发、长任务执行和工具调用方面表现稳定全面;Kimi K2.6 Code是性价比之王,前端开发突出且成本显著更低,原生CLI体验最佳;Claude Opus 4.7进步有限,前端尚可但后端表现持续令人失望。
概述:三大AI编程模型的实力较量
随着AI编程助手的快速迭代,开发者面临一个现实问题:Claude Opus 4.7、GPT 5.4和Kimi K2.6 Code,到底该选哪个?本文基于实际编程使用体验,从后端开发、前端开发、性价比和工具生态四个维度进行深度对比,帮助开发者做出更明智的选择。
核心结论很明确:不看炒作,专注实际使用体验。三个模型各有所长,选择取决于你的具体需求和预算。
技术背景:AI编程助手的能力基础
AI编程助手的核心技术基础是大型语言模型(LLM),这类模型通过在海量代码库(如GitHub公开仓库)和自然语言文本上进行预训练,习得了代码语法、编程范式、调试逻辑乃至架构设计模式。现代AI编程助手通常还引入了强化学习人类反馈(RLHF)和代码专项微调,使模型在指令遵循、错误修复和多步骤推理上表现更稳定。不同厂商的模型在训练数据配比、上下文窗口长度(从32K到200K+ tokens不等)以及工具调用(Function Calling)能力上存在显著差异,这直接决定了它们在复杂工程任务中的表现上限。
GPT 5.4编程能力:综合实力最强的全能选手
在大多数编程场景下,GPT 5.4是目前最可靠的AI编程模型。它的核心优势体现在以下几个方面:
- 后端开发稳定性:调试、规划、指令遵循、工具调用表现出色
- 长任务执行力:能真正把多步骤任务做完,不会中途跑偏
- 全面性:编码、推理、工具调用、智能体、计算机使用、长上下文全面强大
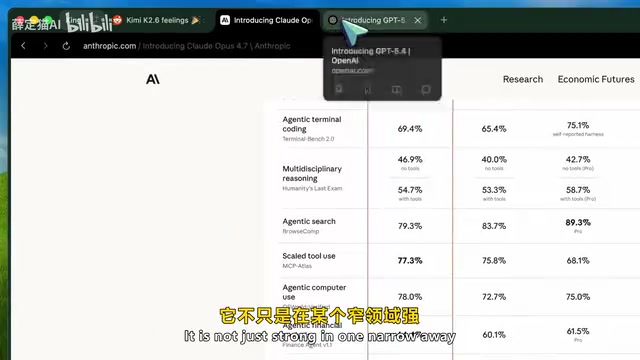
GPT 5.4的核心竞争力不在于某个细分领域特别突出,而在于全面且稳定。它是目前最全能的AI编程模型,无论是API重构、架构设计、数据库逻辑还是跨文件调试,都能给出令人满意的结果。
为什么GPT 5.4能做到"全能且稳定"? 这在技术层面源于其多任务联合训练策略和强大的指令跟随能力。OpenAI在训练过程中引入了大量多轮对话、工具调用和智能体(Agent)场景数据,使模型能够在长上下文中维持任务连贯性。所谓"长任务执行力",本质上是模型在扩展上下文窗口内保持注意力焦点、不发生"上下文漂移"的能力——这在技术上依赖于改进的位置编码(如RoPE或ALiBi)和注意力机制优化。GPT 5.4在工具调用方面的稳定性,则得益于其对结构化输出(JSON Schema约束)的精准支持,这对于需要频繁调用外部API或执行多步骤自动化任务的后端开发场景至关重要。
不过,GPT 5.4并非完美无缺。在前端开发方面,特别是UI审美、视觉效果和界面体验感上,它并不是最优选择。如果你的项目以前端为主,可能需要考虑其他方案。
Kimi K2.6 Code评测:性价比之王
如果将成本纳入考量,Kimi K2.6 Code可能是综合最优的AI编程选择。这个结论的逻辑很清晰:
前端开发的突出优势
Kimi K2.6 Code在前端开发方面表现突出,包括UI界面设计、落地页制作、组件开发等场景,生成的界面审美和体验感都相当不错。更重要的是,它的后端表现也比预期好很多,并非只是"前端专精"。
性价比的核心逻辑
性价比为什么重要?因为在实际开发中,如果一个模型在某些方面稍弱一点,但整体依然出色、响应更快、更省钱,那对开发者来说就是更聪明的选择。Kimi K2.6 Code正是这样的定位——在关键指标上足够接近GPT 5.4,在前端开发上甚至更强,而成本显著更低。
理解AI模型定价的底层逻辑: AI模型的定价通常以每百万tokens(输入+输出)计费,顶级模型的API调用成本可达每百万tokens 15-60美元,而性价比模型往往将这一成本压缩至1-5美元区间。Kimi K2.6 Code所代表的"性价比路线",在技术上通常通过模型蒸馏(Knowledge Distillation)、混合专家架构(MoE,Mixture of Experts)或更激进的量化压缩来实现。MoE架构尤为值得关注:它允许模型在推理时只激活部分参数子集,在保持较高模型容量的同时大幅降低计算成本。对于高频调用的开发团队而言,模型成本差异在月度账单上可能体现为数倍乃至数十倍的差距,这使得性价比成为工程决策中不可忽视的维度。
原生CLI工具体验最佳
值得一提的是,Kimi K2.6 Code在自家CLI工具中的使用体验最好。这并不奇怪——他们的命令行工具本来就是专门为这个模型打造的,无论是响应节奏、工具调用还是工作流配合都经过精心优化。
原生集成为何重要? 命令行界面(CLI)工具与AI模型的原生集成,在技术层面意味着工具调用协议、流式输出(Streaming)参数和上下文管理策略都经过了针对性优化。第三方封装工具(如通过统一API网关接入多个模型)往往需要在协议转换层引入额外延迟,并可能丢失模型特有的高级功能(如特定的系统提示格式或专有工具调用语法)。原生CLI工具还能更好地利用模型的"提示缓存"(Prompt Caching)机制——即对重复出现的系统提示或代码上下文进行缓存,显著降低延迟和成本。这也是为什么在同等模型能力下,原生工具链往往能提供更流畅的开发体验。如果要获得最佳体验,建议直接使用原生环境,而非第三方封装。
Claude Opus 4.7编程表现:进步有限,定位尴尬
Opus 4.7是这次AI编程模型对比中评价最平淡的一个。虽然比之前有进步,但提升不够明显。
前端尚可,后端持续让人失望
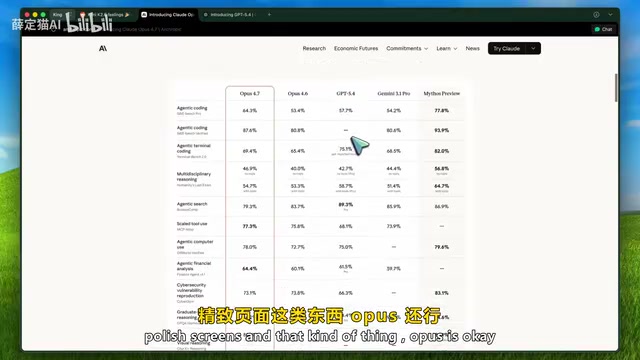
做好看的UI界面、落地页、精致页面这类前端工作,Opus还行。但真正的问题出在后端代码——一旦任务变复杂,各种奇怪bug就会出现。在API重构、架构设计、数据库逻辑、跨文件调试等场景中,Opus 4.7依然没有达到预期。
它有一个让人抓狂的毛病:总在不该纠结的地方瞎琢磨,耗时特别长,搞得开发者不得不时刻盯着它。这一行为特征在技术上有其根源:Claude Opus系列由Anthropic开发,其设计哲学强调"宪法AI
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。