PAO项目实战:贝叶斯优化驱动Aspen Plus自动仿真教程
项目概述:让优化算法自动驱动化工仿真
PAO(Process Automation Optimization)项目是一个将贝叶斯优化与Aspen Plus化工仿真软件深度集成的自动化工具。它的核心理念非常直接:用户只需编辑一个YAML配置文件,系统就能自动调用Aspen进行多轮仿真迭代,最终找到化工流程的最优操作参数。
Aspen Plus是AspenTech公司开发的大型通用化工流程模拟软件,广泛应用于石油化工、精细化工、制药等行业的工艺设计与优化。它内置了丰富的热力学模型、单元操作模型和物性数据库,能够模拟稳态和动态化工过程。Aspen Plus通过COM(Component Object Model)接口支持外部程序调用,这使得Python等编程语言可以通过自动化接口读写仿真参数、触发计算并提取结果,为本项目的自动化优化提供了技术基础。
贝叶斯优化(Bayesian Optimization)是一种基于概率模型的全局优化方法,特别适用于目标函数评估代价高昂的场景。与网格搜索或随机搜索不同,贝叶斯优化通过构建目标函数的概率代理模型(通常是高斯过程),在每次迭代中利用采集函数(如Expected Improvement或Upper Confidence Bound)来决定下一个采样点。这种方法的核心优势在于它能够在极少的函数评估次数内逼近全局最优,这对于每次Aspen仿真可能需要数秒到数分钟的化工优化场景尤为关键。
目前项目开发进度约30%,后续将加入AI Agent(Engine)模块,实现自动阅读文献、调优参数、搭建流程框架等高级功能。本期内容聚焦于如何手动配置和运行该系统。
项目结构与核心配置文件解析
下载项目后,用户会看到四个主要文件夹:case(案例)、docs(文档)、report(报告)和src(源码)。实际使用时,所有操作都在case文件夹中进行。
核心操作集中在一个YAML配置文件中,用户无需修改任何代码文件。YAML(YAML Ain't Markup Language)是一种人类可读的数据序列化格式,以缩进表示层级关系,语法简洁直观。相比JSON,YAML支持注释、多行字符串和更灵活的数据表达方式,非常适合作为配置文件格式。在工程实践中,使用YAML作为配置入口可以将用户与底层代码完全解耦,降低使用门槛。
配置文件包含以下几个关键部分:
- 仿真软件配置:指定BKP文件路径、是否显示Aspen窗口等
- 设计变量:定义优化搜索空间
- 输出节点:指定需要从仿真中提取的结果
- 目标函数:定义优化方向(最大化或最小化)
- 约束条件:设置可行域边界
- 提取配置:节点数据库构建参数
- 优化器:贝叶斯优化及早停策略
设计变量与目标函数配置详解
设计变量定义方法
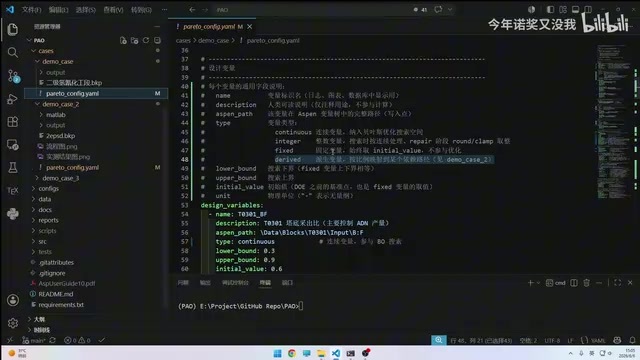
每个设计变量需要指定:名称、描述、Aspen节点路径、变量类型(整数型int或连续型float)、上下界和初始值。
以乙腈精馏工段案例为例:
- 塔板理论级数比(BF值):连续型,范围0.03~0.09,初始值0.06
- 回流比:连续型,同样需设定搜索范围
如果某个变量不希望参与优化,可将其设为固定值(fixed),系统会在优化过程中跳过该变量。
目标函数设置
目标函数与设计变量结构类似,需指定节点路径和优化方向。例如:
- ADN产量:取最大值(maximize)
- 再沸器热负荷:取最小值(minimize)
当存在多个目标时,系统自动切换为多目标优化模式,开始进行Pareto前沿搜索。Pareto前沿(Pareto Front)是多目标优化中的核心概念,指的是在目标空间中所有非支配解(Non-dominated Solutions)构成的集合。一个解被称为非支配的,意味着不存在另一个解能在所有目标上都优于它。在化工优化中,产量最大化和能耗最小化往往相互矛盾,Pareto前沿为工程师提供了一组最优权衡方案,由决策者根据实际需求从中选择。常用的多目标优化算法包括NSGA-II、MOEA/D等,而本项目采用的多目标贝叶斯优化则通过扩展采集函数(如EHVI,Expected Hypervolume Improvement)来高效逼近Pareto前沿。
约束条件配置
约束通过比较算子(≥、≤、=等)和阈值来定义。例如要求产品纯度≥0.99,若仿真结果收敛但不满足约束,该工况会被标记为"不可行点"。
节点数据库:首次运行的代价与复用机制
项目中一个非常精妙的设计在于节点路径缓存机制。Aspen中每个设备包含大量参数节点,首次运行时系统需要遍历搜索所有相关节点路径,这个过程往往非常耗时。
但搜索结果会存储在一个.db文件中。后续运行时,系统直接从数据库读取路径,速度大幅提升。这类似于计算中的记忆化(Memoization)——计算过一次的结果直接复用,避免重复劳动。从计算机科学的角度来看,记忆化是动态规划的核心技术之一,通过缓存已计算结果来避免重复计算。在本项目中,Aspen的节点树结构类似于文件系统的目录树,每个设备(如精馏塔、换热器)下包含数百甚至数千个参数节点。首次遍历这棵树的时间复杂度与节点总数成正比,而将结果持久化到轻量级数据库后,后续查询的时间复杂度降为O(1)或O(log n),实现了数量级的性能提升。
配置中的"深度"参数控制节点搜索的层级:深度越大,搜索越全面,但首次运行越慢。一般建议设置为2~4,其中4已经是非常深的搜索层级。
贝叶斯优化与代理模型原理
代理模型的直觉理解
想象你站在一间漆黑的房间里,面前有一块起伏不平的连续地面,你需要找到最高点。你手中有有限的荧光球——每投一个球就能看到该位置的高度,但每次投掷都有代价。
你的目标就是用最少的荧光球,尽可能准确地描绘出地面形状并找到最高点。这正是贝叶斯优化的核心思想:
-
DOE阶段(初始采样):先投出一批荧光球,建立对解空间的初步认知。DOE(Design of Experiments,实验设计)是统计学中系统规划实验的方法论。在优化上下文中,DOE阶段的目的是在搜索空间中均匀分布初始采样点,为代理模型提供足够的训练数据。常用的采样策略包括拉丁超立方采样(Latin Hypercube Sampling)、Sobol序列和正交设计等。良好的初始采样能够避免代理模型在早期产生严重偏差,从而加速后续优化收敛。
-
迭代优化阶段:基于已有信息,智能选择下一个采样点,在"探索未知区域"(Exploration)与"利用已知高点"(Exploitation)之间取得平衡。这种探索-利用权衡(Exploration-Exploitation Trade-off)是贝叶斯优化区别于传统优化方法的关键特征,采集函数通过量化每个候选点的潜在价值来自动实现这一平衡。
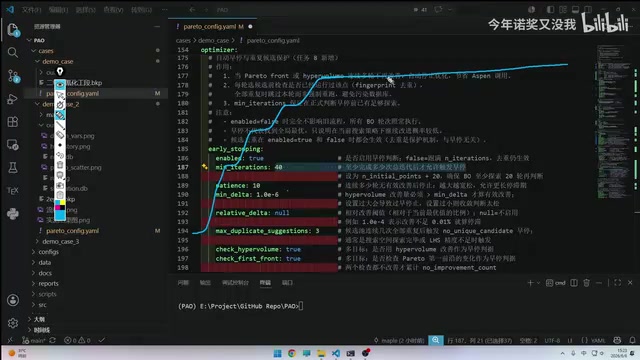
早停机制与耐心值设置
配置中的早停策略来源于一篇顶会论文的门控系统。当连续若干代迭代没有改善时,系统自动停止优化,避免浪费计算资源。早停(Early Stopping)最初广泛应用于深度学习训练中,用于防止过拟合。在优化领域,早停策略通过监控目标函数的改善趋势来判断是否继续迭代。门控系统(Gating System)的引入使得停止判断更加智能——它不仅考虑连续无改善的代数,还可能结合改善幅度、搜索空间覆盖率等多维信息来做出决策。这种机制在计算资源有限的工业场景中具有重要的实用价值。
不过需要注意的是,早停可能会错过后期的突破性改善。用户需要根据实际经验调整"耐心值"(patience),也就是容忍多少代无改善后才触发停止。
不可行点的信息利用
基于论文方法,系统将收敛点标记为正样本,不收敛点标记为负样本。负样本同样携带有价值的信息——它告诉优化器"远离这些区域"。这类似于磁铁的正负极,形成引力和斥力场,共同引导搜索方向朝可行域集中。
从理论角度来看,在约束优化中,传统方法往往简单丢弃不满足约束的采样点。然而,基于分类的约束处理方法(如Probability of Feasibility)将可行性建模为一个独立的分类问题,利用所有采样点(包括不可行点)来学习可行域的边界。这种方法通过训练一个额外的高斯过程分类器来估计任意点的可行概率,并将其与改善期望相乘作为最终的采集函数值,从而自然地将搜索引导至可行且有潜力的区域。这意味着即使是失败的仿真也不会被浪费,每一次计算都在为优化器提供有价值的信息。
实战演示:从单目标到多目标优化
单目标优化案例
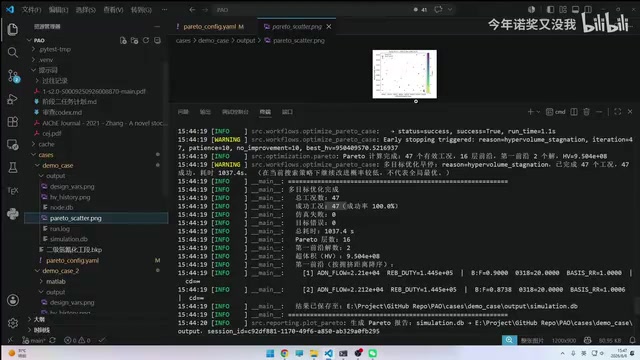
以乙腈精馏工段为例,同时优化ADN产量和再沸器热负荷。首次运行时节点扫描较慢,但后续迭代每次仅需几秒。整个优化过程在约30次迭代后收敛。
运行结果包含三类关键输出:
- Pareto前沿图:直观展示多目标之间的权衡关系,图中每个点代表一个非支配解,工程师可以根据实际生产需求在产量和能耗之间选择最合适的操作点
- 收敛曲线:可以观察到大约20代开始趋于收敛,这表明代理模型已经较好地拟合了目标函数的全局趋势
- 变量分布图:显示最优解倾向的参数区域,帮助用户判断是否需要调整搜索范围。如果最优解集中在边界附近,通常意味着搜索范围设置过窄,需要扩大边界
复杂多目标优化案例
第二个案例涉及一丙醇、异丁醇和水的三产品分离,包含三个精馏塔、14个设计变量和多个约束条件,复杂度明显更高。14个设计变量意味着搜索空间的维度为14维,这在传统的穷举搜索中几乎不可能处理——即使每个变量只取10个离散值,组合数也高达10^14。贝叶斯优化的样本效率优势在这种高维场景中体现得尤为明显。
由于已有节点缓存,第二次运行仅需搜索3个节点即可启动。系统还内置了可行性预检功能:如果连续30次找不到收敛点,则判定当前搜索空间设置无效,提醒用户调整参数范围。这一设计避免了用户在错误配置下长时间等待无效结果。最终该案例在71次迭代、约7分钟内找到了最优解。
未来展望:AI Agent赋能化工流程设计
项目后续将引入Engine模块(AI Agent),计划实现以下能力:
- 自动阅读化工文献并提取工艺参数
- 智能调优和参数推荐
- 自动搭建Aspen流程框架
- 上层结构优化(解决当前TC计算的临时方案)
上层结构优化(Superstructure Optimization)是化工过程综合(Process Synthesis)中的经典问题,指的是在一个包含所有可能工艺路线的超级结构中,通过数学规划方法选择最优的流程拓扑结构。这不仅涉及操作参数的优化,还包括设备选型、连接方式和流程架构的决策,是比参数优化更高层次的设计问题。
这将把项目从"人工配置+自动优化"升级为"AI全自主工艺开发",真正实现化工流程设计的智能化闭环。结合大语言模型的文献理解能力和贝叶斯优化的高效搜索能力,未来的化工流程设计有望从传统的"经验驱动"模式转变为"数据与AI驱动"的新范式。
核心要点
相关推荐
Claude Code Skills详解:AI自动生成测试用例实战指南
深入解析Claude Code Skills技能文件的四大核心优势:篇幅扩展、复用传播、版本控制与渐进式加载,详解如何利用Skills实现AI自动生成测试用例的工程化落地流程。

独立开发者晒账单:花2366元做的小程序,零收入
一位独立开发者花半年时间、2366元开发英语阅读小程序,上线一个月仅10个用户零收入。逐笔拆解API调用、云服务、小程序认证等成本明细,复盘市场验证缺失、Azure隐藏扣费等典型教训。
Trae自定义模型与智能体配置完全指南
详解Trae自定义模型配置的两种方式:直接添加模型服务商API和中转API配置,以及如何创建个性化智能体打造专属AI助手,附完整操作流程与实用建议。