Perplexity Computer整合深度研究为原生技能,AI Agent能力融合新范式
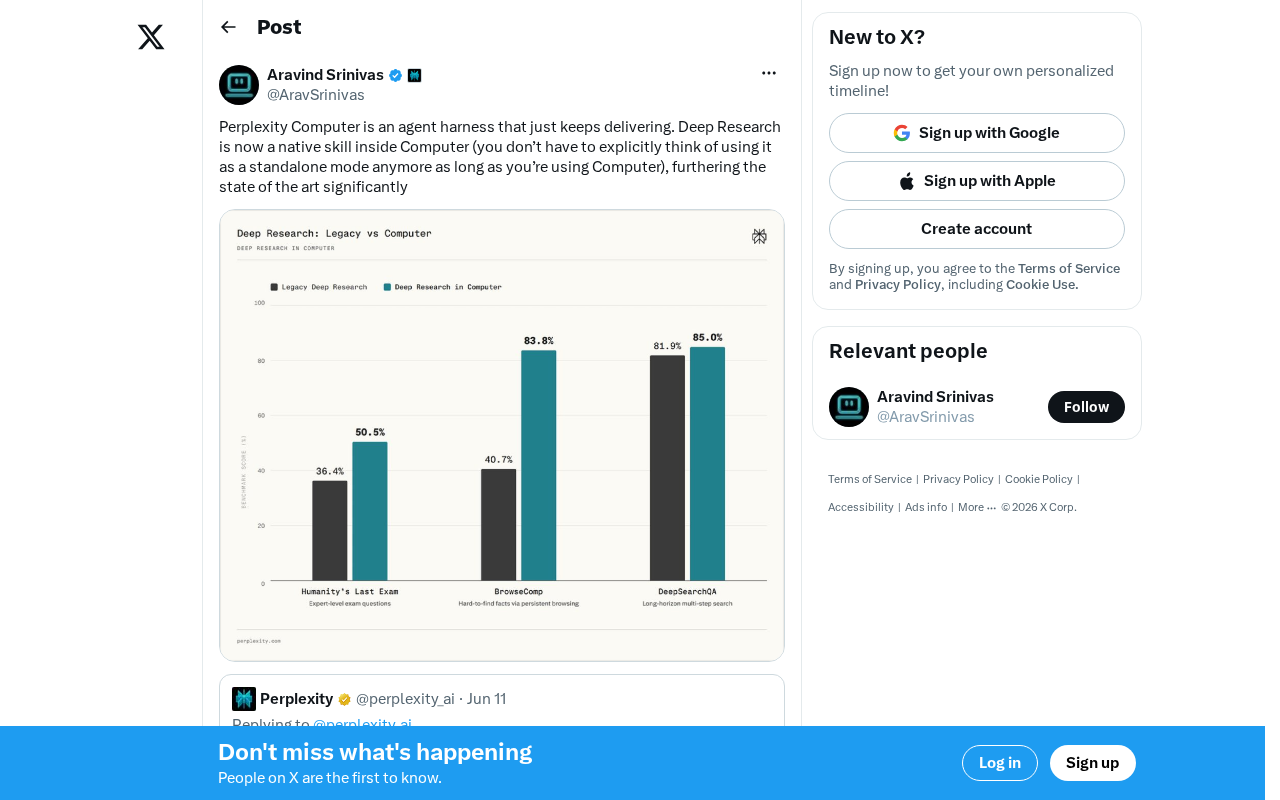
Perplexity Computer 的最新进化
Perplexity 近日宣布了一项重要更新:Deep Research(深度研究)功能已被整合为 Perplexity Computer 的原生技能。这意味着用户在使用 Computer 模式时,不再需要手动切换到独立的 Deep Research 模式——系统会根据任务需求自动调用深度研究能力。
Deep Research 是一种多步骤、多轮次的自动化研究方法,区别于传统的单次搜索检索。它模拟人类研究员的工作流程:先提出初始查询,根据返回结果生成后续子问题,再对子问题逐一深入调研,最终综合多个信息源形成结构化报告。这一过程通常涉及数十次甚至上百次的网络请求和信息交叉验证。OpenAI 在 2025 年初率先在 ChatGPT Pro 中推出了类似功能,随后 Perplexity、Google Gemini 等产品也相继跟进。Deep Research 的核心技术挑战在于查询分解(query decomposition)、信息源可靠性评估、以及多源信息的一致性整合。
这一变化看似简单,实则代表了 AI Agent 架构设计理念的重要转变。
从独立工具到原生技能:为什么这很重要
消除用户的认知负担
在此前的产品形态中,Deep Research 是一个独立的功能模式。用户需要明确意识到"我现在需要做深度研究",然后主动切换到对应模式。这种设计虽然功能完备,但给用户带来了额外的认知负担——你需要先判断任务类型,再选择合适的工具。
将 Deep Research 变为 Computer 的原生技能后,决策权从用户转移到了 AI Agent 本身。Agent 会自主判断何时需要启动深度研究,何时只需简单检索,何时需要结合多种能力来完成任务。这正是 Agent 架构的核心价值所在。
AI Agent(智能体)是指能够自主感知环境、制定计划并执行行动的 AI 系统,区别于传统的"输入-输出"式大语言模型交互。在 Agent 架构中,核心组件通常包括:规划模块(Planning)、记忆模块(Memory)、工具调用模块(Tool Use)和反思模块(Reflection)。Agent 的关键能力在于"自主决策"——它不需要用户逐步指令,而是根据高层目标自行拆解任务、选择工具、执行操作并验证结果。这一架构理念源自强化学习和认知科学的交叉研究,近年来随着大语言模型推理能力的提升而快速走向产品化。
Agent Harness 的设计哲学
Perplexity 官方将 Computer 定位为一个"Agent Harness"(智能体框架),这个术语值得关注。Harness 一词在软件工程中通常指"测试框架"或"运行框架",用于统一管理和调度多个组件。Perplexity 将其 Computer 产品定位为 Agent Harness,意味着它扮演的是一个"元层"角色——不直接执行某项具体任务,而是作为调度中枢,根据任务需求动态编排底层能力模块。这种设计模式在微服务架构中被称为"编排器模式"(Orchestrator Pattern),其优势在于各能力模块可以独立迭代升级,而上层的调度逻辑保持稳定。类似的设计理念也出现在 LangChain、AutoGPT 等开源 Agent 框架中,但 Perplexity 是较早将这一架构以消费级产品形态呈现的公司。
随着 Deep Research 的整合,Computer 现在至少具备了以下原生能力:
- 网络搜索与信息检索:Perplexity 的核心能力
- 深度研究与分析:对复杂主题进行多轮、多源的深入调研
- 计算机操作:直接与桌面应用和网页交互
- 任务编排:自动组合上述能力完成复杂任务
其中,"计算机操作"能力指的是 AI Agent 能够直接控制鼠标点击、键盘输入、屏幕截图识别等操作,从而与桌面应用程序和网页进行交互。这项技术最早由 Anthropic 在 2024 年 10 月随 Claude 3.5 Sonnet 发布时公开展示,被称为"Computer Use"。其技术原理是通过视觉模型识别屏幕内容,结合大语言模型的推理能力生成操作指令,再通过系统级 API 执行具体的 GUI 操作。这项能力的意义在于打破了 AI 只能在聊天窗口内工作的限制,使其能够操作任何人类可以使用的软件工具。
这种"技能融合"的趋势,正在成为 AI Agent 产品的主流方向。
行业趋势:从单点工具到统一智能体
与 ChatGPT、Gemini 等竞品的对比
Perplexity 的这一动作,与当前 AI 行业的大趋势高度一致。OpenAI 的 ChatGPT 也在不断将搜索、代码执行、图像生成等能力融合到统一对话界面中;Google 的 Gemini 同样在推进多模态能力的无缝整合。
但 Perplexity 的独特之处在于,它从搜索引擎的基因出发,将信息获取和深度研究作为 Agent 的核心技能树。这与 ChatGPT 从对话生成出发、Gemini 从多模态理解出发的路径形成了明显的差异化竞争格局。
当前 AI Agent 赛道的竞争格局可以从各家公司的"基因"来理解。OpenAI 以 GPT 系列大语言模型起家,其 Agent 能力建立在强大的通用推理和生成能力之上;Google DeepMind 拥有搜索引擎和多模态数据的天然优势,Gemini 的 Agent 化路径强调跨模态理解与 Google 生态整合;Anthropic 则以安全性和可控性为核心卖点,Claude 的 Computer Use 功能强调可靠的工具操作。Perplexity 的差异化在于它本质上是一个"答案引擎"(Answer Engine),其核心竞争力是信息检索的准确性和时效性。将 Deep Research 作为原生技能,实际上是在强化这一核心优势,使其在"信息密集型任务"这一垂直场景中建立护城河。
对用户体验的实际影响
对于终端用户而言,这次更新的实际意义在于:
- 工作流更加流畅:不再需要在不同模式间来回切换
- 结果质量可能提升:Agent 可以在任务执行过程中动态决定是否需要深度研究,而不是一开始就做出二选一的判断
- 降低使用门槛:新用户不需要了解 Deep Research 是什么,系统会在需要时自动使用
展望:AI Agent 能力整合的下一步
Perplexity Computer 的这次更新,折射出 AI Agent 发展的一个关键方向——能力的无缝融合。未来的 AI Agent 不会要求用户选择"我要用搜索模式还是研究模式还是写作模式",而是像一个全能助手一样,根据任务需求自动调配最合适的能力组合。
当然,这也带来了新的技术挑战:Agent 如何准确判断何时该启动深度研究?如何平衡响应速度和研究深度?如何在资源消耗和结果质量之间找到最优解?
从技术角度看,Agent 自动判断何时启动深度研究,本质上是一个"意图路由"(Intent Routing)问题。系统需要在接收到用户请求后的极短时间内,评估任务的复杂度、所需信息的深度和广度、以及用户的隐含期望,然后决定调用哪些能力模块。这一决策的难点在于:过度触发深度研究会导致响应延迟(Deep Research 通常需要数分钟),而触发不足则会返回浅层、不完整的结果。业界目前的主流方案包括基于分类器的路由、基于 LLM 自评估的路由、以及混合式路由策略。此外,深度研究涉及大量的 API 调用和计算资源消耗,如何在成本控制和结果质量之间取得平衡,也是商业化落地的关键考量。
这些问题的解决质量,将决定各家 AI Agent 产品的真正竞争力。
Perplexity 用"just keeps delivering"来形容 Computer 的持续进化,从目前的产品迭代节奏来看,这个评价并不夸张。
核心要点
相关推荐
Claude Code安装教程与AI编程工具五大发展阶段全解析
详解Claude Code安装配置全流程,梳理AI编程工具从手动编码到智能体的五个发展阶段,分析0到1项目构建优势与1到100迭代挑战,帮助开发者快速上手AI编程。

企业级AI项目Rules文件:5条硬规矩+6个写法门道
AI编程项目总被AI乱改代码?本文分享企业级Rules文件的5条硬规矩和6个写法门道,涵盖Claude Code、Cursor等工具的规则文档写法,附三类项目Rules模板,让AI按你的规矩稳定交付。
旧手机组建云计算集群:谷歌联合UCSD探索可持续计算新路径
谷歌与UCSD合作探索将旧手机组建为云计算集群,利用手机的ARM芯片高能效比优势,减少电子废弃物和数据中心碳足迹。本文分析手机集群的技术可行性、环境效益及在边缘计算、联邦学习等场景的应用前景。