Perplexity联手Intel:本地AI模型与混合推理登陆笔记本电脑
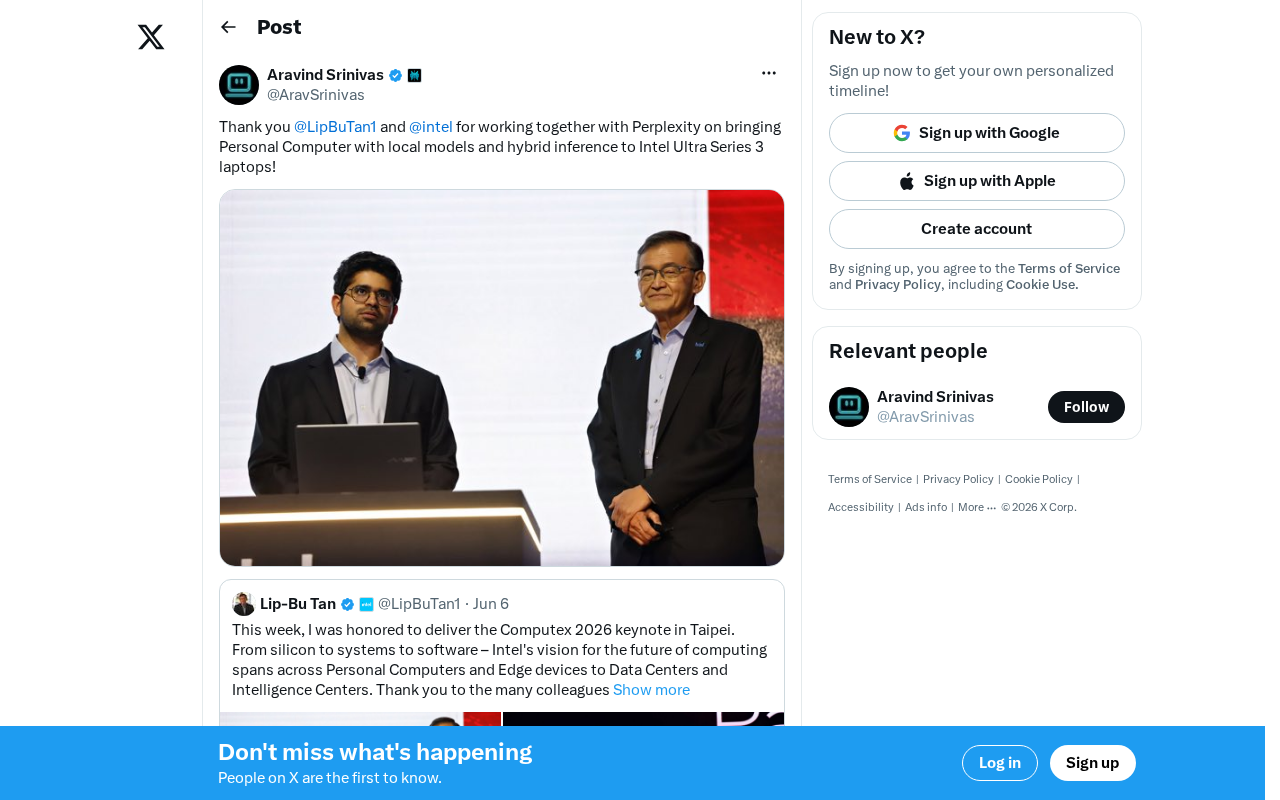
Perplexity与Intel达成合作
Perplexity AI CEO Aravind Srinivas近日在社交媒体上公开感谢Intel CEO Lip-Bu Tan及Intel团队,宣布双方正在合作将本地AI模型和混合推理能力带到Intel Core Ultra Series 3笔记本电脑上。这一合作标志着Perplexity这家AI搜索引擎公司正式进军个人电脑端侧AI领域。
Perplexity AI成立于2022年,由前Google和OpenAI研究员Aravind Srinivas创立,定位为"答案引擎"而非传统搜索引擎。与Google搜索返回链接列表不同,Perplexity直接生成结构化答案并标注信息来源。其技术架构结合了大语言模型的生成能力与实时网络检索的RAG(检索增强生成)技术,能够在回答问题的同时提供可溯源的引用链接,这种设计有效缓解了大模型"幻觉"问题。截至2024年,Perplexity估值已超过90亿美元,月活用户突破1500万,被视为Google搜索最具威胁力的挑战者之一。其商业模式包括免费基础版和每月20美元的Pro订阅版,后者可调用Claude、GPT-4等多种大模型。在竞争格局上,Perplexity面临来自Google SGE(Search Generative Experience)、Microsoft Copilot以及新兴的AI搜索产品如You.com的多方竞争,但其简洁的产品体验和对学术研究场景的深度优化使其建立了独特的用户心智。
什么是混合推理?Perplexity的端云协同方案
从Perplexity的表述来看,这次合作的核心概念是**"Personal Computer with local models and hybrid inference"**——即在个人电脑上运行本地模型,并结合云端能力进行混合推理。
具体来说,用户在使用Perplexity时,部分AI推理任务将直接在笔记本电脑的NPU(神经网络处理单元)上完成,而更复杂的任务则交由云端处理。NPU是专门为机器学习推理任务设计的加速芯片,与通用CPU相比,NPU针对矩阵运算和张量计算进行了硬件级优化,能以更低功耗完成AI推理任务。从架构设计上看,NPU通常采用脉动阵列(Systolic Array)或数据流架构,内置大量并行计算单元和片上缓存,专门优化了深度学习中最常见的矩阵乘法和卷积运算。与GPU相比,NPU省去了图形渲染相关的硬件模块,将晶体管预算全部用于AI计算,因此在同等功耗下能提供更高的AI推理吞吐量。其核心优势在于能效比——完成同样的AI推理任务,NPU的功耗仅为GPU的几分之一,这对电池供电的笔记本电脑至关重要。
混合推理(Hybrid Inference)的核心思想是根据任务复杂度动态分配计算资源。典型的架构设计中,系统会先由一个轻量级的"路由模型"(Router Model)判断用户请求的复杂度:简单的文本补全、格式化或基础问答由本地NPU上的小模型直接处理;涉及多步推理、跨文档综合或需要实时联网检索的复杂查询则转发至云端大模型。这种架构需要解决几个关键技术问题:本地与云端模型的上下文同步——确保云端模型能接续本地模型已处理的对话历史;无缝切换时的用户体验一致性——用户不应感知到本地与云端处理之间的割裂感;以及智能路由策略的准确性——错误的路由决策会导致简单问题被不必要地发送到云端(增加延迟和成本),或复杂问题被本地小模型勉强处理(降低回答质量)。业界目前探索的路由策略包括基于规则的静态路由、基于模型置信度的动态路由,以及使用强化学习训练的自适应路由器。
这种混合推理架构带来几个显著优势:
- 更低延迟:简单查询无需等待网络往返,本地即可完成响应。传统云端推理的网络延迟通常在100-500毫秒,而本地推理可将首token延迟降至10-50毫秒级别
- 隐私保护:敏感数据可以在本地处理,无需上传云端。这对企业用户处理机密文档、个人用户处理私密信息尤为重要
- 离线可用:即使没有网络连接,基础AI功能仍然可用,这在飞行模式或网络不稳定的场景下具有实际价值
- 降低成本:减少云端算力消耗,对用户和Perplexity双方都有利。云端大模型推理的GPU算力成本高昂,将部分请求分流到端侧可显著降低Perplexity的运营成本
Intel Core Ultra Series 3:为端侧AI提供算力支撑
Intel Core Ultra Series 3(代号Lunar Lake)是Intel专为AI PC时代打造的处理器平台,集成了强大的NPU,算力可达48 TOPS(每秒万亿次运算)。微软将40 TOPS定义为Copilot+ PC的最低门槛,这意味着Core Ultra Series 3已满足甚至超越了行业对AI PC的硬件要求。Lunar Lake采用了全新的架构设计,将内存直接封装在处理器封装内(Package-on-Package),减少了内存访问延迟,这对需要频繁读取模型权重的AI推理任务尤为有利。同时,其NPU采用了第四代Intel AI引擎,支持INT8和INT4精度推理,能够高效运行经过量化压缩的语言模型。这为在笔记本电脑端侧运行中小规模语言模型提供了坚实的硬件基础。
将大语言模型部署到端侧设备需要依赖一系列模型压缩技术。主流方法包括量化(Quantization)——将模型权重从FP32(32位浮点数)降低到INT8(8位整数)甚至INT4(4位整数)精度,可将模型体积缩小4-8倍且性能损失有限,这是目前端侧部署最广泛使用的技术;知识蒸馏(Knowledge Distillation)——用大模型(教师模型)的输出分布指导训练小模型(学生模型),使小模型能够"继承"大模型的部分能力,典型案例如Google的Gemma系列就大量使用了从Gemini蒸馏的知识;以及剪枝(Pruning)——通过分析网络权重的重要性,移除对输出影响较小的网络连接或整个注意力头,在保持模型性能的同时减少计算量。目前端侧设备通常可运行1B-7B参数规模的模型,如Microsoft Phi-3(3.8B参数)、Google Gemma 2B等专为端侧优化的模型。这些小模型通过精心的数据筛选、课程学习和针对性微调,在特定任务上已能达到接近大模型的效果,尤其在文本摘要、简单问答和代码补全等场景表现突出。
此前,Intel一直在大力推广"AI PC"概念,但市场上真正有说服力的端侧AI应用并不多。Intel在2023年底正式提出AI PC概念,将其定义为集成CPU、GPU和NPU三大计算引擎的个人电脑。这一战略的背景是Intel在数据中心AI芯片市场被NVIDIA大幅领先后——NVIDIA凭借其CUDA生态系统和H100/B200等GPU产品占据了数据中心AI训练和推理市场超过80%的份额——Intel转而聚焦PC端侧AI市场寻求差异化优势。Intel的逻辑是:虽然训练大模型需要数千张GPU的集群,但推理任务可以在更小的硬件上完成,而全球数十亿台PC构成了一个巨大的潜在推理算力池。Intel CEO Lip-Bu Tan于2025年3月正式上任,他此前是Cadence Design Systems的长期CEO(2009-2021年),将Cadence从一家陷入困境的EDA公司转型为市值超过800亿美元的行业领导者,以务实的工程管理风格和对半导体产业链的深刻理解著称。上任后,Lip-Bu Tan加速推进AI PC生态建设,积极寻求与头部AI应用厂商的合作,同时大刀阔斧地精简Intel内部组织架构以提升执行效率。
Perplexity作为目前增长最快的AI搜索产品之一,其加入无疑为Intel的AI PC生态注入了一剂强心针。对Intel而言,这不仅是一次产品层面的合作,更是证明其NPU实际应用价值的关键案例。长期以来,AI PC面临的最大质疑就是"NPU到底能干什么"——大多数用户购买笔记本电脑后,NPU几乎处于闲置状态。Perplexity这样的高频AI应用如果能有效利用NPU,将为整个AI PC生态树立标杆。
行业趋势:AI从云端走向终端
这次合作反映了AI行业一个重要趋势——从纯云端推理向端云混合推理转变。
过去两年,几乎所有主流AI应用都依赖云端大模型来完成推理任务。但随着端侧芯片算力的持续提升和模型压缩技术的进步,越来越多的AI能力开始"下沉"到终端设备。Apple Intelligence、高通骁龙X Elite上的Copilot+功能,以及Perplexity与Intel的这次合作,都在印证端侧AI这一方向的可行性。Apple在2024年WWDC上发布的Apple Intelligence采用了类似的混合架构:简单任务由设备端的Apple Silicon芯片处理,复杂任务通过"Private Cloud Compute"发送到Apple自建的云端服务器,且Apple强调即使在云端处理时也不会存储用户数据。高通则通过骁龙X Elite处理器的45 TOPS NPU算力,支持在Windows PC上运行本地AI模型。这场端侧AI的竞赛正在芯片厂商、操作系统厂商和AI应用厂商之间形成多方博弈的格局。
从更宏观的视角看,端云混合推理的兴起也与AI行业的经济模型密切相关。当前云端大模型推理的成本仍然高昂——以GPT-4级别模型为例,每百万输入token的成本在数美元量级,对于日活数百万的应用来说,这意味着每月数百万美元的推理成本。将部分推理负载转移到用户设备上,本质上是将计算成本从AI公司转移到了硬件制造商和终端用户(通过购买更强大的设备),这种成本结构的重新分配可能从根本上改变AI应用的商业模式。
对于Perplexity来说,这也是一次战略性的平台扩展。从纯粹的网页和移动端AI搜索工具,延伸到PC端的深度集成,意味着Perplexity正在尝试成为用户日常计算体验中不可或缺的一部分——而不仅仅是浏览器中的一个标签页。这种深度系统集成的策略类似于当年Google将搜索框嵌入Chrome浏览器地址栏的做法,通过减少用户触达AI能力的摩擦,提升使用频率和用户粘性。
值得关注的后续问题
目前这一合作的具体落地形式尚未完全披露,以下几个问题值得持续关注:
- 本地模型的能力边界:哪些功能可以完全在本地完成?本地模型的规模和精度如何?考虑到48 TOPS的NPU算力和笔记本有限的内存带宽,本地模型大概率在3B-7B参数范围内,这决定了其能力上限
- 用户体验差异:与纯云端版本相比,混合推理模式下的响应质量是否存在差异?本地小模型在复杂推理和事实准确性方面与云端大模型仍有明显差距,如何管理用户预期是关键
- 是否为Intel独占:这一功能未来是否会扩展到AMD、高通等其他芯片平台?AMD的Ryzen AI系列同样集成了强大的NPU(最高可达50 TOPS),高通骁龙X Elite也具备45 TOPS算力,从Perplexity的商业利益角度看,多平台支持是更合理的长期策略
- 预装还是后装:Perplexity是否会预装在搭载Intel Core Ultra Series 3的笔记本上,还是需要用户自行下载安装?预装意味着更深层的商业合作和收入分成安排,也意味着Perplexity能获得更大的用户触达面
无论如何,Perplexity与Intel的合作为AI PC的落地提供了一个具体而有吸引力的应用场景,也让"端侧AI"这个概念离普通用户更近了一步。
相关推荐
Codex搭建冷链物流优化科研项目:从零到PDF论文全流程实战
详解如何用OpenAI Codex从空文件夹开始,完成冷链物流模拟退火算法建模、Python实现、实验设计、科研绘图到LaTeX论文编译的完整科研项目流程,附分阶段提示词设计方法论。
Codex入门实战指南:一个周末掌握AI编程核心技能
OpenAI Codex入门实战指南,涵盖环境搭建、代码生成、Bug修复、项目重构等核心场景。适合学生、开发者及编程爱好者,附高效学习建议与Prompt技巧,助你快速上手AI编程。
AI Agent智能体系统学习路径:从零基础到独立开发
系统梳理AI Agent智能体的完整学习路径,涵盖基础原理、Prompt工程、RAG知识库、多Agent协作等核心技术,附带实战项目指南,帮助零基础学习者高效掌握Agent开发能力。