Pixel Video:三分钟出片的开源短视频自动化生产工具
开源项目Pixel Video实现短视频全链路自动化,三分钟从主题到成片。
Pixel Video是一个GitHub上获得1.5万Star的开源项目,能将短视频制作从输入主题到输出成片压缩至三分钟。它自动完成文案撰写、AI配图生成、语音合成、BGM匹配和视频合成全流程,支持GPT、DeepSeek等多种LLM和可替换TTS引擎,并集成ComfyUI工作流,适合自媒体矩阵批量生产和知识类内容创作。
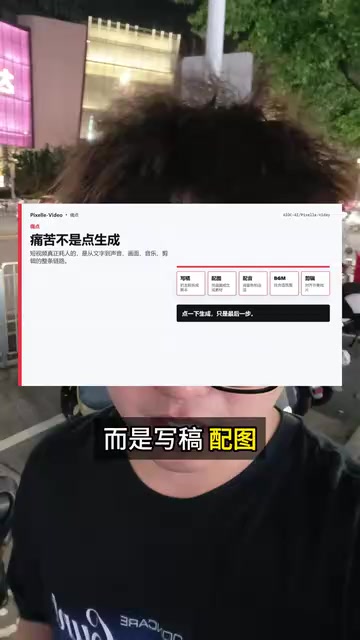
短视频创作的痛点
做短视频最痛苦的环节从来不是点击"生成"按钮,而是前期漫长的准备工作——写文案、配图、录音、找BGM、最后还要剪辑合成。这条完整的制作链路往往需要数小时甚至数天,对于个人创作者和小团队来说是巨大的时间成本。
短视频制作看似简单,实际涉及内容策划、视觉设计、音频处理和后期合成四大环节。传统工作流中,创作者需要在多个工具间切换——用文档工具写脚本、用Midjourney或Stable Diffusion生成配图、用剪映或Premiere进行剪辑、再从音乐库中筛选BGM。每个环节都有学习成本和时间消耗,尤其对于日更或多平台分发的创作者而言,单条视频2-4小时的制作周期严重制约了产出效率。这也是为什么"全链路自动化"成为AI视频工具竞争的核心赛道。
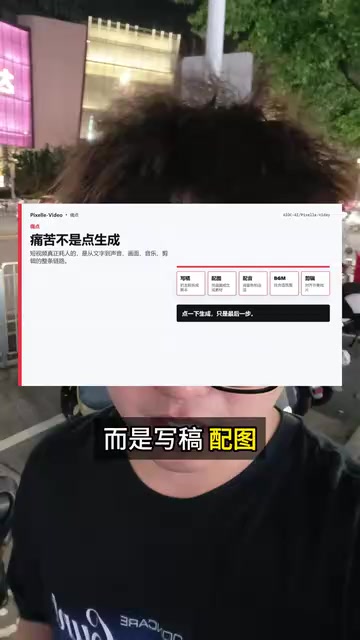
现在,一个名为 Pixel Video 的开源项目正在尝试彻底打通这条链路,将短视频制作压缩到三分钟以内。该项目在GitHub上已经狂揽1.5万Star,热度持续攀升。
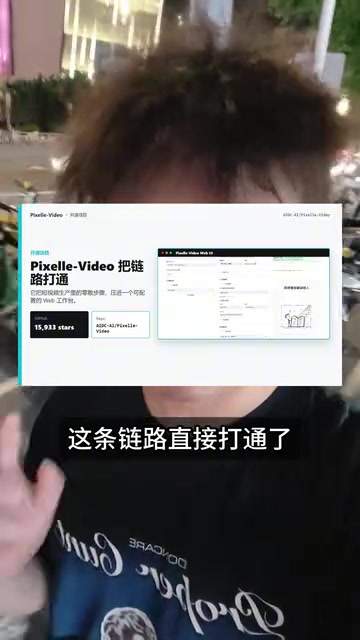
Pixel Video 核心功能:全链路自动化生产
Pixel Video 的核心能力是将短视频制作的完整流程自动化。你只需要输入一个主题,它就会依次完成以下步骤:
- 自动撰写视频文案 —— 根据主题生成结构化的脚本
- 生成AI配图或视频片段 —— 为每个段落匹配视觉素材
- 合成语音解说 —— 将文案转化为自然的配音
- 添加背景音乐 —— 自动匹配风格合适的BGM
- 最终合成成片 —— 输出可直接发布的完整视频
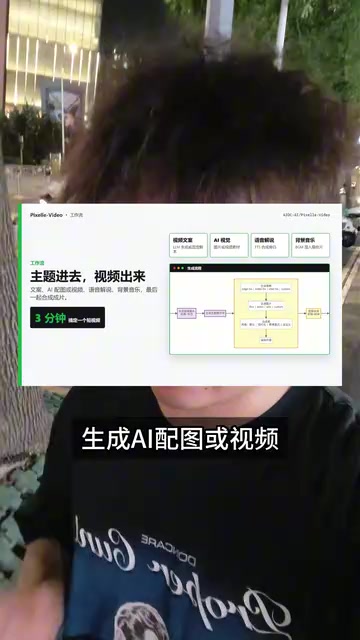
整个过程从输入主题到输出成品,仅需约三分钟。对于需要批量生产内容的创作者来说,这意味着效率的数量级提升。
开放架构设计:高度可定制的模块化系统
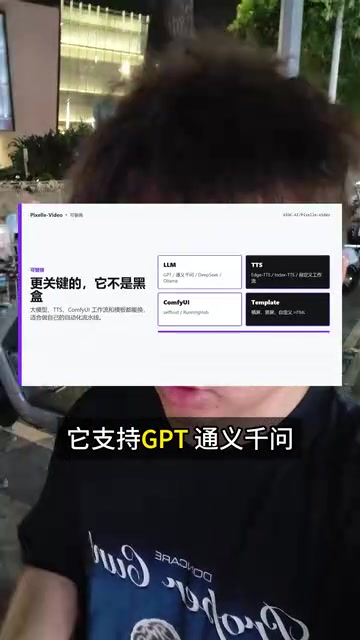
Pixel Video 最值得关注的特点在于它的开放性。与许多封闭的AI视频工具不同,它不是一个黑盒系统,而是提供了高度可定制的架构:
- 多LLM支持:兼容GPT、通义千问、DeepSeek、Ollama等多种大语言模型
- 可替换TTS引擎:语音合成模块支持更换不同的TTS服务
- ComfyUI工作流集成:可以接入ComfyUI的图像/视频生成工作流
- 模板系统:支持自定义视频模板,适配不同风格需求
大语言模型(LLM)的多样化选择
大语言模型(Large Language Model)是基于Transformer架构训练的生成式AI模型,能够理解和生成自然语言文本。在视频制作场景中,LLM负责将用户输入的简短主题扩展为结构化的视频脚本,包括开头hook、正文段落划分、转场提示和结尾总结。GPT-4o、通义千问(阿里云)、DeepSeek等模型各有特点:GPT系列在英文创意写作上表现突出,通义千问对中文语境理解更深,DeepSeek则以高性价比著称。Ollama则是一个本地运行开源模型的框架,支持Llama、Mistral等模型的私有化部署,适合对数据隐私有要求或希望降低API调用成本的用户。
TTS语音合成的技术支撑
TTS(Text-to-Speech)技术经历了从拼接合成、参数合成到神经网络合成的三代演进。早期的TTS声音机械感明显,而当前主流的神经网络TTS(如微软Azure Speech、OpenAI TTS、Fish Speech、ChatTTS等)已能生成接近真人的自然语音,支持情感控制、语速调节和多音色切换。在短视频场景中,TTS的质量直接影响观众的观看体验——过于机械的声音会导致完播率下降。Pixel Video支持替换TTS引擎的设计,让用户可以根据内容类型选择最合适的语音风格。
ComfyUI工作流的深度集成
ComfyUI是一个基于节点的图像/视频生成工作流编辑器,在AI绘画社区中广受欢迎。与传统的WebUI不同,ComfyUI将Stable Diffusion的每个处理步骤(如加载模型、设置采样器、添加ControlNet、后处理等)拆解为可视化节点,用户可以通过连线自由组合出复杂的生成流程。Pixel Video接入ComfyUI意味着用户可以利用已有的图像生成工作流——比如特定风格的插画生成、AI视频片段生成(通过AnimateDiff或SVD等模型)——直接作为视频素材的生产管线,实现视觉风格的高度定制化。
这种模块化设计意味着用户可以根据自己的需求和预算,灵活选择每个环节使用的AI模型和服务。想用本地部署的开源模型降低成本?可以。想用最强的商业API追求质量?同样没问题。
适用场景与价值分析
谁最需要Pixel Video?
- 自媒体矩阵运营者:需要批量生产内容的团队,可以用它搭建自动化短视频流水线
- 知识类内容创作者:科普、资讯、教程类视频的制作效率将大幅提升
- 独立开发者/技术爱好者:开源特性使其成为二次开发和学习AI工作流的优质项目
自媒体矩阵与自动化流水线的实践逻辑
自媒体矩阵运营是指同时运营多个账号或多个平台(抖音、快手、视频号、B站等),通过内容差异化和规模化分发来最大化流量获取。这种模式下,单个运营者可能需要每天产出10-50条短视频,传统人工制作方式完全无法支撑。自动化流水线的核心价值在于将"创意决策"与"执行生产"分离——人类负责选题方向和质量把控,AI负责批量执行文案撰写、素材生成和视频合成。Pixel Video的全链路自动化能力恰好匹配了这一需求场景。
局限性思考
全自动化生产的视频在创意深度和个性化表达上,目前仍难以与精心制作的人工作品相比。AI生成的文案可能缺乏独特视角,配图与内容的匹配度也需要人工审核。Pixel Video 更适合作为效率工具辅助创作,而非完全替代人类创作者的判断力。
总结
Pixel Video 代表了AI视频工具的一个重要方向:不是做单点突破,而是打通从构思到成片的完整链路。它的开源特性和模块化架构,让它不仅是一个工具,更是一个可以持续演进的平台。对于想要探索AI短视频自动化生产的开发者和创作者来说,这个项目值得深入研究。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。