pnpm Monorepo全栈AI工程化实战:搭建多模态对话系统
基于pnpm Monorepo搭建支持多模态交互的本地AI对话系统全栈架构方案
本文解析了一套pnpm Monorepo全栈AI工程化架构,将现代前端工程化管理与本地AI模型推理相结合。项目实现了流式文本对话和多模态图片理解功能,通过抽象推理层支持多引擎灵活切换,提示词可配置化设计,数据完全本地处理保障隐私安全,是全栈开发者落地AI能力的优秀参考方案。
前言:为什么这套架构值得学习
在AI工程化快速发展的背景下,如何构建一套高效、可维护的全栈AI项目架构,成为许多开发者关注的焦点。本文基于B站UP主分享的pnpm Monorepo全栈AI工程化实战内容,详细解析如何利用现代前端工程化工具链,搭建一个支持多模态交互的本地AI对话系统。
这套架构的核心价值在于:将pnpm Monorepo的工程化管理能力与本地AI模型推理相结合,实现了一个既具备工程化最佳实践,又能落地AI应用的完整方案。
项目效果展示
文本对话功能
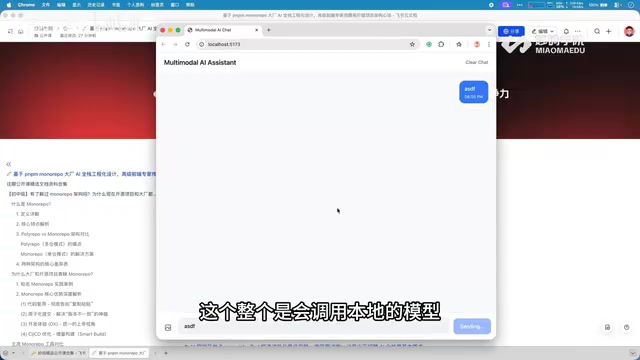
项目的第一个核心功能是基于本地模型的文本对话系统。用户发送消息后,系统调用本地部署的AI模型进行推理,并以流式方式返回回复内容。整个消息的发送与同步过程流畅自然,体验接近商用级别的对话产品。
流式响应(Streaming Response)是现代AI对话系统的标配技术,其底层通常基于Server-Sent Events(SSE)或WebSocket协议实现。与传统的请求-响应模式不同,流式传输允许服务端在生成内容的同时逐步推送给客户端,用户无需等待完整回复生成即可看到逐字输出的效果。这种技术在大语言模型推理场景中尤为重要,因为模型生成一个完整回复可能需要数秒甚至更长时间,流式输出可以将用户感知的首字延迟从数秒降低到毫秒级别。
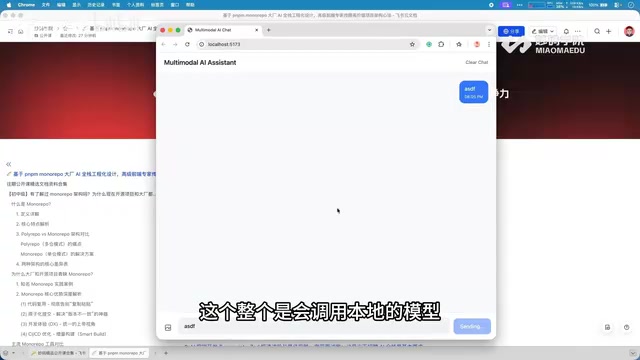
你可能没注意到,由于采用本地模型推理,所有数据处理都在本地完成,无需依赖外部API服务,这在数据隐私和离线使用场景下具有明显优势。本地模型推理是指将AI模型部署在用户自己的设备上运行,而非调用云端API。常见的本地推理框架包括Ollama、llama.cpp、vLLM等,它们通过模型量化(如GGUF格式的4-bit/8-bit量化)技术,使得原本需要数十GB显存的大模型可以在消费级GPU甚至CPU上运行。这种方案不仅消除了数据泄露风险,还免去了API调用费用,长期使用成本更低。
多模态图片理解
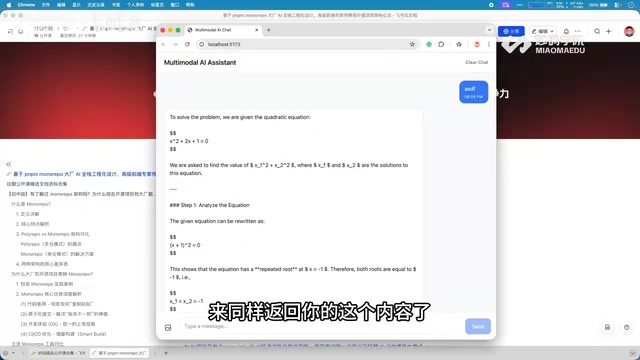
项目的第二个亮点是多模态能力的集成。用户不仅可以发送文本消息,还可以上传图片,系统能够对图片内容进行智能分析和理解。具体能力包括:
- 图片内容识别:分析图片中包含的物体、场景等视觉信息
- 文字提取(OCR):识别并提取图片中的文字内容
- 图文结合问答:基于上传的图片回答用户的相关问题
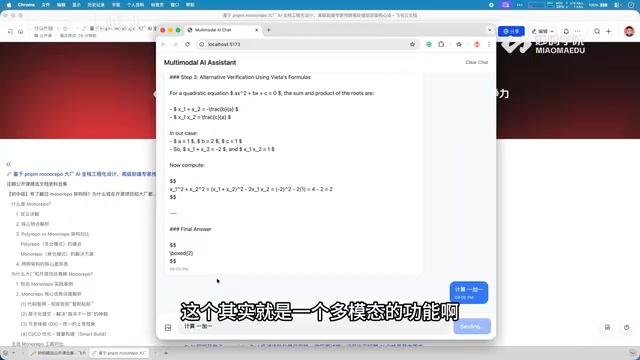
例如,用户可以上传一张包含数学公式的图片,然后询问"帮我计算1加1",系统会结合图片上下文给出准确回答。这种多模态交互方式大大扩展了对话系统的应用场景。
多模态AI模型是指能够同时处理和理解多种数据类型(如文本、图像、音频、视频)的模型。LLaVA(Large Language and Vision Assistant)是该领域的代表性开源项目,它通过视觉编码器(通常基于CLIP的ViT架构)将图像转换为视觉token,再与文本token一起输入大语言模型进行联合推理。类似的开源多模态模型还包括MiniCPM-V、InternVL、Qwen-VL等。这些模型的本地部署通常需要比纯文本模型更多的计算资源,因为视觉编码器本身也需要占用额外的显存和算力。
技术架构解析
pnpm Monorepo的工程化优势
pnpm Monorepo架构在本项目中发挥了关键作用。相比传统的单仓库或多仓库方案,Monorepo带来了以下优势:
- 依赖管理统一:前端、后端、共享工具库的依赖统一管理,避免版本冲突
- 代码复用高效:公共类型定义、工具函数可跨包共享
- 构建流程一体化:一条命令即可完成全栈项目的构建和部署
- 开发体验流畅:修改共享包后,依赖方自动热更新
pnpm(Performant npm)是一种高性能的Node.js包管理器,其核心创新在于使用硬链接和符号链接机制来共享依赖,相比npm和yarn可节省大量磁盘空间并显著提升安装速度。Monorepo(Monolithic Repository)是一种将多个相关项目放在同一个代码仓库中管理的策略,Google、Meta等科技巨头长期采用这种模式。pnpm的workspace功能天然支持Monorepo,通过pnpm-workspace.yaml配置文件定义包的目录结构,结合其严格的依赖隔离机制(不会像npm那样产生幽灵依赖问题),使其成为目前前端Monorepo方案中的首选工具。与之类似的方案还有Turborepo、Nx等构建编排工具,它们可以与pnpm workspace配合使用,提供任务缓存、增量构建等高级能力。
本地模型集成方案
项目通过调用本地部署的AI模型来实现推理能力。从演示效果来看,模型支持英文回复(可通过调整提示词切换为中文),并且具备多模态理解能力,说明底层可能集成了类似LLaVA或其他支持视觉理解的开源模型。
在具体实现层面,本地模型的集成通常遵循以下技术路径:首先通过Ollama等工具将量化后的模型文件加载到本地,然后启动一个兼容OpenAI API格式的本地HTTP服务,最后由应用后端通过标准的HTTP请求与模型服务通信。这种设计使得前端代码无需关心模型的具体部署方式,只需对接统一的API接口即可。模型的选择也非常灵活,从轻量级的Phi-3、Gemma到重量级的Llama 3、Qwen2.5都可以根据硬件条件自由切换。
实践要点与心得
提示词工程的灵活性
从演示中可以看到,模型默认以英文方式回复。作者提到可以通过修改提示词来调整回复语言和风格,这体现了提示词工程在实际应用中的重要性。一个好的系统应该将提示词设计为可配置项,方便根据不同场景快速调整。
提示词工程(Prompt Engineering)已经发展为AI应用开发中的一门核心技能。在工程化实践中,提示词通常不应硬编码在业务逻辑中,而是作为独立的配置资源进行管理。常见的做法包括:使用模板引擎支持变量插值、建立提示词版本管理机制、设置A/B测试框架来对比不同提示词的效果。系统提示词(System Prompt)定义了模型的角色和行为边界,用户提示词(User Prompt)则承载具体的任务指令,两者的合理分层设计是构建高质量AI应用的关键。
多引擎架构设计
作者提到项目包含多个引擎案例,这暗示了架构设计中的一个重要原则:抽象AI推理层。通过定义统一的接口规范,可以灵活切换不同的AI引擎(如本地模型、云端API等),而上层业务逻辑无需改动。
这种抽象推理层的设计模式,其核心思想是在业务逻辑与具体AI引擎之间建立一个统一的接口层,类似于设计模式中的适配器模式或策略模式。在实际工程中,这通常表现为定义一套标准的接口协议(如chat、completion、embedding等方法),然后为不同的AI后端(Ollama、OpenAI API、Azure、Anthropic、本地ONNX模型等)分别实现适配器。这种设计使得系统可以在不修改上层代码的情况下,通过配置切换底层AI引擎,极大提升了系统的可维护性和扩展性。业界知名的LangChain、Vercel AI SDK、LiteLLM等框架都采用了类似的抽象设计理念,开发者可以参考这些框架的接口设计来构建自己的推理抽象层。
总结
这套pnpm Monorepo + 本地AI模型的全栈架构方案,将现代前端工程化的最佳实践与AI应用开发有机结合。对于希望在实际项目中落地AI能力的全栈开发者而言,这是一个非常值得参考的技术方案。掌握这类架构能力,不仅能提升个人技术深度,也能在求职市场中获得更强的竞争力。
从更宏观的视角来看,这套架构代表了AI应用开发的一个重要趋势:将AI能力从云端下沉到边缘和本地设备。随着模型量化技术的进步和消费级硬件算力的提升,本地AI推理的可行性和实用性正在快速提高。结合Monorepo的工程化管理能力,开发者可以高效地构建、迭代和维护复杂的AI应用系统,这正是未来全栈AI工程师的核心竞争力所在。
核心要点
- 采用pnpm Monorepo架构实现全栈AI项目的工程化管理,统一依赖和构建流程
- 集成本地AI模型实现文本对话功能,数据处理完全在本地完成,保障隐私安全
- 支持多模态交互,用户可上传图片进行内容识别、文字提取和图文问答
- 架构设计支持多引擎切换,通过抽象推理层实现灵活的AI能力接入
- 提示词可配置化设计,支持快速调整回复语言和风格
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。