iNaturalist AI物种识别实战:PyCon开发者的洛杉矶河观鸟记录
一位Python开发者的观鸟记录揭示公民科学、AI物种识别与城市生态修复的深度融合。
一位Python开发者在PyCon大会后于洛杉矶河畔观鸟,记录了四种水鸟并上传至iNaturalist平台。文章以此为切入点,深入探讨了iNaturalist如何通过"众包标注+AI训练"闭环实现物种识别,洛杉矶河生态修复的成效,以及Python社区与公民科学的天然联系,展现了个人观察如何转化为具有科学价值的生物多样性数据。
从PyCon到洛杉矶河:一位开发者的观鸟记录
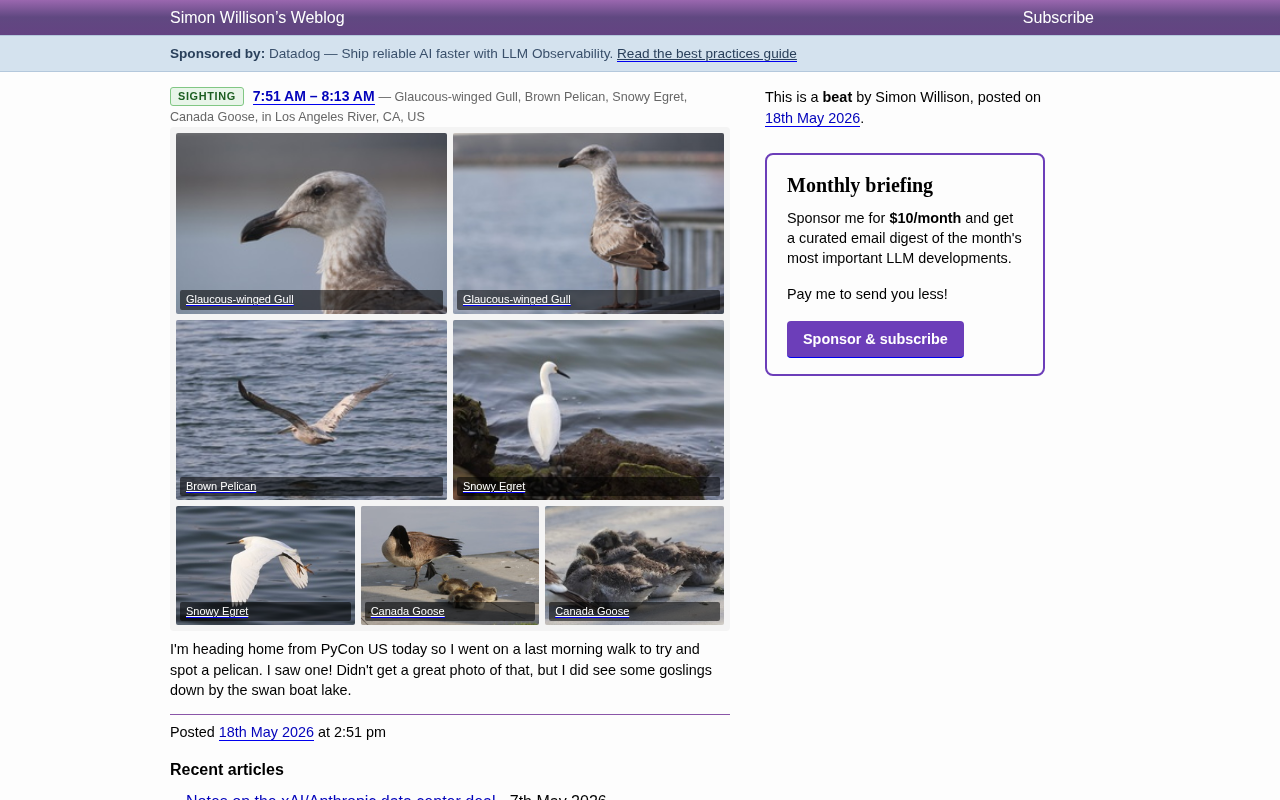
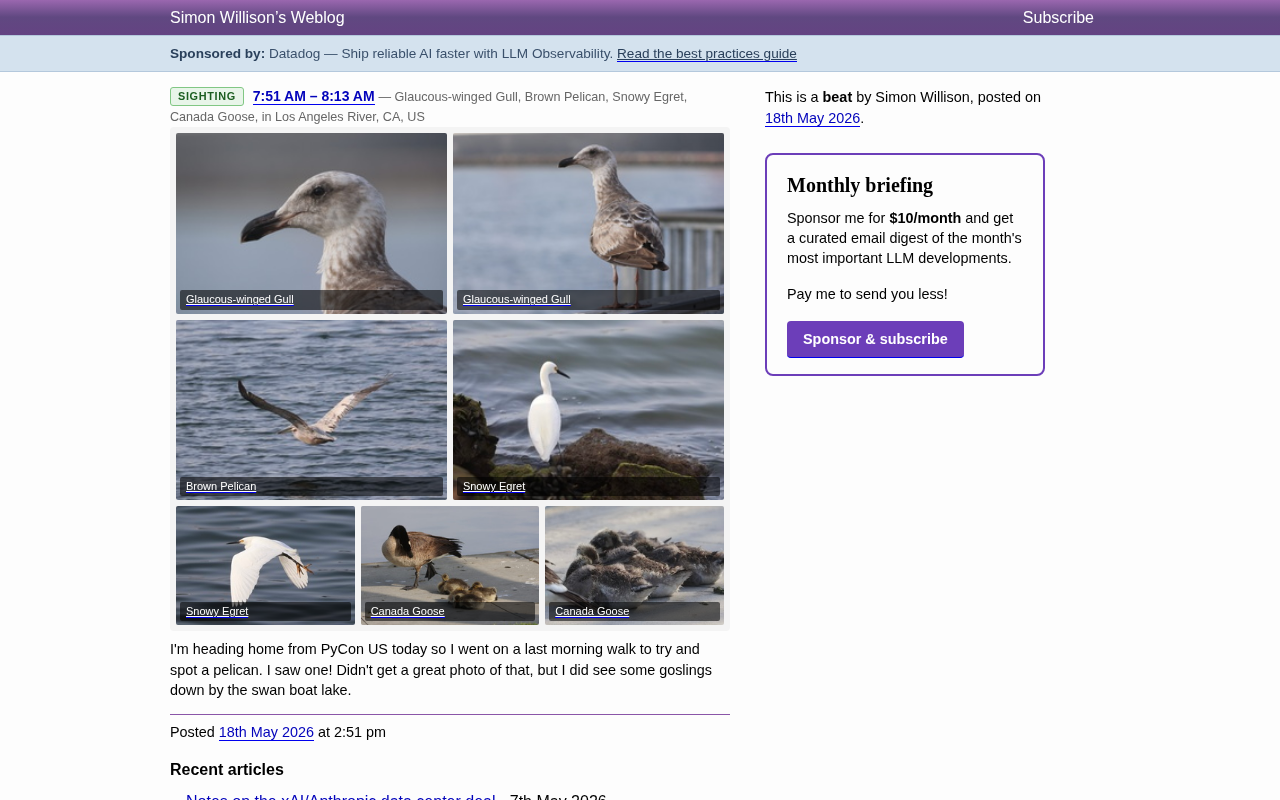
一位Python开发者在参加完PyCon US大会后,利用返程前的最后一个清晨,在洛杉矶河畔进行了一次观鸟散步。这次短暂的自然观察中,他记录到了四种北美常见水鸟——灰翅鸥(Glaucous-winged Gull)、褐鹈鹕(Brown Pelican)、雪鹭(Snowy Egret)和加拿大雁(Canada Goose)。
这条看似简单的观鸟记录,实际上折射出一个值得关注的交叉领域:自然观察与AI物种识别技术的深度融合。这些观察数据来自iNaturalist平台,而该平台正是AI辅助生物多样性研究的标杆案例。
iNaturalist平台:公民科学与AI识别如何协同工作
平台背景与规模
iNaturalist是全球最大的公民科学平台之一,由加州科学院和国家地理学会联合运营。用户上传野生动植物照片后,平台内置的计算机视觉模型会自动给出物种识别建议,再由社区专家进行验证。
截至目前,iNaturalist已积累超过1.5亿条观察记录,覆盖超过40万个物种。这些经过社区验证的数据,已成为生态学研究和生物多样性监测不可或缺的数据源。
值得注意的是,iNaturalist采用多层次的数据质量控制体系:单条观察记录需获得至少两位独立用户的物种认同,且同意比例超过三分之二,才能晋升为「研究级」(Research Grade)数据,进而被GBIF(全球生物多样性信息网络)等科学数据库收录。这套社区驱动的验证机制有效平衡了数据采集规模与科学可靠性之间的张力,使得平台数据能够真正进入同行评审的学术研究流程。
AI物种识别的技术原理
iNaturalist的物种识别模型基于深度学习的图像分类技术,训练数据正是平台上数以亿计的用户上传照片。在技术架构上,该识别引擎经历了从早期InceptionV3到EfficientNet等更高效架构的持续迭代。尤为值得关注的是,模型的推断逻辑并非单纯依赖视觉特征,还融合了地理位置先验信息——即某个物种在特定地区出现的历史概率。这种「视觉特征+地理概率」的联合推断机制,显著提升了在复杂场景下的识别准确率,也解释了为何同一张照片在不同地理位置上传时可能得到不同的识别建议。
这种「众包标注+AI训练」的闭环模式,使得模型在不断迭代中持续提升识别准确率。对于本次记录中的四种鸟类,AI识别的置信度通常可以达到较高水平,因为它们都是北美地区的常见物种,训练样本充足。这也揭示了AI物种识别的一个关键规律:常见物种的识别精度远高于稀有物种,数据量直接决定了模型表现。
四种鸟类的生态观察价值
洛杉矶河:从水泥渠到野生动物栖息地
你可能没注意到,这四种鸟类都是在洛杉矶河(Los Angeles River)中被观察到的。洛杉矶河全长约82公里,20世纪30年代为防洪而被大规模混凝土渠化,几乎彻底丧失了自然生态功能——河道两岸被浇筑成整齐的梯形水泥槽,成为好莱坞电影中追车场景的标志性取景地,却与真正的河流生态系统相去甚远。
转机出现在2007年,美国陆军工程兵团将其列为可恢复的生态系统,此后联邦、州和市政府累计投入超过10亿美元推进修复计划。目前已有部分河段恢复了天然河床和植被缓冲带,成为城市野生动物的重要生态廊道。这位开发者的观察,恰好发生在这一生态复苏进程的当下。
每种鸟类传递的生态信号
- 灰翅鸥:主要分布在北美太平洋沿岸,出现在内陆河道说明该区域与海洋生态存在连通性
- 褐鹈鹕:曾因DDT污染一度濒危,如今种群恢复良好,是环境改善的标志性物种。褐鹈鹕的故事是20世纪最著名的环境污染案例之一——DDT通过食物链富集后导致蛋壳异常变薄,繁殖率急剧下降;1970年代美国禁用DDT后种群逐步恢复,并于2009年从濒危物种名单中移除,成为《濒危物种法》有效性的标志性证明
- 雪鹭:对水质敏感的涉禽,其存在表明洛杉矶河的水质达到了一定标准
- 加拿大雁:适应性极强的物种,作者还观察到了雏鸟(goslings),说明该区域已成为繁殖栖息地
这些数据点虽然看似零散,但汇聚到iNaturalist平台后,就构成了城市生态监测的宝贵时空数据集。
Python技术社区与公民科学的天然联系
为什么PyCon参会者热衷观鸟
这并非个例。Python社区与公民科学之间存在天然的亲和力。Python是生态学数据分析的主流语言,在这一领域已形成完整的工具链:pyinaturalist和PyGBIF库提供数据获取接口;GeoPandas和Shapely处理物种分布的地理空间数据;MaxEnt算法的Python实现用于物种分布建模(SDM);而TensorFlow和PyTorch则支撑着自定义物种识别模型的训练。这一生态系统使得从原始观察数据到发表级分析结果的全流程都可在Python环境中完成,极大降低了生态学研究的技术门槛。
许多开发者本身就是自然爱好者,他们既是数据的生产者,也是分析工具的构建者。iNaturalist本身也提供了完善的API接口,开发者可以方便地获取观察数据进行二次分析。这种开放数据的理念,与开源社区的精神一脉相承。
从个人观鸟记录到科学研究数据
这位开发者的晨间散步,看似只是一次休闲活动,但当观察记录被上传到iNaturalist并经过社区验证后,它就转化为具有科学价值的数据点——包含精确的时间戳、地理坐标和物种信息。这正是公民科学的核心价值:每一次个人观察,都在为全球生物多样性数据库添砖加瓦。
AI在生物多样性监测领域的发展方向
随着多模态大模型的发展,物种识别正在从单纯的图像分类向更复杂的场景理解演进。未来的AI系统不仅能识别物种,还有望分析行为模式、评估种群健康状况,甚至预测物种分布的变化趋势。当前已有研究团队尝试将声纹识别(用于鸟鸣分析)、eDNA(环境DNA)检测与传统图像识别相结合,构建多模态的生物多样性感知系统。
对于像洛杉矶河这样的城市生态修复项目,持续的公民科学监测数据结合AI分析能力,将为城市规划者提供更科学的决策依据。而这一切的起点,可能就是一位开发者在会议间隙的一次清晨散步。
核心要点
- iNaturalist平台利用AI计算机视觉模型辅助物种识别,已积累超过1.5亿条观察记录,并通过「研究级」验证机制确保数据科学可靠性
- 洛杉矶河观察到的四种水鸟反映了城市生态修复的成效,褐鹈鹕的出现尤其具有环境史意义
- Python社区与公民科学存在天然交集,完整的Python生态学工具链使开发者既是数据生产者也是分析工具构建者
- 公民科学的众包标注模式为AI训练提供了海量数据,形成了数据采集与模型优化的正向循环
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。